更新Hbase的文章的排版
This commit is contained in:
@@ -15,7 +15,7 @@
|
||||
|
||||
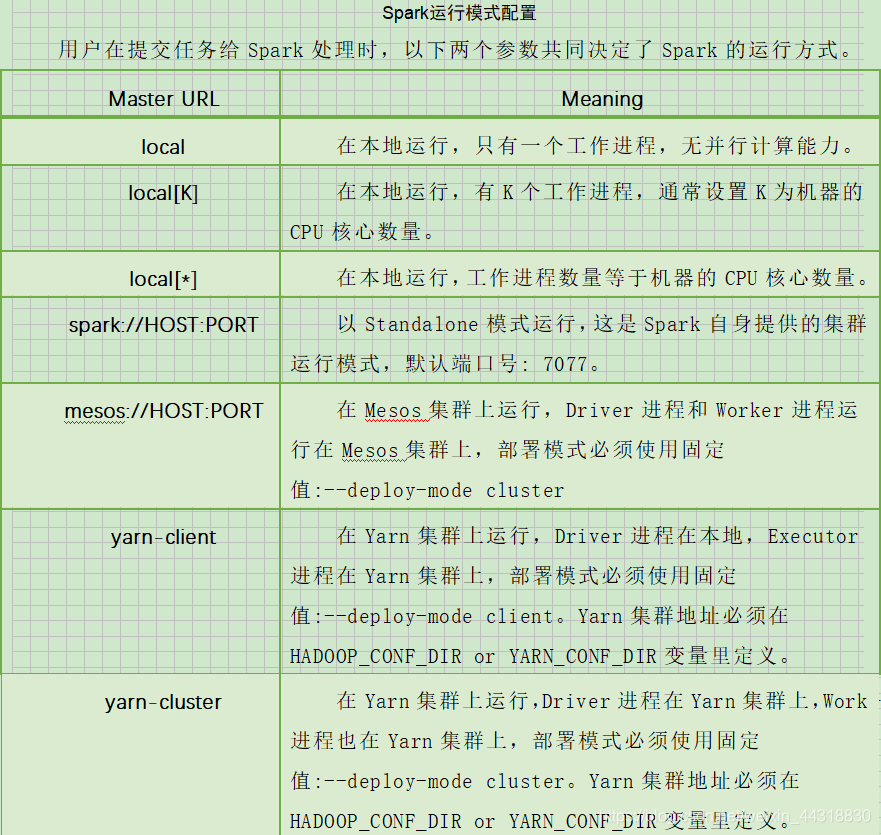
Spark的运行模式取决于传递给SparkContext的==MASTER==环境变量的值,个别模式还需要辅助的程序接口来配合使用,目前支持的Master字符串及URL包括:
|
||||
|
||||
|
||||

|
||||
|
||||
- – master MASTER_URL :决定了Spark任务提交给哪种集群处理。
|
||||
|
||||
@@ -60,15 +60,26 @@ spark-submit \
|
||||
**YARN Client模式**
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
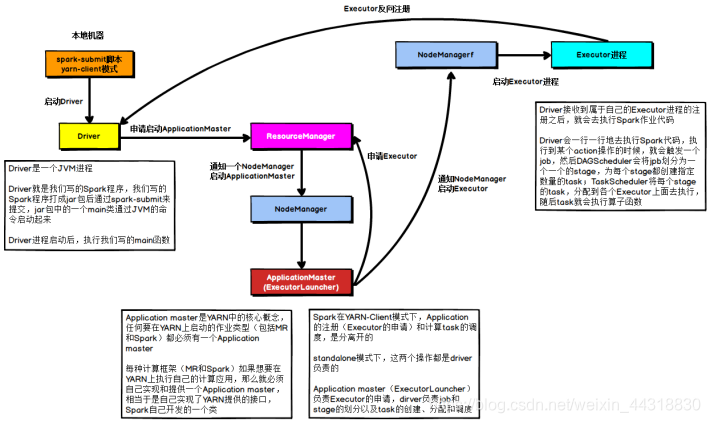
在YARN Client模式下,Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
|
||||
|
||||
|
||||
|
||||
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
|
||||
|
||||
|
||||
|
||||
**YARN Cluster模式**
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
|
||||
|
||||
@@ -96,6 +107,7 @@ spark-submit \
|
||||
7)foreach:
|
||||
8)saveAsTextFile:
|
||||
|
||||
|
||||
***
|
||||
## 6、简述Spark的两种核心Shuffle(重点)
|
||||
**spark的Shuffle有Hash Shuffle和Sort Shuffle两种。**
|
||||
@@ -106,12 +118,18 @@ spark-submit \
|
||||
|
||||
<font color=' RoyalBlue'>**SortShuffleManager**</font>相较于HashShuffleManager来说,有了一定的改进。主要就在于,<font color='RoyalBlue'>**每个Task在进行shuffle操作时**</font>,虽然也会产生较多的临时磁盘文件,但是最后会<font color='RoyalBlue'>**将所有的临时文件合并(merge)成一个磁盘文件**</font>,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
|
||||
|
||||
|
||||
|
||||
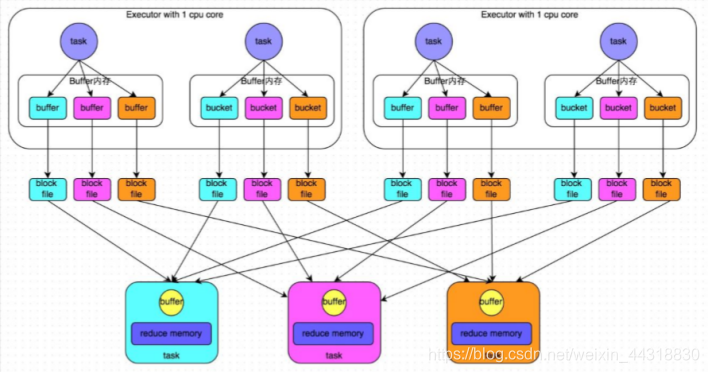
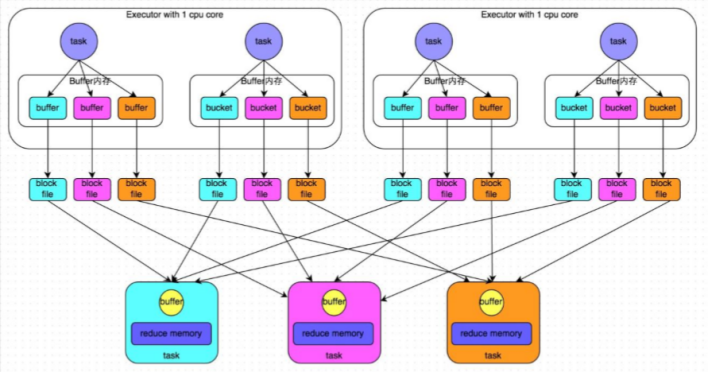
**未经优化的HashShuffle:**
|
||||
|
||||
|
||||
|
||||
|
||||
上游的stage的task对相同的key执行hash算法,从而将相同的key都写入到一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入到内存缓冲,当内存缓冲填满之后,才会溢写到磁盘文件中。但是这种策略的不足在于,下游有几个task,上游的每一个task都就都需要创建几个临时文件,每个文件中只存储key取hash之后相同的数据,导致了当下游的task任务过多的时候,上游会堆积大量的小文件。
|
||||
|
||||
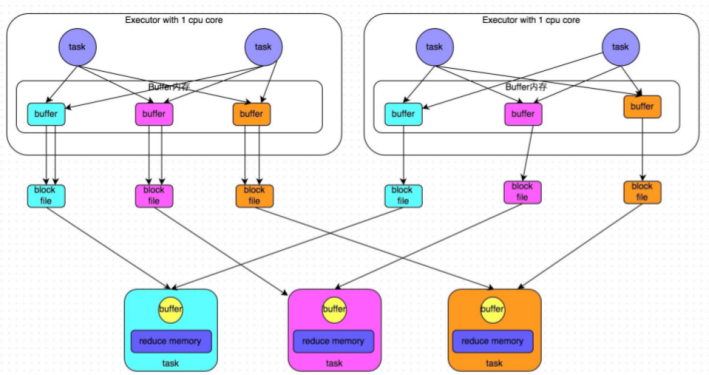
**优化后的HashShuffle:**
|
||||

|
||||
|
||||
|
||||
|
||||
在shuffle write过程中,上游stage的task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
|
||||
|
||||
注意:如果想使用优化之后的ShuffleManager,需要将:`spark.shuffle.consolidateFiles`调整为`true`。(当然,默认是开启的)
|
||||
@@ -130,10 +148,14 @@ spark-submit \
|
||||
> 上游的executor数量:k (m>=k) ,
|
||||
> 总共的磁盘文件: k*n</font>
|
||||
|
||||
|
||||
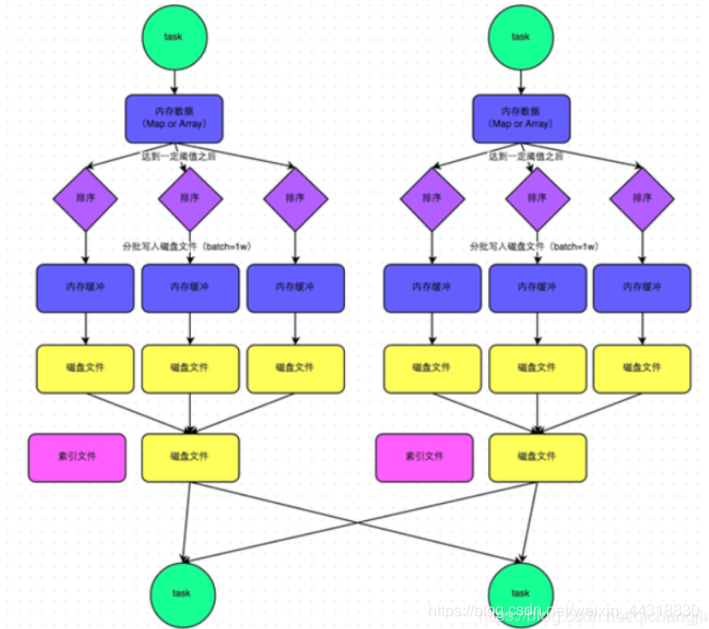
**普通的SortShuffle:**
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
在普通模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可以选用不同的数据结构。如果是由聚合操作的shuffle算子,就是用map的数据结构(边聚合边写入内存),如果是join的算子,就使用array的数据结构(直接写入内存)。接着,每写一条数据进入内存数据结构之后,就会判断是否达到了某个临界值,如果达到了临界值的话,就会尝试的将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
|
||||
|
||||
|
||||
@@ -143,14 +165,14 @@ spark-submit \
|
||||
此时task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写,会产生多个临时文件,最后会将之前所有的临时文件都进行合并,最后会合并成为一个大文件。最终只剩下两个文件,一个是合并之后的数据文件,一个是索引文件(标识了下游各个task的数据在文件中的start offset与end offset)。最终再由下游的task根据索引文件读取相应的数据文件。
|
||||
|
||||
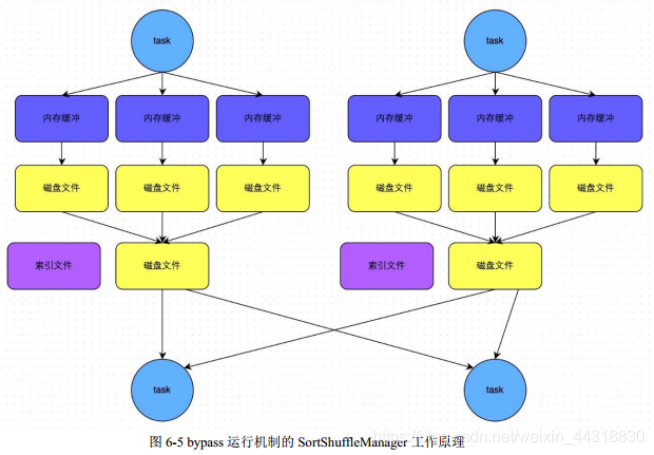
**SortShuffle - bypass运行机制 :**
|
||||
|
||||

|
||||
|
||||
此时上游stage的task会为每个下游stage的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
|
||||
|
||||
自己的理解:bypass的就是不排序,还是用hash去为key分磁盘文件,分完之后再合并,形成一个索引文件和一个合并后的key hash文件。省掉了排序的性能。
|
||||
|
||||
bypass机制与普通SortShuffleManager运行机制的不同在于:
|
||||
|
||||
|
||||
a、磁盘写机制不同;
|
||||
b、不会进行排序。
|
||||
|
||||
@@ -206,8 +228,16 @@ spark-submit \
|
||||
|
||||
DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。
|
||||
|
||||
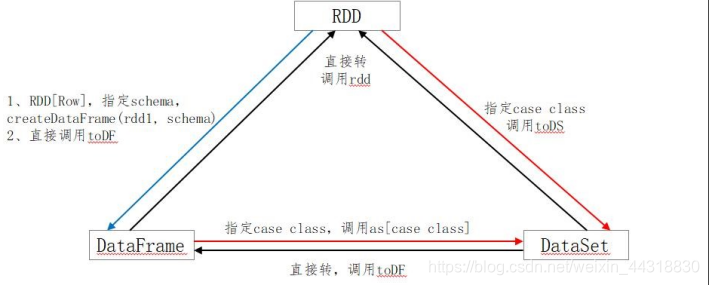
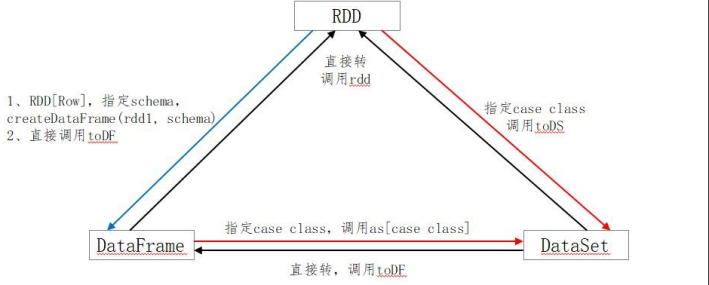
<font color='LightSeaGreen'>**三者之间的转换:**</font>
|
||||
|
||||
<font color='LightSeaGreen'>**三者之间的转换:**
|
||||
|
||||
</font>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
## 8、Repartition和Coalesce关系与区别(重点)
|
||||
@@ -228,7 +258,7 @@ spark-submit \
|
||||
`DataFrame`的`cache`默认采用 `MEMORY_AND_DISK` 这和RDD 的默认方式不一样==RDD== ==cache== 默认采用==MEMORY_ONLY==
|
||||
|
||||
|
||||

|
||||

|
||||
***
|
||||
## 10、SparkSQL中join操作与left join操作的区别?(重点)
|
||||
|
||||
@@ -282,19 +312,19 @@ spark-submit \
|
||||
|
||||
**三、对比:**
|
||||
|
||||
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
|
||||
基于receiver的方式,是使用Kafka的高阶API来在 ZooKeeper 中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和 ZooKeeper 之间可能是不同步的。
|
||||
|
||||
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
|
||||
基于direct的方式,使用 kafka 的简单 api ,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
|
||||
|
||||
<font color='red'>在实际生产环境中大都用Direct方式</font>
|
||||
|
||||
***
|
||||
## 15、请简述一下SparkStreaming的窗口函数中窗口宽度和滑动距离的关系?(重点)
|
||||

|
||||

|
||||
***
|
||||
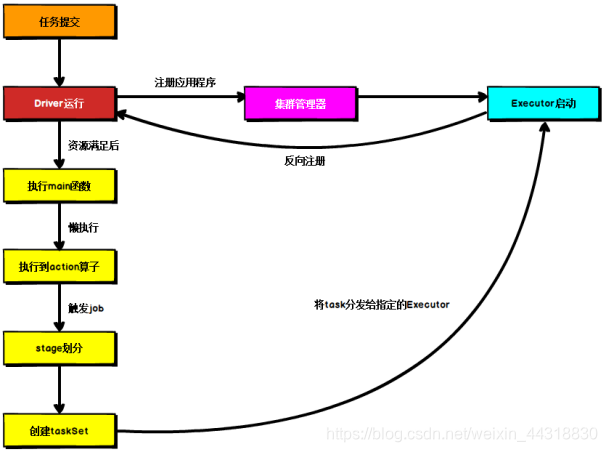
## 16、Spark通用运行流程概述?(重点)
|
||||
|
||||
|
||||

|
||||
|
||||
不论Spark以何种模式进行部署,任务提交后,都会先启动Driver进程,随后Driver进程向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配Executor并启动,当Driver所需的资源全部满足后,Driver开始执行main函数,Spark查询为懒执行,当执行到action算子时开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个taskset,taskset中有多个task,根据本地化原则,task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
|
||||
|
||||
@@ -311,13 +341,18 @@ spark-submit \
|
||||
|
||||
4)Executor:是一个进程,一个Worker上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
|
||||
|
||||
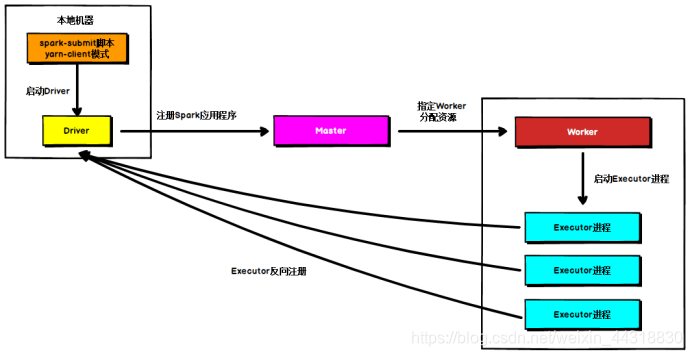
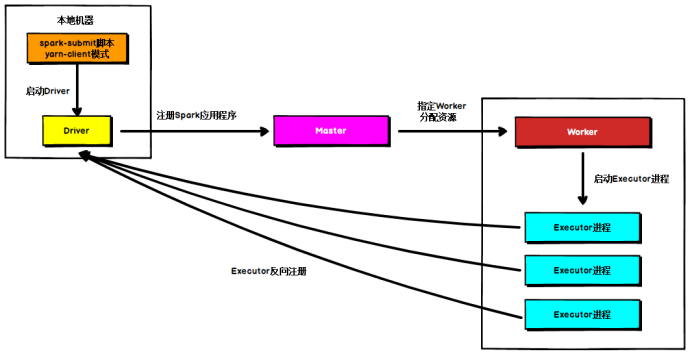
**Standalone Client模式**
|
||||
|
||||
**Standalone Client模式
|
||||
|
||||
|
||||
|
||||
在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
|
||||
|
||||
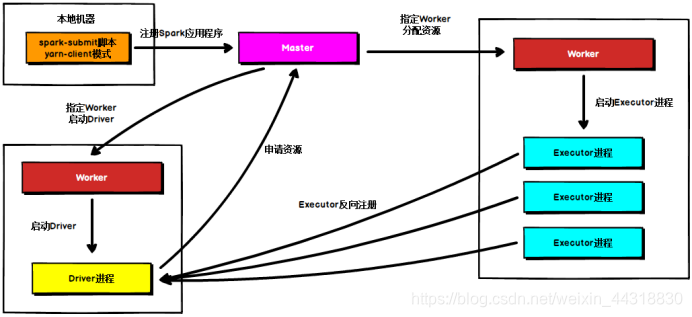
**Standalone Cluster模式**
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
在Standalone Cluster模式下,任务提交后,Master会找到一个Worker启动Driver进程, Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源至少可以启动一个Executor的所有Worker,然后在这些Worker之间分配Executor,Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成后,Driver开始执行main函数,之后执行到Action算子时,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
|
||||
|
||||
注意,Standalone的两种模式下(client/Cluster),Master在接到Driver注册Spark应用程序的请求后,会获取其所管理的剩余资源能够启动一个Executor的所有Worker,然后在这些Worker之间分发Executor,此时的分发只考虑Worker上的资源是否足够使用,直到当前应用程序所需的所有Executor都分配完毕,Executor反向注册完毕后,Driver开始执行main程序。
|
||||
@@ -331,7 +366,10 @@ spark-submit \
|
||||
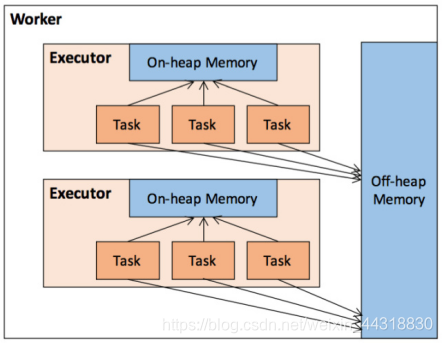
作为一个 JVM 进程,<font color='red'>Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用</font>。
|
||||
|
||||
<font color='purple'>堆内内存受到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。</font>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**1.堆内内存**
|
||||
|
||||
|
||||
Reference in New Issue
Block a user