添加了2篇关于Kylin新的文章
This commit is contained in:
151
note/其他组件/Kylin如何通过BI工具展示.md
Normal file
151
note/其他组件/Kylin如何通过BI工具展示.md
Normal file
@@ -0,0 +1,151 @@
|
||||
## 前言
|
||||
我们在上一篇 Kylin 的入门级介绍(👉[第一个“国产“Apache顶级项目——Kylin,了解一下!](https://alice.blog.csdn.net/article/details/115267160))中,就已经谈到了有很多可以与 Kylin 结合使用的可视化工具,例如
|
||||
- ODBC:与Tableau、Excel、Power BI等工具集成。
|
||||
- JDBC:与Saiku、BIRT等Java工具集成
|
||||
- REST API:与JavaScript、Web网页集成。
|
||||
|
||||
Kylin开发团队还贡献了 <font color='red'>Zepplin</font> 的插件,也可以使用Zepplin来访问Kylin服务
|
||||
|
||||
本期内容,我们就先介绍如何通过 **JDBC** 和 **Zeppelin** 的方式对 Kylin 进行集成!
|
||||
|
||||
|
||||
## JDBC
|
||||
|
||||
(1)新建一个Maven项目,并在 pom 文件中导入`kylin-jdbc`的依赖
|
||||
```xml
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.apache.kylin</groupId>
|
||||
<artifactId>kylin-jdbc</artifactId>
|
||||
<version>2.5.1</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
(2)编写代码:
|
||||
```java
|
||||
package com.alice;
|
||||
|
||||
import java.sql.*;
|
||||
|
||||
/**
|
||||
* @Author: Alice菌
|
||||
* @Date: 2021/3/29 18:29
|
||||
* @Description: 通过 JDBC 连接 Kylin
|
||||
*/
|
||||
public class KylinTest {
|
||||
public static void main(String[] args) throws SQLException, ClassNotFoundException {
|
||||
|
||||
// Kylin_JDBC 驱动
|
||||
String kylinDriver = "org.apache.kylin.jdbc.Driver";
|
||||
|
||||
// Kylin 的 URL (jdbc:kylin://ip地址:7070/项目名称(project))
|
||||
String KylinUrl = "jdbc:kylin://node01:7070/demoTest";
|
||||
|
||||
// Kylin 的 用户名
|
||||
String KylinUser = "ADMIN";
|
||||
|
||||
// Kylin 的密码
|
||||
String KylinPasswd = "KYLIN";
|
||||
|
||||
// 添加驱动信息
|
||||
Class.forName(kylinDriver);
|
||||
|
||||
// 获取连接
|
||||
Connection connection = DriverManager.getConnection(KylinUrl, KylinUser, KylinPasswd);
|
||||
|
||||
// 预编译 SQL 语句
|
||||
PreparedStatement ps = connection.prepareStatement("select date1, sum(price) as total_money, sum(amount) as total_amount from dw_sales group by date1,channelid");
|
||||
|
||||
// 执行查询
|
||||
ResultSet resultSet = ps.executeQuery();
|
||||
|
||||
// 遍历打印
|
||||
while (resultSet.next()){
|
||||
|
||||
// 获取时间
|
||||
String date1 = resultSet.getString("date1");
|
||||
// 获取总金额
|
||||
String total_money = resultSet.getString("total_money");
|
||||
// 获取总次数
|
||||
String total_amount = resultSet.getString("total_amount");
|
||||
|
||||
// 输出结果
|
||||
System.out.println(date1 + " " + total_money + " " + total_amount);
|
||||
|
||||
}
|
||||
|
||||
// 关闭连接
|
||||
connection.close();
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
(3)结果展示:
|
||||

|
||||
为了验证结果的准确性,我们到 Kylin 的 web 页面去查询一下:
|
||||

|
||||
可以发现结果是一样的😎
|
||||
|
||||
## Zeppelin
|
||||
|
||||
### 1)Zeppelin安装与启动
|
||||
|
||||
(1)将`zeppelin-0.8.0-bin-all.tgz`上传至Linux
|
||||
|
||||
(2) 解压`zeppelin-0.8.0-bin-all.tgz`到`/export/servers`目录下
|
||||
|
||||
```bash
|
||||
[root@node01 software]# tar -zxvf zeppelin-0.8.0-bin-all.tgz -C /export/servers/
|
||||
```
|
||||
(3)修改名称
|
||||
|
||||
```bash
|
||||
[root@node01 servers]# mv zeppelin-0.8.0-bin-all/ zeppelin
|
||||
```
|
||||
(4)启动 Zeppelin
|
||||
|
||||
```bash
|
||||
[root@node01 zeppelin]# bin/zeppelin-daemon.sh start
|
||||
```
|
||||
以本机为例,我们可以通过 `http://node01:8080/#/`进行查看,Web 默认端口为 8080 ,如图所示:
|
||||

|
||||
### 2)配置Zeppelin支持Kylin
|
||||
(1)选择“anonymous” → “Interpreter”选项,配置解释器
|
||||
|
||||

|
||||
|
||||
|
||||
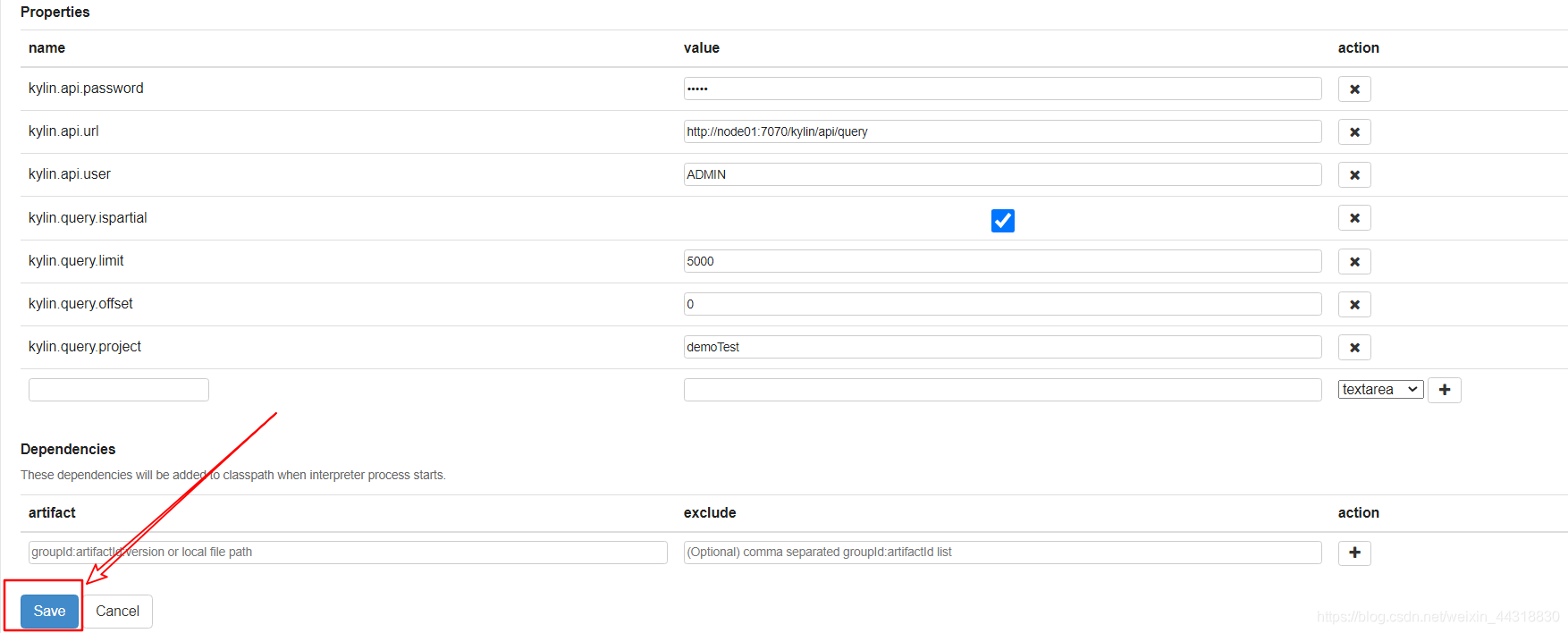
(2)搜索Kylin插件并修改相应的配置,如图所示
|
||||

|
||||
|
||||
(3)修改完成后,单击“Save” 按钮保存修改内容
|
||||
|
||||
### 3)案例实操
|
||||
|
||||
需求:查询订单商品dw_sales表的数据,并使用各种图表进行展示。
|
||||
|
||||
(1)选择“Notebook”→“Creat new note”选项,创建新的 note
|
||||

|
||||
(2)在 “Note Name” 文本框中输入 “test_kylin” 并单击“Create”按钮,如图所示:
|
||||
|
||||

|
||||
(3)note 创建成功如图所示:
|
||||

|
||||
(4)结果展示
|
||||

|
||||
(5)其他图表格式
|
||||

|
||||

|
||||

|
||||

|
||||
## 小结
|
||||
本期文章为大家介绍了 2 种通过 BI 工具展示 Kylin 查询结果的方式 ,大家仅做学习了解即可。好了,本期内容就到这里,后面会为大家介绍关于 **Cube 的构建原理** 和 **构建优化**。感兴趣的小伙伴记得点个<font color='orange'>**关注**</font>,第一时间阅读!
|
||||
|
||||
你知道的越多,你不知道的也越多。我是<font color='purple'>**大数据梦想家**</font>,<font color='RoyalBlue'>**专注于研究大数据基础,架构与原型实现**</font>。点个**关注**,我们下一期见!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
549
note/其他组件/第一个“国产“Apache顶级项目——Kylin,了解一下!.md
Normal file
549
note/其他组件/第一个“国产“Apache顶级项目——Kylin,了解一下!.md
Normal file
@@ -0,0 +1,549 @@
|
||||
> **本文已收录github:[https://github.com/BigDataScholar/TheKingOfBigData](https://github.com/BigDataScholar/TheKingOfBigData),里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!**
|
||||
## 前言
|
||||
说到Apache顶级开源项目,大家首先会想到什么???
|
||||
|
||||
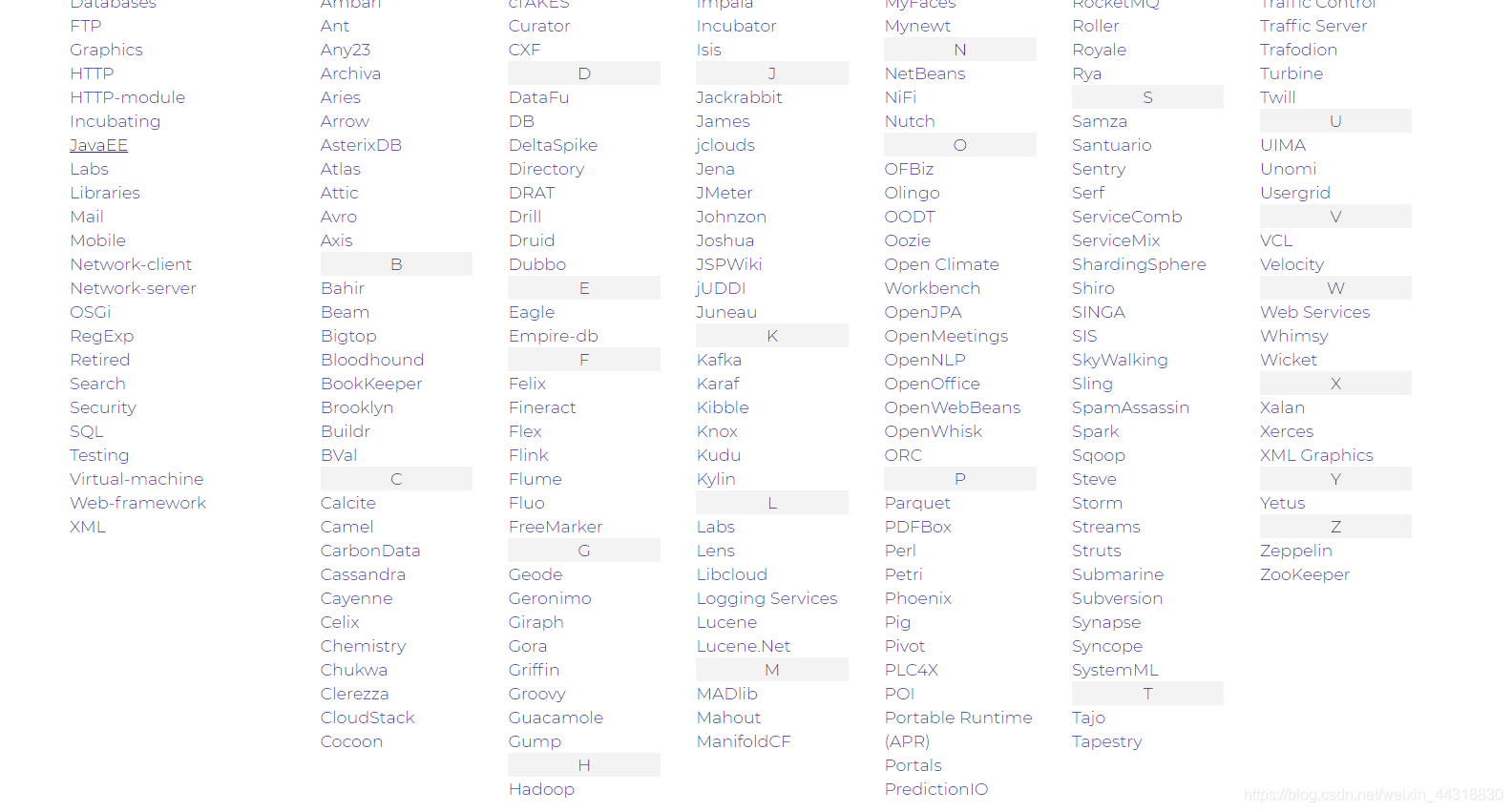
不熟悉Apache软件基金会的朋友也不用担心,大家可以去[Apache官网](https://www.apache.org/),下拉到最下边的页面,查看Apache有哪些开源项目。
|
||||
|
||||
相信各位朋友在项目清单中肯定会看到不少熟悉的身影,`JavaEE`,`HTTP`,`FTP`,`Hadoop`,`SQL`,`Maven`,`Tomcat`,`Kafka`,`Hive`...这些几乎我们天天都在打交道的`朋友`,竟然都是Apache顶级项目“家族”的一员。
|
||||
|
||||
也许你会有些遗憾,这些顶级项目都是由外国友人所贡献的。但认真看了本期内容标题的朋友都应该期待着,接下来,我要为大家介绍的是正如题目所述,<font color='#9F35FF'>第一个由国人开发的Apache顶级项目——Kylin</font>!
|
||||
|
||||

|
||||
|
||||
|
||||
## Kylin
|
||||
|
||||
### 诞生背景
|
||||
|
||||
目前大数据存在需要大量行为数据与用户标签数据的多维度的复杂分析统计场景,此场景同时有大量行为数据(事实数据)与多维度分析数据。需要在**近实时查询**的情况下快速得到结果帮助公司进行分析和决策。
|
||||
|
||||
Kylin是中国团队研发的,是第一个真正由中国人自己主导、从零开始、自主研发、并成为Apache顶级开源项目。它巧妙地将“Hive支持SQL灵活查询,但速度特别慢”与“HBase查询性能快,但原生不支持SQL”的设计巧妙结合在了一起。Kylin先将数据进行预处理,将预处理的结果放在HBase当中,大大提高了查询时的效率!
|
||||
|
||||
### 简介
|
||||
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析的功能,支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的 Hive 表。
|
||||
|
||||
### 架构
|
||||
|
||||
Kylin架构如图所示
|
||||
|
||||
|
||||

|
||||
其中,Kylin 具有如下几个关键组件。
|
||||
|
||||
#### 1.REST Server
|
||||
REST Server是面向应用程序开发的入口点,旨在完成针对Kylin平台的应用开发工作,可以提供查询、获取结果、触发Cube 构建任务、获取元数据及获取用户权限等功能,另外可以通过 REST API 接口实现 SQL查询。
|
||||
|
||||
#### 2.Query Engine
|
||||
当Cube准备就绪后,查询引擎即可获取并解析用户所查询的问题。它随后会与系统中的其他组件进行交互,从而向用户返回对应的结果。
|
||||
|
||||
#### 3.Routing
|
||||
|
||||
在最初设计时,设计者曾考虑将Kylin不能执行的查询引导到Hive中继续执行,但在实践后发现,Hive与Kylin的查询速度差异过大,导致用户无法对查询的速度有一致的期望,大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此,用户体验非常糟糕。最后这个路由功能在发行版中被默认关闭。
|
||||
|
||||
#### 4.Metadata
|
||||
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin 中的所有元数据进行管理,其中包括最为重要的 Cube 元数据。其他组件的正常运作都需要以元数据管理工具为基础。**Kylin的元数据存储在HBase中**。
|
||||
|
||||
|
||||
#### 5.Cube Build Engine
|
||||
|
||||
Cube构建引擎的设计目的在于处理所有离线任务,其中包括 Shell脚本、Java API、MapReduce任务等。Cube Build Engine对Kylin中的全部任务加以管理与协调,从而确保每项任务都能得到切实执行并解决期间出现的故障。
|
||||
|
||||
Kylin的主要特点及说明如下。
|
||||
|
||||
- **支持标准SQL接口**:Kylin以标准的SQL作为对外服务的接口。
|
||||
- **支持超大规模数据集**:Kylin对大数据的支撑能力是目前所有技术中较为领先的。早在2015年eBay的生产环境中就能支持百亿条记录的秒级查询,之后在移动的应用场景中又有了支持千亿条记录的秒级查询的案例。
|
||||
- **亚秒级响应**:Kylin拥有优异的查询响应速度,这点得益于预计算,很多复杂的计算,比如,连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
|
||||
- **高伸缩性和高吞吐率**:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
|
||||
- **BI工具集成**。Kylin可以与现有的BI工具集成。
|
||||
|
||||
另外,Kylin开发团队还贡献了 Zeppelin 的插件,用户可以使用 Zeppelin 访问 Kylin 服务。
|
||||
|
||||
### 应用场景
|
||||
Kylin 典型的<font color='tomato'>**应用场景**</font>如下:
|
||||
|
||||
- 用户数据存在于 Hadoop HDFS中,利用 Hive 将 HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
|
||||
- 每天有数G甚至数十G的数据增量导入
|
||||
- 有10个以内较为固定的分析维度.....
|
||||
|
||||
Kylin 的<font color='tomato'>**核心思想**</font>是**利用空间换时间**,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存。
|
||||
|
||||
<font color='tomato'>**原理**</font>为通过 hive 将海量数据通过统计转化为多维度数据模型表(星型模型、雪花模型等),通过 Kylin 使用字典编码(Dictionary-coder)将维度数据进行压缩生成维度字典。然后将事实维度数据转换为 Kylin 的 cube 数据模型,实现预计算,并可使用标准 SQL 查询。
|
||||
|
||||
### 使用 Kylin 的公司
|
||||
Kylin如今作为大数据业内十分热门的“OLAP”引擎,在越来越多公司中得到“重用”!
|
||||
|
||||

|
||||
具体在企业中是如何使用的,我就不在这里赘述了,感兴趣大家可以从以下链接去做学习了解。
|
||||
|
||||
> https://www.jianshu.com/p/aae410e5a2fe 《Apache Kylin在美团数十亿数据OLAP场景下的实践》
|
||||
> https://www.sohu.com/a/240896646_659643 《实践 | Kylin在滴滴OLAP引擎中的应用》
|
||||
|
||||
|
||||
## HBase安装
|
||||
在安装 Kylin 前需要先安装部署好 Hadoop、Hive、Zookeeper 和 HBase,并且需要在 `/etc/profile` 目录下配置 `HADOOP_HOME` 、`HIVE_HOME`、`HBASE_HOME` 环境变量,注意执行`source/etc/profile`命令使其生效。
|
||||
|
||||
(1)保证 Zookeeper 集群的正常部署,并启动它。
|
||||
|
||||
```javascript
|
||||
[root@node01 zookeeper-3.4.9]$ bin/zkServer.sh start
|
||||
[root@node02 zookeeper-3.4.9]$ bin/zkServer.sh start
|
||||
[root@node03 zookeeper-3.4.9]$ bin/zkServer.sh start
|
||||
```
|
||||
|
||||
(2)保证 Hadoop 集群的正常部署,并启动它
|
||||
|
||||
```javascript
|
||||
[root@node01 hadoop-2.7.2]$ sbin/start-dfs.sh
|
||||
[root@node01 hadoop-2.7.2]$ sbin/start-yarn.sh
|
||||
```
|
||||
|
||||
(3)解压 HBase 安装包到指定目录。
|
||||
```javascript
|
||||
[root@node01 software]$ tar -zxvf hbase-1.3.1-bin.tar.gz -C /export/servers
|
||||
```
|
||||
|
||||
(4)修改 HBase 对应的配置文件
|
||||
|
||||
① hbase-env.sh 文件的修改内容如下
|
||||
|
||||
```bash
|
||||
export JAVA_HOME=/opt/module/jdk1.8.0_144
|
||||
export HBASE_MANAGES_ZK=false
|
||||
```
|
||||
② hbase-site.xml 文件的修改内容如下
|
||||
|
||||
注意:
|
||||
|
||||
- 修改HDFS NameNode节点名称
|
||||
- 修改zookeeper服务器名称
|
||||
- 修改zookeeper数据目录位置
|
||||
|
||||
```javascript
|
||||
<configuration>
|
||||
<property>
|
||||
<name>hbase.rootdir</name>
|
||||
<value>hdfs://node01:8020/hbase_1.3.1</value>
|
||||
</property>
|
||||
|
||||
<property>
|
||||
<name>hbase.cluster.distributed</name>
|
||||
<value>true</value>
|
||||
</property>
|
||||
|
||||
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
|
||||
<property>
|
||||
<name>hbase.master.port</name>
|
||||
<value>16000</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.zookeeper.property.clientPort</name>
|
||||
<value>2181</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.master.info.port</name>
|
||||
<value>60010</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.zookeeper.quorum</name>
|
||||
<value>node01,node02,node03</value>
|
||||
</property>
|
||||
|
||||
<property>
|
||||
<name>hbase.zookeeper.property.dataDir</name>
|
||||
<value>/export/servers/zookeeper-3.4.9/zkdatas</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.thrift.support.proxyuser</name>
|
||||
<value>true</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hbase.regionserver.thrift.http</name>
|
||||
<value>true</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
③ 在 regionservers 文件中增加如下内容
|
||||
|
||||
```bash
|
||||
node01
|
||||
node02
|
||||
node03
|
||||
```
|
||||
④ 软连接 Hadoop 配置文件到 HBase
|
||||
|
||||
```bash
|
||||
ln -s /export/servers/hadoop-2.7.2/etc/hadoop/core-site.xml $PWD/core-site.xml
|
||||
ln -s /export/servers/hadoop-2.7.2/etc/hadoop/hdfs-site.xml $PWD/hdfs-site.xml
|
||||
```
|
||||
⑤ 将 HBase 远程发送到其他集群
|
||||
|
||||
```bash
|
||||
[root@node01 servers]$ xsync hbase_1.3.1/
|
||||
```
|
||||
(4)配置 HBase 环境变量
|
||||
|
||||
```javascript
|
||||
# Apache HBase 1.3.1
|
||||
export HBASE_HOME=/export/servers/hbase-1.3.1
|
||||
export PATH=$HADOOP/sbin:$HADOOP/bin:$HBASE_HOME/bin:$PATH
|
||||
```
|
||||
|
||||
刷新环境变量
|
||||
|
||||
```javascript
|
||||
source /etc/profile
|
||||
```
|
||||
|
||||
(5)启动 HBase 服务。
|
||||
|
||||
|
||||
|
||||
|
||||
进入hbase shell
|
||||
|
||||
```javascript
|
||||
bin/start-hbase.sh
|
||||
```
|
||||
|
||||
执行上述操作,执行list命令,如果能显示以下内容,表示安装成功。
|
||||
|
||||
```javascript
|
||||
hbase(main):002:0> list
|
||||
TABLE
|
||||
0 row(s) in 0.1380 seconds
|
||||
|
||||
=> []
|
||||
```
|
||||
|
||||
当然,你也可以通过`host:port`的方式来访问 HBase 的页面,例如:`http://node01:16010/`
|
||||
|
||||

|
||||
|
||||
|
||||
OK,安装完了 Hbase1.3.1,接着我们开始安装 kylin 。
|
||||
|
||||
## Kylin安装
|
||||
(1)下载 Kylin 安装包
|
||||
|
||||
(2)解压 `apache-kylin-2.6.3-bin-hbase1x.tar.gz` 到` /export/servers` 目录下
|
||||
|
||||
```bash
|
||||
tar -zxf /export/softwares/apache-kylin-2.6.3-bin-hbase1x.tar.gz -C /export/servers/
|
||||
```
|
||||
|
||||
注 意 : 启 动 前 需 检 查 `/etc/profile` 目 录 中 的 `HADOOP_HOME` 、 `HIVE_HOME` 和 `HBASE_HOME` 是否配置完毕
|
||||
|
||||
|
||||
(3)启动
|
||||
|
||||
① 在启动 Kylin 之前,需要先启动 Hadoop(HDFS、YARN、JobHistoryServer)、Zookeeper 和 HBase。需要注意的是,要同时启动 Hadoop 的历史服务器,对 Hadoop 集群配置进行如下修改。
|
||||
|
||||
配置 mapred-site.xml 文件。
|
||||
|
||||
```bash
|
||||
[root@node01 hadoop]$ vim mapred-site.xml
|
||||
<property>
|
||||
<name>mapreduce.jobhistory.address</name>
|
||||
<value>node01:10020</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>mapreduce.jobhistory.webapp.address</name>
|
||||
<value>node01:19888</value>
|
||||
</property>
|
||||
```
|
||||
配置 yarn-site.xml 文件。
|
||||
|
||||
```bash
|
||||
[root@node01 hadoop]$ vim yarn-site.xml
|
||||
<!-- 日志聚集功能开启 -->
|
||||
<property>
|
||||
<name>yarn.log-aggregation-enable</name>
|
||||
<value>true</value>
|
||||
</property>
|
||||
<!-- 日志保留时间设置为 7 天 -->
|
||||
<property>
|
||||
<name>yarn.log-aggregation.retain-seconds</name>
|
||||
<value>604800</value>
|
||||
</property>
|
||||
```
|
||||
|
||||
修改配置后,分发配置文件,重启 Hadoop 的 HDFS 和 YARN 的所有进程。
|
||||
|
||||
启动 Hadoop 历史服务器。
|
||||
|
||||
```bash
|
||||
[root@node01 hadoop-2.6.0-cdh5.14.0]$ sbin/mr-jobhistory-daemon.sh start historyserver
|
||||
```
|
||||
|
||||
② 启动 Kylin
|
||||
|
||||
```bash
|
||||
[root@node01 kylin]$ bin/kylin.sh start
|
||||
```
|
||||
启动之后查看各台节点服务器的进程。
|
||||
|
||||
```bash
|
||||
--------------------- node01 ----------------
|
||||
3360 JobHistoryServer
|
||||
31425 HMaster
|
||||
3282 NodeManager
|
||||
3026 DataNode
|
||||
53283 Jps
|
||||
2886 NameNode
|
||||
44007 RunJar
|
||||
2728 QuorumPeerMain
|
||||
31566 HRegionServer
|
||||
--------------------- node02 ----------------
|
||||
5040 HMaster
|
||||
2864 ResourceManager
|
||||
9729 Jps
|
||||
2657 QuorumPeerMain
|
||||
4946 HRegionServer
|
||||
2979 NodeManager
|
||||
2727 DataNode
|
||||
--------------------- node03 ----------------
|
||||
4688 HRegionServer
|
||||
2900 NodeManager
|
||||
9848 Jps
|
||||
2636 QuorumPeerMain
|
||||
2700 DataNode
|
||||
2815 SecondaryNameNode
|
||||
```
|
||||
在浏览器地址栏中输入`node01:7070/kylin/login`,查看 Web 页面,如图所示:
|
||||

|
||||
用户名为 ADMIN,密码为 KYLIN(系统已填)
|
||||
|
||||
(4)关闭Kylin
|
||||
|
||||
如果我们想要关闭 Kylin,只需要执行下面的命令:
|
||||
|
||||
```bash
|
||||
[root@node01 apache-kylin-2.6.3]# bin/kylin.sh stop
|
||||
```
|
||||
|
||||
## Kylin的使用
|
||||
到了这一步,我们终于将 Kylin 安装好了,下面我们来讲一下 Kylin 的具体使用。
|
||||
|
||||
### 准备测试数据表
|
||||
为了让最终的演示更具有说明力,同时也为了方便后续的学习,接下来我们需要先准备几张测试数据表。
|
||||
|
||||
|
||||
**1、(事实表)dw_sales**
|
||||
|
||||
|列名 | 列类型|说明|
|
||||
|:--|:--|:--|
|
||||
| id | string |订单id
|
||||
|date1|string|订单日期
|
||||
|channelid|string|订单渠道(商场、京东、天猫)
|
||||
productid|string|产品id
|
||||
|regionid|string|区域名称
|
||||
|amount|int|商品下单数量
|
||||
price|double|商品金额|
|
||||
|
||||
**2、(维度表_渠道方式)dim_channel**
|
||||
|列名 |列类型 |说明|
|
||||
|:--|:--|:--|:--|
|
||||
| channelid| string|渠道id|
|
||||
|channelname|string|渠道名称
|
||||
|
||||
**3、(维度表_产品名称)dim_product**
|
||||
|
||||
|列名 |列类型 |说明|
|
||||
|:--|:--|:--|:--|
|
||||
|productid | string |产品id
|
||||
productname|string|产品名称|
|
||||
|
||||
|
||||
**4、(维度表_区域)dim_region**
|
||||
|
||||
|列名 |列类型 |说明|
|
||||
|:--|:--|:--|:--|
|
||||
|regionid | string|区域id|
|
||||
|regionname|string|区域名称|
|
||||
|
||||
|
||||
### 导入测试数据
|
||||
准备好了测试数据之后,我们需要将在 Hive 中 建好对应的表,这里我采取的是执行已经写好的脚本`hive.sql`文件,创建测试表。
|
||||
> 对应的数据文件和sql脚本不方便在这里展示,需要的同学可以添加我的微信:zwj_bigdataer 获取
|
||||
|
||||
**操作步骤:**
|
||||
|
||||
1、使用 beeline 连接Hive
|
||||
|
||||
```sql
|
||||
!connect jdbc:hive2://node1:10000
|
||||
```
|
||||
|
||||
2、创建并切换到 itcast_dw 数据库
|
||||
|
||||
```sql
|
||||
create database itcast_kylin_dw;
|
||||
use itcast_kylin_dw;
|
||||
```
|
||||
3、执行上面我们提到的`hive.sql`文件,执行sql、创建测试表
|
||||
|
||||
```sql
|
||||
-- 执行sql文件
|
||||
source hive.sql
|
||||
-- 查看表是否创建成功
|
||||
show tables;
|
||||
```
|
||||
|
||||

|
||||
4、在home目录创建`~/dat_file` 文件夹,并将测试数据文件上传到该文件夹中
|
||||
|
||||
`mkdir ~/dat_file`
|
||||
|
||||
导入数据到表中
|
||||
|
||||
```bash
|
||||
-- 导入数据
|
||||
LOAD DATA LOCAL INPATH '/root/dat_file/dw_sales_data.txt' OVERWRITE INTO TABLE dw_sales;
|
||||
LOAD DATA LOCAL INPATH '/root/dat_file/dim_channel_data.txt' OVERWRITE INTO TABLE dim_channel;
|
||||
LOAD DATA LOCAL INPATH '/root/dat_file/dim_product_data.txt' OVERWRITE INTO TABLE dim_product;
|
||||
LOAD DATA LOCAL INPATH '/root/dat_file/dim_region_data.txt' OVERWRITE INTO TABLE dim_region;
|
||||
```
|
||||
5、执行一条SQL语句,确认数据是否已经成功导入
|
||||

|
||||
### 指标和维度
|
||||
在确认完成了上面的数据准备操作之后,我们就可以对 kylin 进行实际操作了。但我们还需要先了解一下,什么是**指标和维度**?
|
||||
|
||||
首先来看下面的 demo
|
||||

|
||||
相信各位朋友已经有了自己的想法和答案,这里提供一种思考方式:
|
||||
|
||||
> <font color='red'>红色字体</font>是指标/度量?还是维度?
|
||||
> 答案:<font color='red'>指标/度量【到底要看什么?获取什么?】</font><br>
|
||||
> <font color='blue'>蓝色字体</font>是指标/度量?还是维度?
|
||||
> 答案:<font color='blue'>维度【怎么看!怎么获取!】</font>
|
||||
|
||||
==**结论**:需求决定哪些是维度,哪些是指标。==
|
||||
|
||||
|
||||
好了,明确了什么是维度,什么是指标之后,我们就可以正式开启kylin的使用之旅了~
|
||||
|
||||
|
||||
### 按照日期统计订单总额/总数量(Kylin方式)
|
||||
做任何事情都有一个顺序,使用一门新的技术亦是如此。要使用Kylin进行OLAP分析,需要按照以下方式来进行。
|
||||
|
||||
1、创建项目(Project)
|
||||
|
||||
|
||||
2、创建数据源(DataSource)
|
||||
|
||||
- 指定有哪些数据需要进行数据分析
|
||||
|
||||
3、创建模型(Model)
|
||||
|
||||
- 指定具体要对哪个事实表、那些维度进行数据分析
|
||||
|
||||
|
||||
4、创建立方体(Cube)
|
||||
|
||||
- 指定对哪个数据模型执行数据预处理,生成不同维度的数据
|
||||
|
||||
5、执行构建、等待构建完成
|
||||
|
||||
6、再执行SQL查询,获取结果
|
||||
|
||||
#### 具体步骤:
|
||||
|
||||
##### 1、创建 Project
|
||||
(1)点击 + 图标创建工程,如图所示:
|
||||
|
||||

|
||||
(2)填写工程名称和描述信息,并单击“Submit”按钮提交
|
||||

|
||||
|
||||
##### 2、获取数据源
|
||||
(1)选择“Data Source”选项卡,如图所示:
|
||||

|
||||
(2)单击图中箭头所指的图标,导入 Hive 表。
|
||||
|
||||

|
||||
(3)选中所需数据表,并单击“Sync”按钮,如图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
##### 3、创建 Model
|
||||
|
||||
(1)选择“Models”选项卡,然后单击“New”按钮,接着单击“NewModel”按钮。
|
||||

|
||||
(2)填写Model信息,然后单击“Next”按钮,如图所示
|
||||

|
||||
(3)选择事实表
|
||||
|
||||

|
||||
(4)选择事实表中,所有有可能用到的维度,然后点击 `Next`按钮
|
||||
(5)选择度量字段,并单击`Next`按钮
|
||||

|
||||
(6)指定事实表分区字段(仅支持时间分区),但是我们这次的演示用不上,所以我们这里直接单击“Save”按钮,然后在弹窗中点击“Yes”,Model 创建完毕!
|
||||
|
||||
|
||||
此时我们就可以在初始界面看到已经创建好的 Model
|
||||

|
||||
##### 4、创建 Cube
|
||||
|
||||
(1)单击“New Cube”按钮
|
||||

|
||||
(2)填写Cube信息,选择Cube所依赖的 Model,并单击“Next”按钮,如图所示:
|
||||
|
||||

|
||||
(3)选择 Cube 所需的维度,如图
|
||||
|
||||

|
||||
(4)选择 Cube 所需的度量值
|
||||

|
||||
根据我们SQL的查询需求,对指定的字段设置聚合
|
||||

|
||||
|
||||
点击 `Next`
|
||||

|
||||
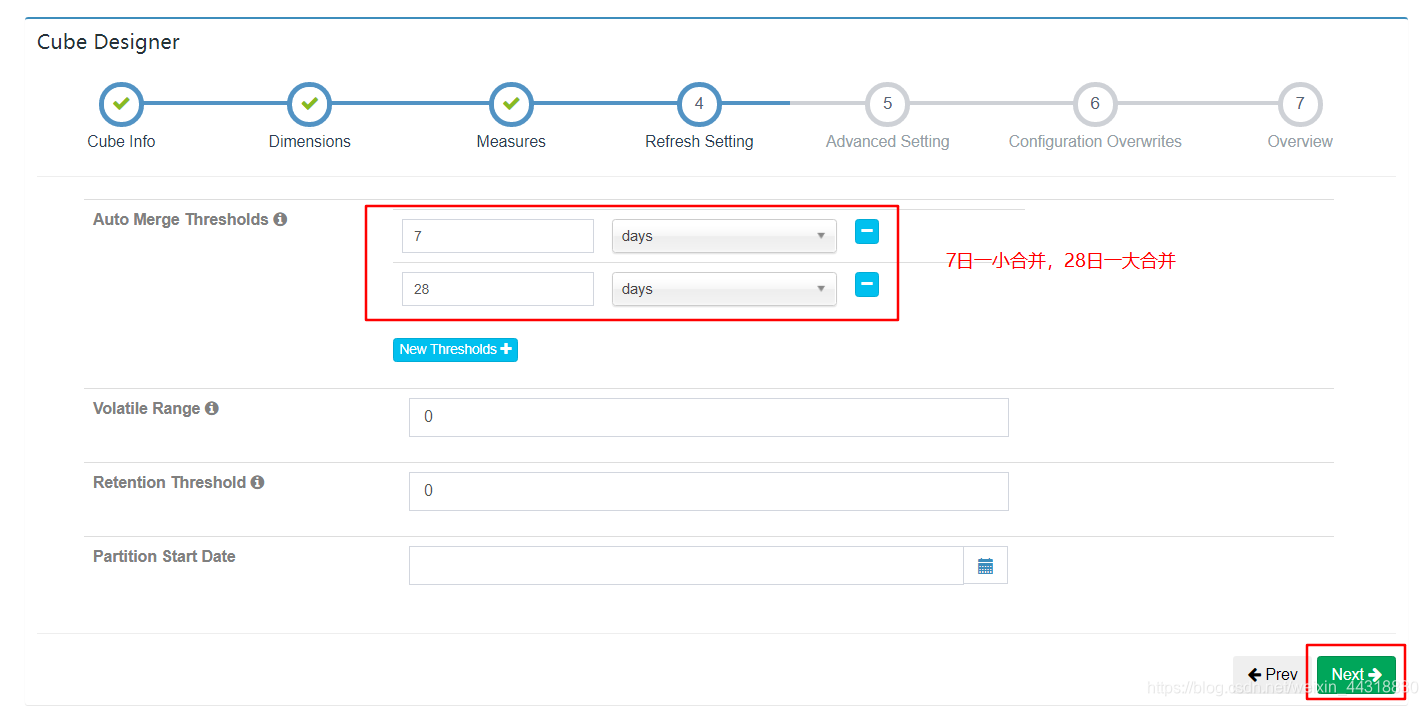
(5)Cube自动合并设置。每天Cube需按照日期分区字段进行构建,每次构建的结果会保存到 HBase的一张表中,为提高查询效率,需将每日的 Cube 进行合并,此处可设置合并周期
|
||||
|
||||
|
||||
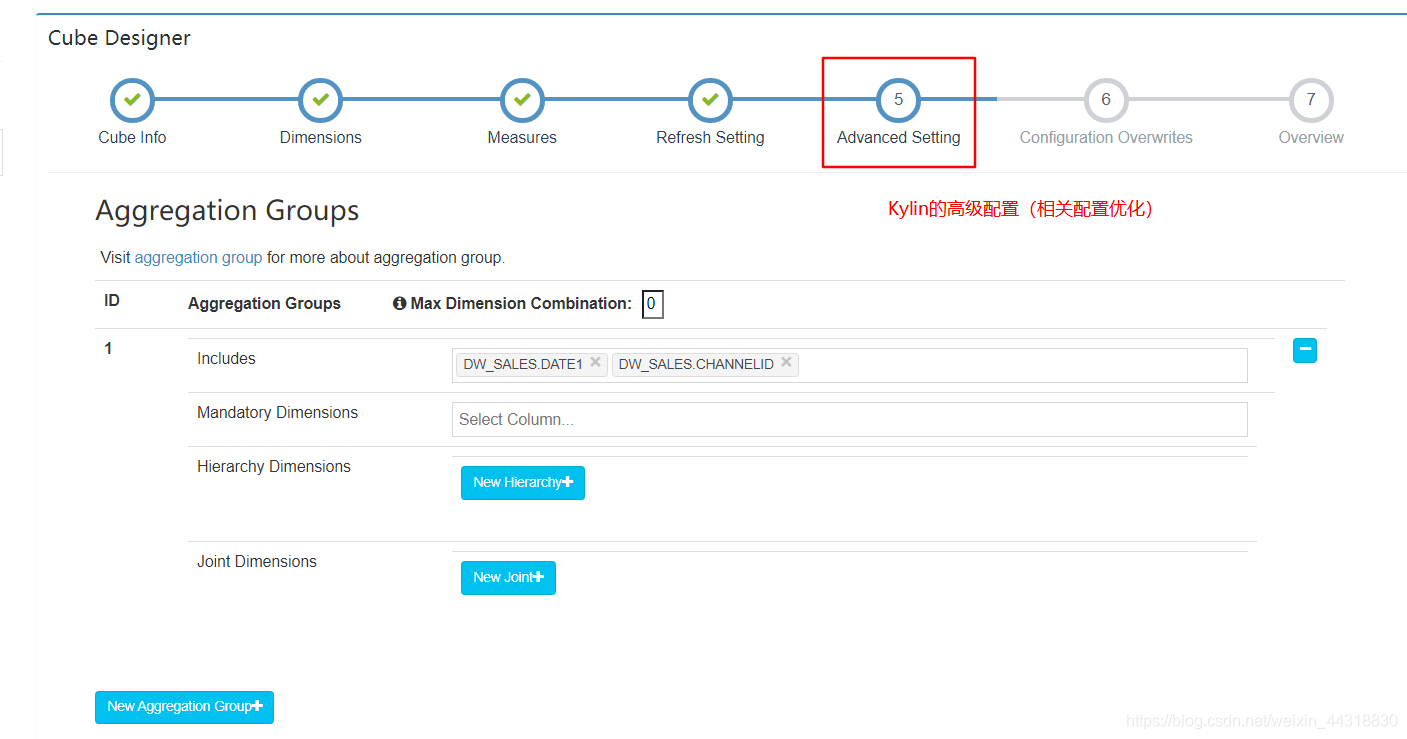
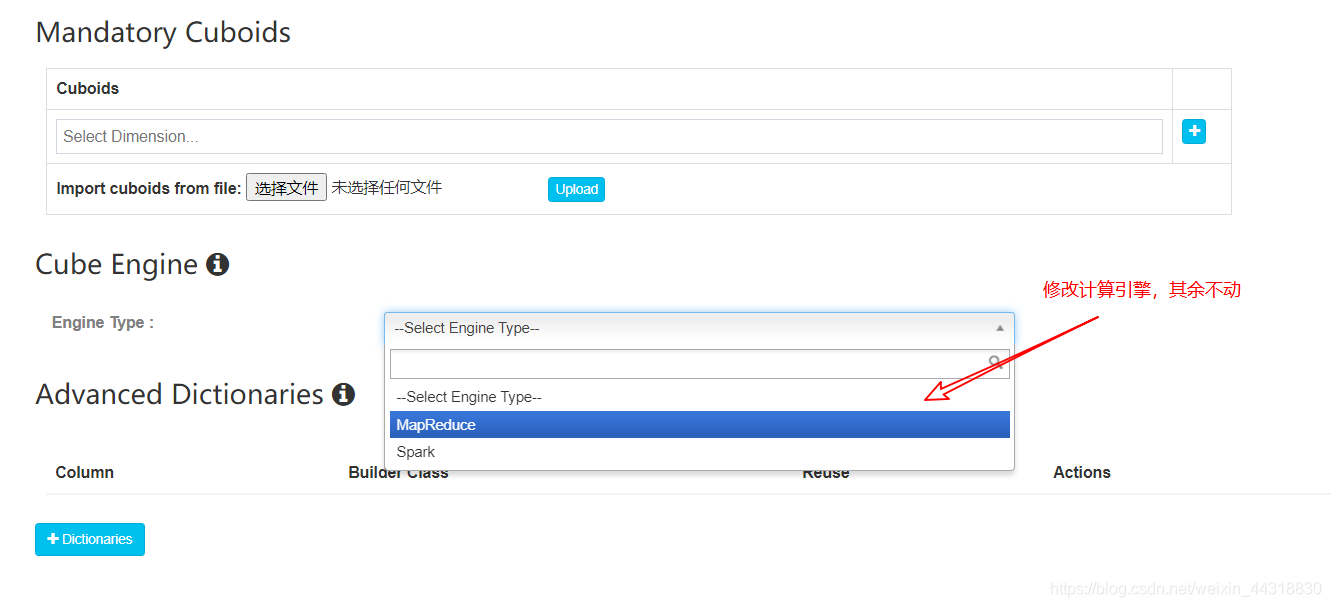
(6)Kylin的高级配置(优化相关配置),这里我们就暂只修改一下计算引擎,其他配置不动,执行完毕点击`Next`
|
||||
|
||||
|
||||
(7)Kylin 属性值覆盖相关配置信息,我们不用进行任何操作,直接 `Next`
|
||||

|
||||
(8)此时显示的是Cube的设计信息总览,如图单击`Save`按钮,Cube创建完成!
|
||||

|
||||
保存完毕,我们可以看见一个新的Cube已经创建好了~
|
||||

|
||||
(9)构建 Cube(计算),单击对应的Cube的“Action”下拉按钮,选择 “Build” 选项
|
||||

|
||||
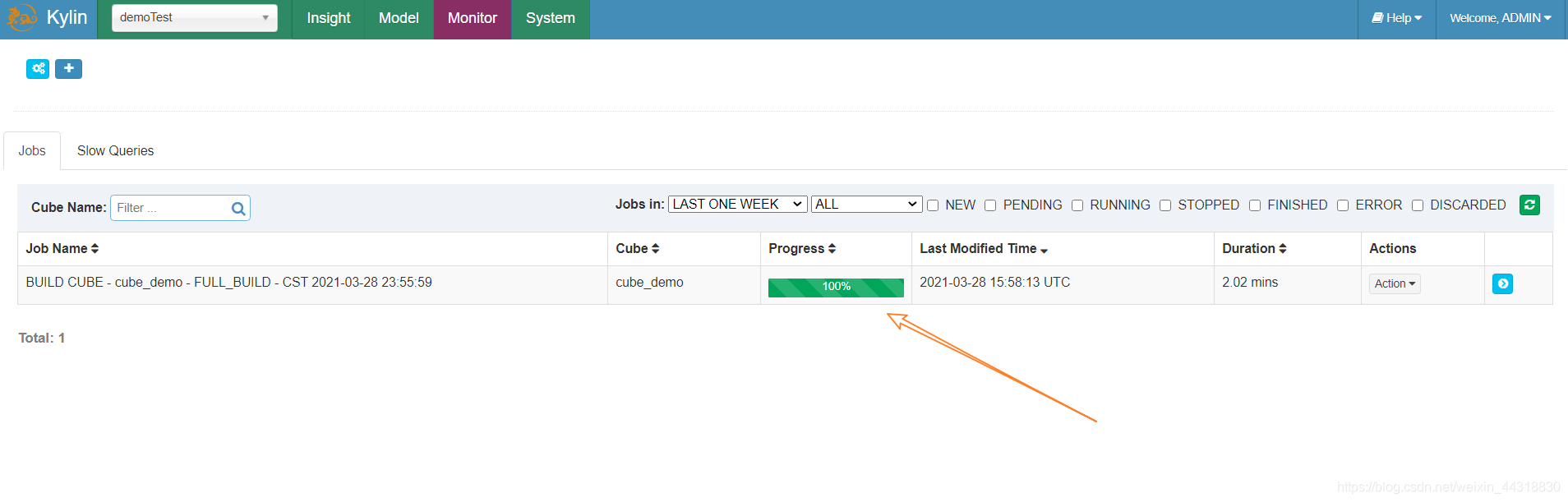
(10)选择“Monitor”,查看构建进度,可以发现此时进度还在加载
|
||||

|
||||
稍等片刻,刷新页面,可以看到 Cube 已经构建完毕
|
||||
|
||||
注意看此时 Cube 就已经变成 `READY`的状态了
|
||||

|
||||
|
||||
##### 5、执行SQL查询
|
||||
忙碌了好一阵子,终于可以展示 Kylin 的威力了,接下来我们从 Cube 中查询数据
|
||||
|
||||
```sql
|
||||
select date1,
|
||||
sum(price) as total_money,
|
||||
sum(amount) as total_amount
|
||||
from dw_sales
|
||||
group by date1, channelid;
|
||||
```
|
||||
查询结果如下
|
||||

|
||||
|
||||
|
||||
我们可以发现用 Kylin 执行 HQL 语句的速度最早为4.69s,第二次执行就变成了0.01s
|
||||
|
||||
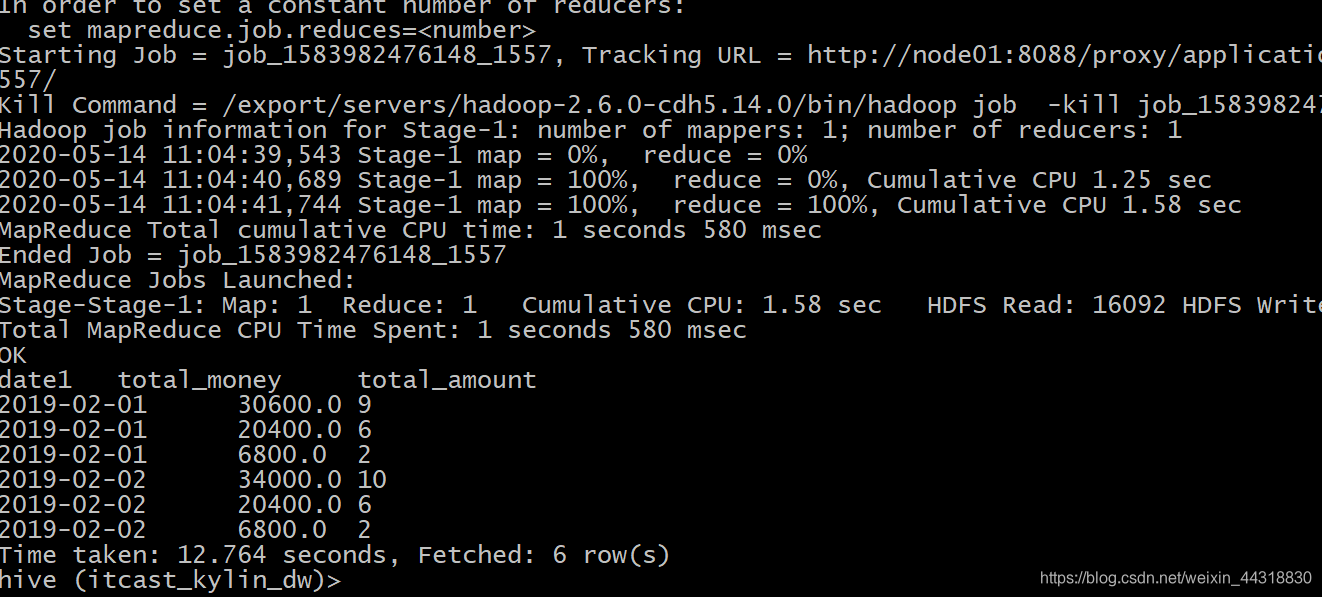
那如果在Hive的命令行窗口执行相同的HQL语句,耗时将为多少呢?
|
||||
|
||||
可以看到 Hive 将 HQL 转化成 MapReduce 程序去执行后,查询的时间为`12.764` s,这个速度与上面用 `Kylin` 执行的速度相比,差了近 **100** 倍。如果数据量更大一些,Kylin的优势将会更加明显。
|
||||
|
||||
## 小结
|
||||
本篇文章作为 Kylin 的入门篇,非常详细清楚地为大家从 **Kylin 的诞生背景,简介,架构 ,应用场景再到 HBase,Kylin 安装,并用一个简单的例子为大家演示了 Kylin 的具体使用**。当然,关于 Kylin 还有很多进阶的内容,例如 **Cube 的构建原理,构建优化,Kylin 与 BI 工具的集成**等等 ..... 这些内容会在后面的文章中具体介绍,感兴趣的小伙伴记得点个关注,第一时间阅读!
|
||||
|
||||
你知道的越多,你不知道的也越多。我是<font color='DarkOrchid'>**大数据梦想家**</font>,<font color='RoyalBlue'>**专注于研究大数据基础,架构与原型实现**</font>。点个**关注**,我们下一期见!
|
||||
|
||||
|
||||
Reference in New Issue
Block a user