11 KiB
上小节 中,我们已经了解了 RBAC 权限模型。本小节中,我们先来将 RBAC 模型对应的表现设计好。
表设计

除了已经创建好的 t_user 用户表外,还需另外创建 4 张表,如上图所示:
- 角色表;
- 权限表;
- 角色权限关联表;
- 用户角色关联表;
角色表、权限表
角色表与权限表的建表语句如下:
CREATE TABLE `t_role` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`role_name` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '角色名',
`role_key` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '角色唯一标识',
`status` tinyint NOT NULL DEFAULT '0' COMMENT '状态(0:启用 1:禁用)',
`sort` int unsigned NOT NULL DEFAULT 0 COMMENT '管理系统中的显示顺序',
`remark` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '备注',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '最后一次更新时间',
`is_deleted` bit(1) NOT NULL DEFAULT b'0' COMMENT '逻辑删除(0:未删除 1:已删除)',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_role_key` (`role_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='角色表';
CREATE TABLE `t_permission` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`parent_id` bigint unsigned NOT NULL DEFAULT '0' COMMENT '父ID',
`name` varchar(16) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '权限名称',
`type` tinyint unsigned NOT NULL COMMENT '类型(1:目录 2:菜单 3:按钮)',
`menu_url` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '菜单路由',
`menu_icon` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '菜单图标',
`sort` int unsigned NOT NULL DEFAULT 0 COMMENT '管理系统中的显示顺序',
`permission_key` varchar(64) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '权限标识',
`status` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '状态(0:启用;1:禁用)',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`is_deleted` bit(1) NOT NULL DEFAULT b'0' COMMENT '逻辑删除(0:未删除 1:已删除)',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='权限表';
着重讲解一下权限表中,几个字段的作用:
parent_id: 父ID, 用于构建权限的树结构;
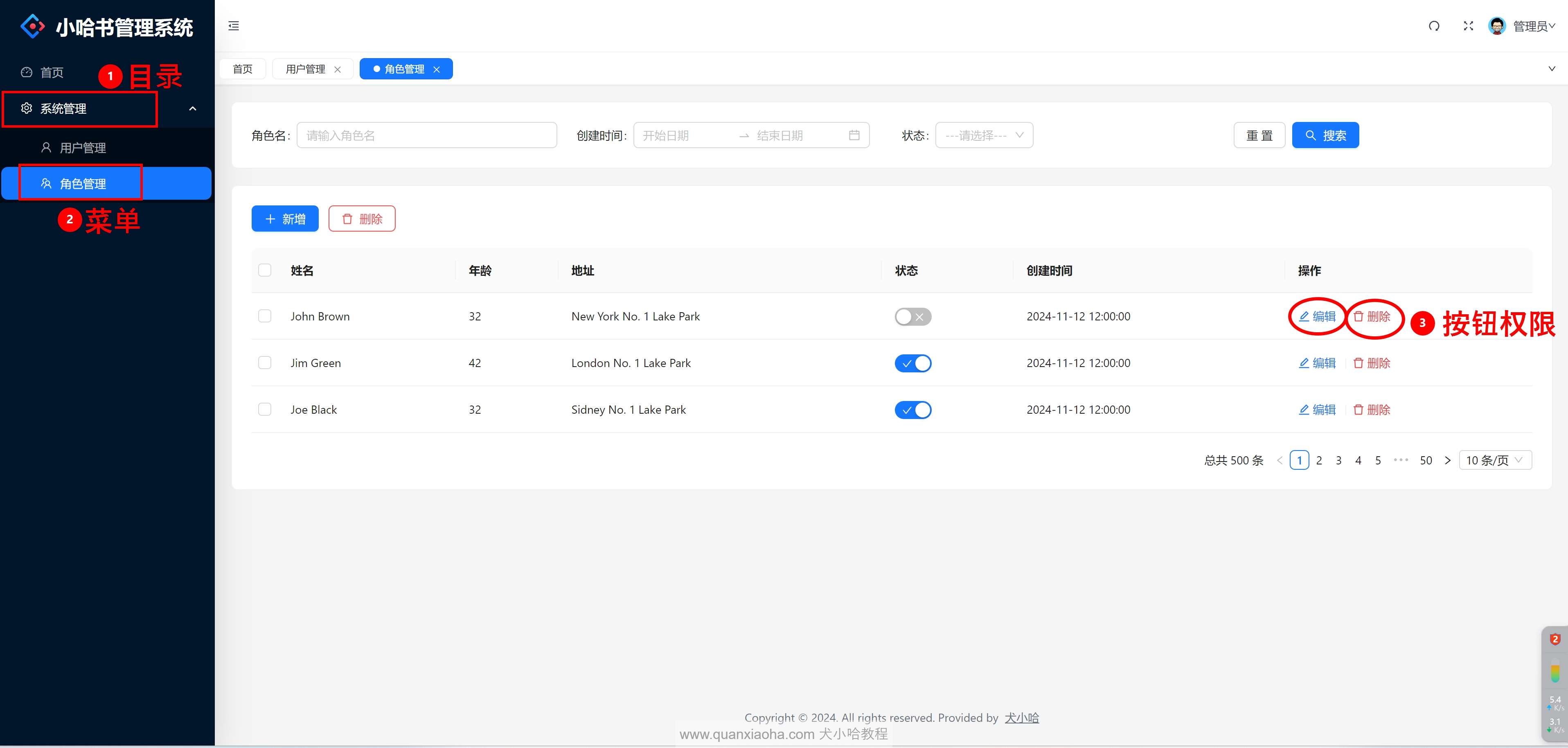
type: 权限类型,前台模块,主要是按钮,也可以理解为操作,即用户有没有发笔记、发评论等等的权限,这块比较好理解;后台管理则是控制目录 -> 菜单 -> 按钮的权限,如下图所示:
menu_url: 当权限类型为菜单时,配置前端路由地址;
icon: 当权限类型为目录、菜单时,自定义图标;
permission_key: 权限唯一标识,如system:role:add, 用于表示后台角色新增的权限 ,供权限框架使用;
Tip
: 目前相关表定义的字段,只是最基础的 RBAC 模型,后续随着业务功能的迭代,如果当前表结构无法满足业务需求,到时候,我们再继续更新表结构。
关联表
接着是,用户角色关联表、角色权限关联,建表语句如下:
CREATE TABLE `t_user_role_rel` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` bigint unsigned NOT NULL COMMENT '用户ID',
`role_id` bigint unsigned NOT NULL COMMENT '角色ID',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`is_deleted` bit(1) NOT NULL DEFAULT b'0' COMMENT '逻辑删除(0:未删除 1:已删除)',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户角色表';
CREATE TABLE `t_role_permission_rel` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`role_id` bigint unsigned NOT NULL COMMENT '角色ID',
`permission_id` bigint unsigned NOT NULL COMMENT '权限ID',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
`is_deleted` bit(1) NOT NULL DEFAULT b'0' COMMENT '逻辑删除(0:未删除 1:已删除)',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户权限表';
架构设计
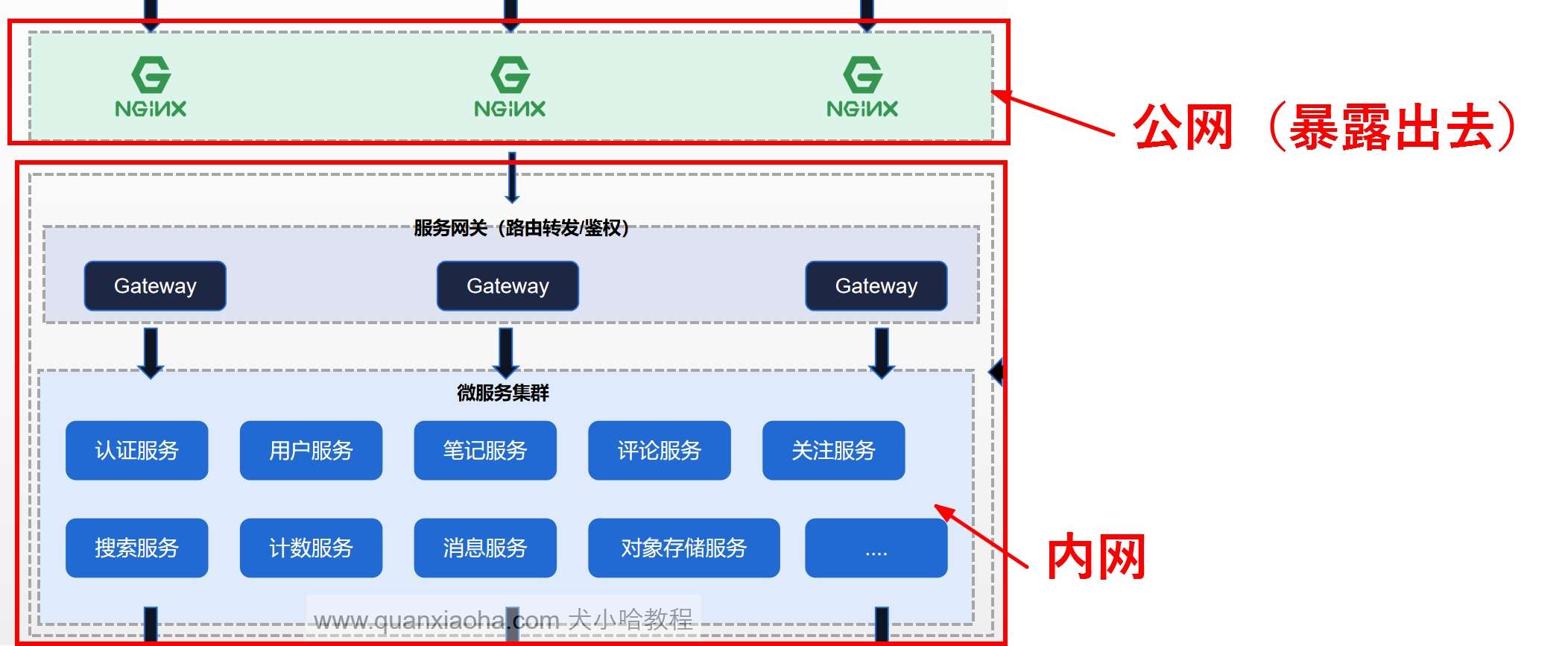
表设计完成后,我们来说说鉴权的架构设计。通常来说,生产环境中,微服务通常都会部署在内网环境中,外网无法直接访问,想要访问相关服务,必须通过暴露在公网的 Ngnix 集群来反向代理到网关,再由网关统一进行转发,打到具体的服务上,如下图所示:
鉴权放哪里合适?
关于用户认证(登录),我们已经知道是通过认证服务来处理。那么问题来了,鉴权在哪一层处理呢?通常来说,有以下 3 种方案:
-
每个微服务各自鉴权;
-
网关统一鉴权;
-
混合策略;
缺点对比
第一种方案:每个微服务各自鉴权
| 优点 | 缺点 |
|---|---|
| 分散负载:每个微服务自己处理鉴权请求,可以分散系统负载,避免单点瓶颈。 | 重复代码:每个微服务都需要实现鉴权逻辑,导致代码重复,维护成本增加。 |
| 独立性强:微服务独立进行鉴权,不依赖于其他服务,减少了系统之间的耦合度。 | 不一致性风险:不同服务间可能存在鉴权逻辑不一致的风险,影响系统整体安全性。 |
| 灵活性高:每个微服务可以根据自身特点和需求定制鉴权逻辑,灵活性更高。 | 增加开发和部署复杂度:每个微服务都需要处理鉴权,增加了开发和部署的复杂度。 |
第二种方案:网关统一鉴权
| 优点 | 缺点 |
|---|---|
| 集中管理:鉴权逻辑集中在网关,易于管理和维护,避免了代码重复和不一致性风险。 | 单点瓶颈:网关成为鉴权的单点,如果网关出现性能瓶颈或故障,会影响整个系统的可用性。 |
| 简化微服务:微服务不需要处理鉴权逻辑,专注于业务逻辑开发,简化了微服务的开发和维护。 | 复杂性增加:网关需要处理大量的鉴权请求,增加了网关的实现和维护复杂度。 |
| 性能优化:统一鉴权可以利用缓存、负载均衡等技术优化性能,提升系统整体效率。 | 延迟增加:所有请求都要经过网关进行鉴权,可能会增加请求的响应时间。 |
第三种方案:混合策略
在实际项目中,也可以采用混合策略,即在网关进行初步鉴权,进行粗粒度的控制,然后在关键微服务中进行细粒度的二次鉴权。这种方式可以兼顾性能和安全性。
最终选择的方案
本项目中,我们将采用混合策略的方案。因为小红书属于 To C 的产品,普通用户是核心,我们需要保证这块的服务尽可能的稳定。而普通用户的鉴权策略又比较简单,基本上线后就不用太频繁迭代了,所以将普通用户的鉴权统一放到网关层。至于管理后台,到时候我们再拆分一个服务,管理员、运营人员的鉴权较为复杂的,单独放到这个服务中去处理。
权限数据获取方案?
大致有如下 4 种方案:
-
-
网关自己集成 ORM 框架,如 MyBatis, 直接操作数据库查询;
优点:
- 实时性强:每次请求都会从数据库中获取最新的权限数据,保证数据的实时性和准确性。
- 简化架构:不需要额外的缓存层或远程调用,直接通过 ORM 框架操作数据库,结构简单。
缺点:
- 性能瓶颈:每次请求都要访问数据库,容易导致数据库压力过大,性能下降,特别是并发量高时。
- 可扩展性差:随着用户和权限数据的增多,数据库可能成为瓶颈,扩展性较差。
-
-
-
网关先从 Redis 中获取权限数据,若获取不到,再从数据库查询;
优点:
- 提高性能:大部分请求可以直接从 Redis 中获取权限数据,减轻数据库负担,提高响应速度。
- 降低数据库压力:减少直接访问数据库的频率,通过缓存分流,提高系统稳定性。
缺点:
- 数据一致性问题:缓存中的数据可能不是最新的,需要设计缓存更新机制(如缓存失效策略)。
- 复杂性增加:需要额外处理缓存的维护和更新逻辑,增加了系统的复杂性。
-
-
-
网关先从 Redis 中获取权限数据,若获取不到,走 RPC 调用权限服务获取数据;
优点:
- 提高性能:大部分请求可以从 Redis 获取,减轻数据库和权限服务的负担。
- 服务解耦:通过 RPC 调用权限服务获取数据,网关和权限服务解耦,提高系统的灵活性和可维护性。
缺点:
- 网络开销:每次缓存未命中的情况下,需要进行远程调用,增加了网络通信的开销。
- 系统复杂性:引入了 RPC 调用机制,需要处理服务之间的通信和容错机制,增加了系统的复杂性。
-
-
-
网关只从 Redis 中获取权限数据;
优点:
- 极高性能:所有请求都从 Redis 中获取数据,极大提升了响应速度和系统性能。
- 减轻数据库压力:完全不访问数据库,数据库的负载压力最小。
缺点:
- 数据一致性:必须确保 Redis 中的权限数据及时更新,否则可能出现数据不一致问题。
- 单点故障风险:如果 Redis 出现问题(如宕机),整个系统的权限获取都会受到影响,需要考虑高可用和容灾机制。
-
最终选择的方案
本项目中,我们将采用第四种方案,只从 Redis 中获取权限数据,以保证网关拥有更高的吞吐量。