7.5 KiB
title, url, publishedTime
| title | url | publishedTime |
|---|---|---|
| 消息中间件(MQ) 介绍与技术选型 - 犬小哈专栏 | https://www.quanxiaoha.com/column/10351.html | null |
在上小节 中的末尾,给大家留了一个小思考,关于笔记更新接口中,缓存更新是否存在问题?现在揭晓答案,是有问题的 —— 目前的方案,本地缓存更新会存在数据一致性的问题,如下图所示:
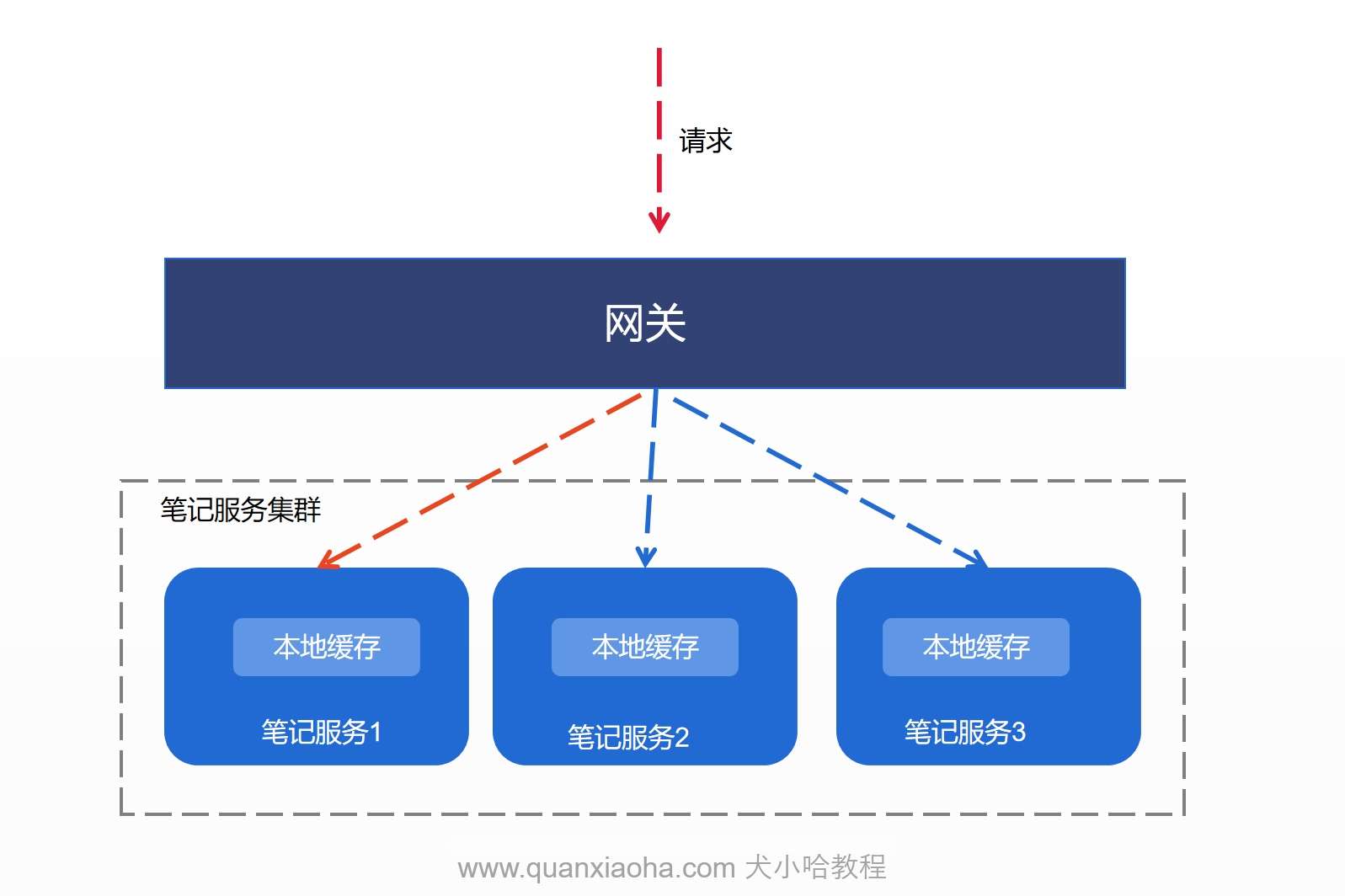
假设生产环境中,我们部署了三台笔记服务,形成了一个集群,当用户更新笔记时,请求打到网关,网关将该请求转发到集群中某个实例上,比如转发到了服务实例 1,按照此逻辑,只有实例1会将本地缓存删除,另外两个实例的本地缓存依然存在(缓存里还是更新之前的老数据)。
后续,当请求笔记详情接口时,如果被转发到另外两台服务实例上时,数据还是本地缓存中的老数据,就出现了数据不一致的问题。
如何解决呢?我们可以在笔记更新成功后,发送一条 MQ 消息, 三个实例均订阅该消息,它们都能接收到笔记更新成功事件,以将本地缓存删除。
什么是 MQ
消息中间件(Message Queue, MQ)是一种软件基础设施,用于在分布式系统中实现异步通信和解耦合。它允许应用程序通过消息队列发送和接收数据,从而实现不同组件之间的通信。
基本概念
-
消息:数据的最小单位,通常是应用程序之间传递的信息。
-
队列:一种数据结构,用于存储消息。消息按顺序进入队列,并按顺序被处理。
-
生产者(Producer):发送消息的一方。
-
消费者(Consumer):接收和处理消息的一方。
通信模型
消息中间件通常遵循两种通信模型:
-
点对点模型(Point-to-Point, P2P):在P2P模型中,每条消息只能被一个消费者消费。一旦消息被某个消费者处理后,就不再可用。这种模型适用于一对一的情况,比如发送任务给工作者节点。类似于单独给某人发送手机短信,只有指定的人才能收到:
-
发布/订阅模型(广播)(Publish/Subscribe, Pub/Sub):在Pub/Sub模型中,生产者发布消息到主题,任何订阅了该主题的消费者都会接收到消息。这种模型允许一对多的通信,即多个消费者可以监听同一个主题。类似于学校广播通知,所有同学都能接收到:


适用场景
-
异步处理:当任务需要较长时间处理时,MQ 允许应用程序将任务放入队列,并立即返回响应。任务将由消费者异步处理,避免阻塞主线程。
-
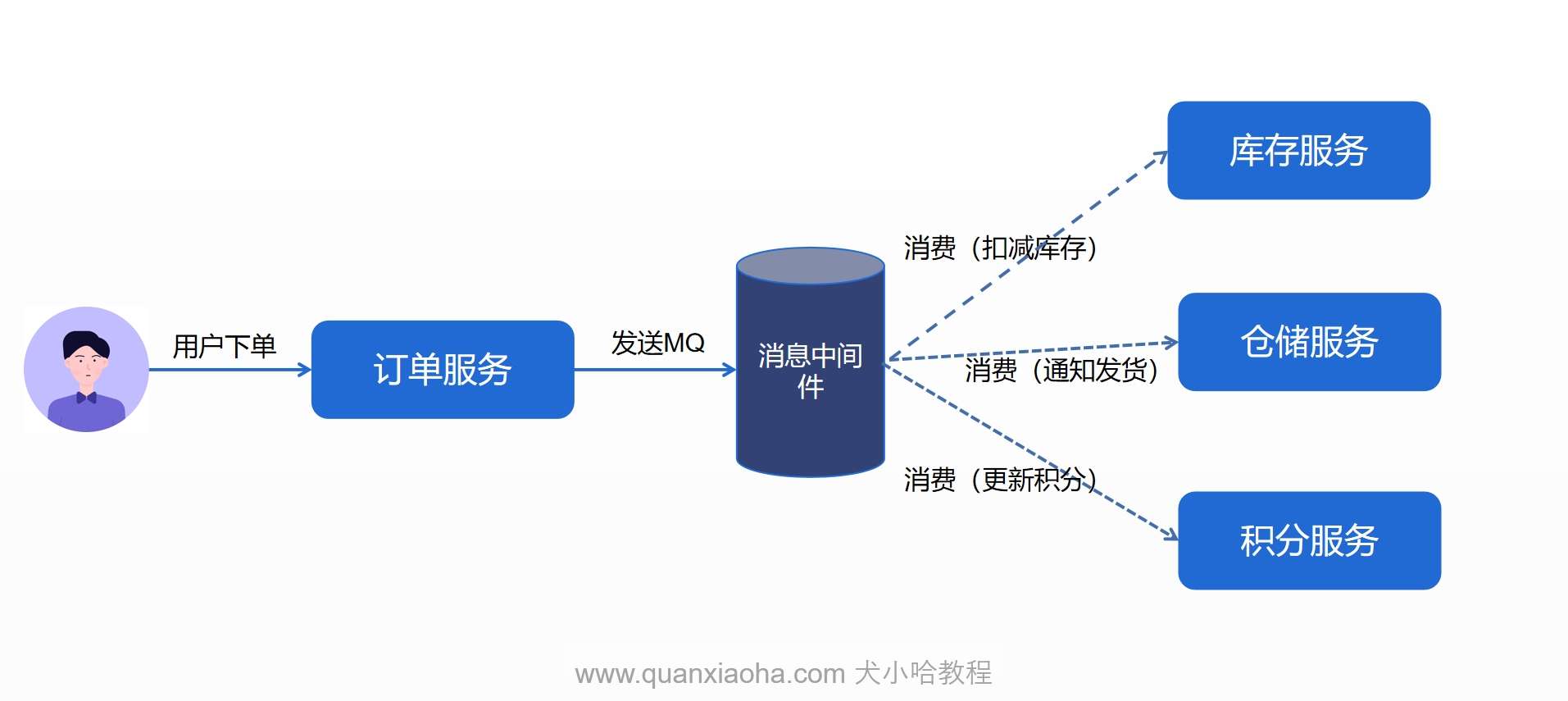
解耦应用程序:在一个复杂的系统中,不同的模块或服务可能需要进行通信。MQ 可以帮助解耦这些模块,使它们独立运行,彼此之间通过消息传递进行通信。典型的场景就是用户下单,下单后需要扣减库存、增加用户积分、通知发货等等,订单系统只需要发送一条 MQ, 即可通知对应系统处理相关逻辑。
-
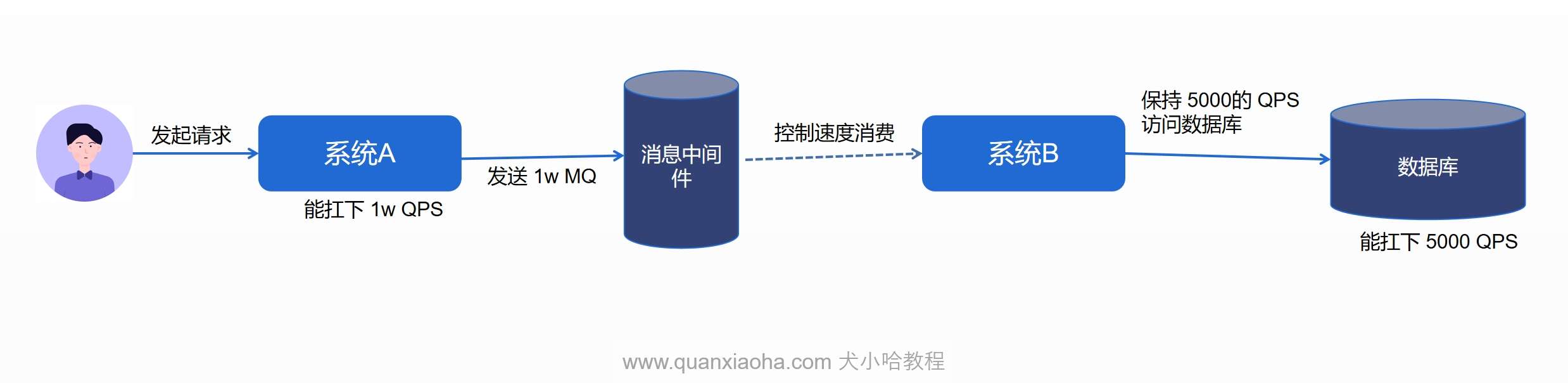
流量削峰:在高并发场景下,瞬时请求量可能会超过系统的处理能力。MQ 可以暂时缓存这些请求,平滑处理压力。比较典型的场景就是短视频点赞,某条短视频爆火,短时间内引起大量用户点赞,流量巨大,直接操作数据,会打垮数据库。可以通过引入 MQ, 用户点赞后,直接发送一条消息,消费者按一定速率慢慢处理(削峰),防止数据库压力过大。
-
日志处理:MQ 常用于收集和处理日志信息,例如分布式系统中的日志数据集中处理。
-
事件驱动系统:MQ 可以在事件驱动架构中作为事件触发的中介,使系统能够对事件做出实时响应。
流行的 MQ 对比
| 维度 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 协议支持 | AMQP, MQTT, STOMP, OpenWire, etc. | AMQP, MQTT, STOMP, HTTP, WebSockets | RocketMQ native protocol, HTTP, etc. | Kafka native protocol |
| 消息模型 | Queue, Topic, Virtual Topic, etc. | Queue, Topic | Queue, Topic | Topic, Partition, Consumer Groups |
| 持久化机制 | 支持多种持久化方案,如 KahaDB, JDBC | 支持持久化,通过插件可支持多种方式 | 文件存储,支持高效的顺序写 | 基于磁盘的日志存储,高效顺序写 |
| 吞吐量 | 中等,适合中小规模业务 | 中等偏高,适合中小规模业务 | 高吞吐量,适合大规模业务 | 极高,适合超大规模实时流处理 |
| 消息延迟 | 低至中,视配置而定 | 低至中,视配置而定 | 低延迟,适合实时消息传输 | 极低,适合实时数据流 |
| 消息顺序 | 支持,但需配置 | 支持,需配置 | 支持严格顺序 | 支持分区内严格顺序 |
| 消息保序性 | 支持,按 Topic 或 Queue 保序 | 支持,按 Queue 保序 | 支持,按 Topic 保序 | 支持,按 Partition 保序 |
| 事务支持 | 支持分布式事务 (XA) | 支持,带内嵌事务 | 原生支持分布式事务 | 部分支持,通过幂等实现 |
| 扩展性 | 中等,支持集群扩展 | 中等,支持集群扩展 | 高扩展性,支持水平扩展 | 极高,天然支持水平扩展 |
| 易用性 | 简单,文档丰富 | 简单,文档丰富 | 需要一定的学习成本 | 学习成本高 |
| 社区支持与生态 | 社区活跃不太高 | 社区非常活跃,插件极多 | 国内社区活跃,阿里巴巴开发维护 | 社区活跃,生态极为丰富 |
| 可靠性 | 高,支持多种持久化及备份策略 | 高,具备多种消息确认机制 | 高,企业级消息中间件,支持消息堆积 | 非常高,分布式架构,支持冗余和故障恢复 |
| 消息丢失风险 | 较低,可配置保证 | 较低,支持消息持久化及确认机制 | 非常低,支持事务消息 | 非常低,支持副本机制 |
| 管理工具 | 提供 Web 管理界面 | 提供 Web 管理界面 | 提供命令行工具和 Web 界面 | 提供 CLI 工具及第三方 Web 界面 |
| 典型应用场景 | 适合中小企业的应用集成及轻量级任务 | 广泛用于微服务架构与实时数据处理 | 适合大规模分布式系统及企业级应用 | 适合大数据、日志收集、实时分析 |
| 开发语言 | Java | Erlang | Java | Scala, Java |
| 商业支持 | 提供商业支持 | 提供商业支持 | 提供商业支持 | 提供商业支持,Confluent 提供支持 |
选择建议:
- ActiveMQ 适合中小企业的应用集成和轻量级任务,支持多种协议,配置和使用相对简单。
- RabbitMQ 适合微服务架构和实时数据处理,具有高可用性和丰富的插件支持,社区非常活跃。
- RocketMQ 适合大规模分布式系统,支持事务和消息堆积,阿里巴巴主导,适合需要高性能和低延迟的场景。
- Kafka 适合超大规模的实时流数据处理,大数据处理的首选,具有极高的吞吐量和低延迟,但学习成本较高。
在小哈书这个项目中,关于消息中间件,我们最终技术选型 RocketMQ 。