533 lines
15 KiB
Markdown
533 lines
15 KiB
Markdown
|
||
<p align="center"><strong><a href="./qita/join.md">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!</strong></p>
|
||
|
||
# 99. 岛屿数量
|
||
|
||
[卡码网题目链接(ACM模式)](https://kamacoder.com/problempage.php?pid=1171)
|
||
|
||
|
||
题目描述:
|
||
|
||
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
|
||
|
||
输入描述:
|
||
|
||
第一行包含两个整数 N, M,表示矩阵的行数和列数。
|
||
|
||
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
|
||
|
||
输出描述:
|
||
|
||
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
|
||
|
||
输入示例:
|
||
|
||
```
|
||
4 5
|
||
1 1 0 0 0
|
||
1 1 0 0 0
|
||
0 0 1 0 0
|
||
0 0 0 1 1
|
||
```
|
||
|
||
输出示例:
|
||
|
||
3
|
||
|
||
提示信息
|
||
|
||
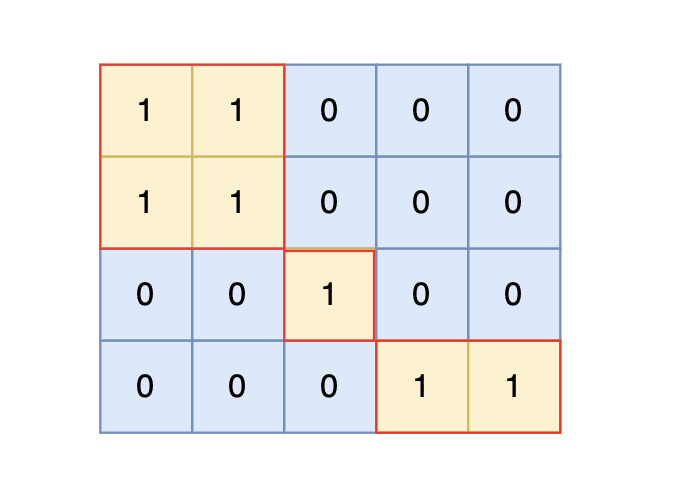
|
||
|
||
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
|
||
|
||
数据范围:
|
||
|
||
* 1 <= N, M <= 50
|
||
|
||
## 思路
|
||
|
||
**[《代码随想录》算法视频公开课](https://programmercarl.com/other/gongkaike.html):[图论:来用深搜解决一道题目,两种深搜写法,你掉坑了吗? | 卡码网:99.岛屿数量](https://www.bilibili.com/video/BV18PRGYcEiB/),相信结合视频再看本篇题解,更有助于大家对本题的理解**。
|
||
|
||
注意题目中每座岛屿只能由**水平方向和/或竖直方向上**相邻的陆地连接形成。
|
||
|
||
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:
|
||
|
||
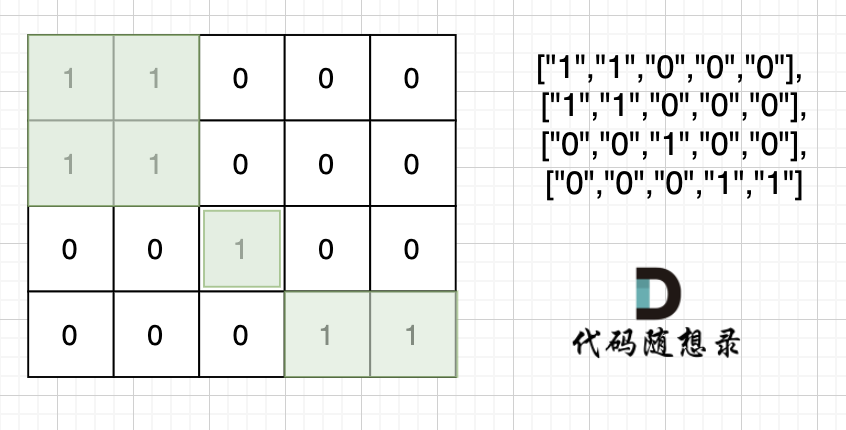
|
||
|
||
这道题题目是 DFS,BFS,并查集,基础题目。
|
||
|
||
本题思路,是用遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
|
||
|
||
在遇到标记过的陆地节点和海洋节点的时候直接跳过。 这样计数器就是最终岛屿的数量。
|
||
|
||
那么如何把节点陆地所能遍历到的陆地都标记上呢,就可以使用 DFS,BFS或者并查集。
|
||
|
||
### 深度优先搜索
|
||
|
||
以下代码使用dfs实现,如果对dfs不太了解的话,**建议按照代码随想录的讲解顺序学习**。
|
||
|
||
C++代码如下:
|
||
|
||
```CPP
|
||
// 版本一
|
||
#include <iostream>
|
||
#include <vector>
|
||
using namespace std;
|
||
|
||
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
|
||
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {
|
||
for (int i = 0; i < 4; i++) {
|
||
int nextx = x + dir[i][0];
|
||
int nexty = y + dir[i][1];
|
||
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
|
||
if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) { // 没有访问过的 同时 是陆地的
|
||
|
||
visited[nextx][nexty] = true;
|
||
dfs(grid, visited, nextx, nexty);
|
||
}
|
||
}
|
||
}
|
||
|
||
int main() {
|
||
int n, m;
|
||
cin >> n >> m;
|
||
vector<vector<int>> grid(n, vector<int>(m, 0));
|
||
for (int i = 0; i < n; i++) {
|
||
for (int j = 0; j < m; j++) {
|
||
cin >> grid[i][j];
|
||
}
|
||
}
|
||
|
||
vector<vector<bool>> visited(n, vector<bool>(m, false));
|
||
|
||
int result = 0;
|
||
for (int i = 0; i < n; i++) {
|
||
for (int j = 0; j < m; j++) {
|
||
if (!visited[i][j] && grid[i][j] == 1) {
|
||
visited[i][j] = true;
|
||
result++; // 遇到没访问过的陆地,+1
|
||
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
|
||
}
|
||
}
|
||
}
|
||
|
||
cout << result << endl;
|
||
}
|
||
```
|
||
|
||
很多录友可能有疑惑,为什么 以上代码中的dfs函数,没有终止条件呢? 感觉递归没有终止很危险。
|
||
|
||
其实终止条件 就写在了 调用dfs的地方,如果遇到不合法的方向,直接不会去调用dfs。
|
||
|
||
当然也可以这么写:
|
||
|
||
```CPP
|
||
// 版本二
|
||
#include <iostream>
|
||
#include <vector>
|
||
using namespace std;
|
||
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
|
||
void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {
|
||
if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水
|
||
visited[x][y] = true; // 标记访问过
|
||
for (int i = 0; i < 4; i++) {
|
||
int nextx = x + dir[i][0];
|
||
int nexty = y + dir[i][1];
|
||
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
|
||
dfs(grid, visited, nextx, nexty);
|
||
}
|
||
}
|
||
|
||
int main() {
|
||
int n, m;
|
||
cin >> n >> m;
|
||
vector<vector<int>> grid(n, vector<int>(m, 0));
|
||
for (int i = 0; i < n; i++) {
|
||
for (int j = 0; j < m; j++) {
|
||
cin >> grid[i][j];
|
||
}
|
||
}
|
||
|
||
vector<vector<bool>> visited(n, vector<bool>(m, false));
|
||
|
||
int result = 0;
|
||
for (int i = 0; i < n; i++) {
|
||
for (int j = 0; j < m; j++) {
|
||
if (!visited[i][j] && grid[i][j] == 1) {
|
||
result++; // 遇到没访问过的陆地,+1
|
||
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
|
||
}
|
||
}
|
||
}
|
||
cout << result << endl;
|
||
}
|
||
```
|
||
|
||
这里大家应该能看出区别了,无疑就是版本一中 调用dfs 的条件判断 放在了 版本二 的 终止条件位置上。
|
||
|
||
**版本一的写法**是 :下一个节点是否能合法已经判断完了,传进dfs函数的就是合法节点。
|
||
|
||
**版本二的写法**是:不管节点是否合法,上来就dfs,然后在终止条件的地方进行判断,不合法再return。
|
||
|
||
**理论上来讲,版本一的效率更高一些**,因为避免了 没有意义的递归调用,在调用dfs之前,就做合法性判断。 但从写法来说,可能版本二 更利于理解一些。(不过其实都差不太多)
|
||
|
||
很多同学看了同一道题目,都是dfs,写法却不一样,**有时候有终止条件,有时候连终止条件都没有,其实这就是根本原因,两种写法而已**。
|
||
|
||
|
||
## 总结
|
||
|
||
其实本题是 dfs,bfs 模板题,但正是因为是模板题,所以大家或者一些题解把重要的细节都很忽略了,我这里把大家没注意的但以后会踩的坑 都给列出来了。
|
||
|
||
本篇我只给出的dfs的写法,大家发现我写的还是比较细的,那么后面我再单独给出本题的bfs写法,虽然是模板题,但依然有很多注意的点,敬请期待!
|
||
|
||
|
||
## 其他语言版本
|
||
|
||
### Java
|
||
```java
|
||
import java.util.Scanner;
|
||
|
||
public class Main {
|
||
public static int[][] dir ={{0,1},{1,0},{-1,0},{0,-1}};
|
||
public static void dfs(boolean[][] visited,int x,int y ,int [][]grid)
|
||
{
|
||
for (int i = 0; i < 4; i++) {
|
||
int nextX=x+dir[i][0];
|
||
int nextY=y+dir[i][1];
|
||
if(nextY<0||nextX<0||nextX>= grid.length||nextY>=grid[0].length)
|
||
continue;
|
||
if(!visited[nextX][nextY]&&grid[nextX][nextY]==1)
|
||
{
|
||
visited[nextX][nextY]=true;
|
||
dfs(visited,nextX,nextY,grid);
|
||
}
|
||
}
|
||
}
|
||
public static void main(String[] args) {
|
||
Scanner sc = new Scanner(System.in);
|
||
int m= sc.nextInt();
|
||
int n = sc.nextInt();
|
||
int[][] grid = new int[m][n];
|
||
for (int i = 0; i < m; i++) {
|
||
for (int j = 0; j < n; j++) {
|
||
grid[i][j]=sc.nextInt();
|
||
}
|
||
}
|
||
boolean[][]visited =new boolean[m][n];
|
||
int ans = 0;
|
||
for (int i = 0; i < m; i++) {
|
||
for (int j = 0; j < n; j++) {
|
||
if(!visited[i][j]&&grid[i][j]==1)
|
||
{
|
||
ans++;
|
||
visited[i][j]=true;
|
||
dfs(visited,i,j,grid);
|
||
}
|
||
}
|
||
}
|
||
System.out.println(ans);
|
||
}
|
||
}
|
||
|
||
```
|
||
### Python
|
||
|
||
版本一
|
||
|
||
```python
|
||
direction = [[0, 1], [1, 0], [0, -1], [-1, 0]] # 四个方向:上、右、下、左
|
||
|
||
|
||
def dfs(grid, visited, x, y):
|
||
"""
|
||
对一块陆地进行深度优先遍历并标记
|
||
"""
|
||
for i, j in direction:
|
||
next_x = x + i
|
||
next_y = y + j
|
||
# 下标越界,跳过
|
||
if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):
|
||
continue
|
||
# 未访问的陆地,标记并调用深度优先搜索
|
||
if not visited[next_x][next_y] and grid[next_x][next_y] == 1:
|
||
visited[next_x][next_y] = True
|
||
dfs(grid, visited, next_x, next_y)
|
||
|
||
|
||
if __name__ == '__main__':
|
||
# 版本一
|
||
n, m = map(int, input().split())
|
||
|
||
# 邻接矩阵
|
||
grid = []
|
||
for i in range(n):
|
||
grid.append(list(map(int, input().split())))
|
||
|
||
# 访问表
|
||
visited = [[False] * m for _ in range(n)]
|
||
|
||
res = 0
|
||
for i in range(n):
|
||
for j in range(m):
|
||
# 判断:如果当前节点是陆地,res+1并标记访问该节点,使用深度搜索标记相邻陆地。
|
||
if grid[i][j] == 1 and not visited[i][j]:
|
||
res += 1
|
||
visited[i][j] = True
|
||
dfs(grid, visited, i, j)
|
||
|
||
print(res)
|
||
```
|
||
|
||
版本二
|
||
|
||
```python
|
||
direction = [[0, 1], [1, 0], [0, -1], [-1, 0]] # 四个方向:上、右、下、左
|
||
|
||
|
||
def dfs(grid, visited, x, y):
|
||
"""
|
||
对一块陆地进行深度优先遍历并标记
|
||
"""
|
||
# 与版本一的差别,在调用前增加判断终止条件
|
||
if visited[x][y] or grid[x][y] == 0:
|
||
return
|
||
visited[x][y] = True
|
||
|
||
for i, j in direction:
|
||
next_x = x + i
|
||
next_y = y + j
|
||
# 下标越界,跳过
|
||
if next_x < 0 or next_x >= len(grid) or next_y < 0 or next_y >= len(grid[0]):
|
||
continue
|
||
# 由于判断条件放在了方法首部,此处直接调用dfs方法
|
||
dfs(grid, visited, next_x, next_y)
|
||
|
||
|
||
if __name__ == '__main__':
|
||
# 版本二
|
||
n, m = map(int, input().split())
|
||
|
||
# 邻接矩阵
|
||
grid = []
|
||
for i in range(n):
|
||
grid.append(list(map(int, input().split())))
|
||
|
||
# 访问表
|
||
visited = [[False] * m for _ in range(n)]
|
||
|
||
res = 0
|
||
for i in range(n):
|
||
for j in range(m):
|
||
# 判断:如果当前节点是陆地,res+1并标记访问该节点,使用深度搜索标记相邻陆地。
|
||
if grid[i][j] == 1 and not visited[i][j]:
|
||
res += 1
|
||
dfs(grid, visited, i, j)
|
||
|
||
print(res)
|
||
```
|
||
|
||
### Go
|
||
|
||
我们使用一个visited数组,记录下那些位置被遍历过。分为两层遍历。初始化一个visited数组和原始的grid一样大,用来记录哪些陆地被遍历过
|
||
|
||
第一层遍历遍历整个grid数组的元素,遇到陆地,就在对应的visited数组里标记,并且执行深度搜索,深搜的逻辑是把当前位置的4个方向上的位置,全部判断一遍看是不是陆地,如果是,则在这个位置上再执行深搜,达到递归深搜的效果。所以深搜函数里是递归的。
|
||
|
||
```go
|
||
package main
|
||
|
||
import (
|
||
"fmt"
|
||
)
|
||
|
||
func visitIsland(grid [][]int) int {
|
||
row := len(grid)
|
||
if row == 0 {
|
||
return 0
|
||
}
|
||
visited := make([][]bool, row)
|
||
//go的这种初始化方式真的丑陋
|
||
for i := 0; i < row; i++ {
|
||
visited[i] = make([]bool, len(grid[0]))
|
||
}
|
||
ans := 0
|
||
for i := 0; i < row; i++ {
|
||
for j := 0; j < len(grid[0]); j++ {
|
||
if grid[i][j] == 1 && !visited[i][j] {
|
||
visited[i][j] = true
|
||
ans++
|
||
visitGrid(grid, visited, i, j)
|
||
}
|
||
}
|
||
}
|
||
return ans
|
||
}
|
||
|
||
func visitGrid(grid [][]int, visited [][]bool, x int, y int) {
|
||
diff := [4][2]int{{1, 0}, {-1, 0}, {0, 1}, {0, -1}}
|
||
for _, arr := range diff {
|
||
nextX := x + arr[0]
|
||
nextY := y + arr[1]
|
||
if nextX < 0 || nextX >= len(grid) || nextY < 0 || nextY >= len(grid[0]) {
|
||
continue
|
||
}
|
||
if !visited[nextX][nextY] && grid[nextX][nextY] == 1 {
|
||
visited[nextX][nextY] = true
|
||
visitGrid(grid, visited, nextX, nextY)
|
||
}
|
||
}
|
||
}
|
||
|
||
func main() {
|
||
var row, col int
|
||
fmt.Scan(&row, &col)
|
||
if row <=0 || col <=0 {
|
||
return
|
||
}
|
||
grid := make([][]int, row)
|
||
for i := 0; i < row; i++ {
|
||
grid[i] = make([]int, col)
|
||
}
|
||
for i := 0; i < row; i++ {
|
||
for j := 0; j < col; j++ {
|
||
fmt.Scan(&grid[i][j])
|
||
}
|
||
}
|
||
//这里必须要打印,不然报错会显示潜在的数组越界
|
||
fmt.Println(visitIsland(grid))
|
||
}
|
||
```
|
||
|
||
### Rust
|
||
|
||
### JavaScript
|
||
|
||
```javascript
|
||
const r1 = require('readline').createInterface({ input: process.stdin });
|
||
// 创建readline接口
|
||
let iter = r1[Symbol.asyncIterator]();
|
||
// 创建异步迭代器
|
||
const readline = async () => (await iter.next()).value;
|
||
|
||
let graph
|
||
let N, M
|
||
let visited
|
||
let result = 0
|
||
const dir = [[0, 1], [1, 0], [0, -1], [-1, 0]]
|
||
|
||
// 读取输入,初始化地图
|
||
const initGraph = async () => {
|
||
let line = await readline();
|
||
[N, M] = line.split(' ').map(Number);
|
||
graph = new Array(N).fill(0).map(() => new Array(M).fill(0))
|
||
visited = new Array(N).fill(false).map(() => new Array(M).fill(false))
|
||
|
||
for (let i = 0; i < N; i++) {
|
||
line = await readline()
|
||
line = line.split(' ').map(Number)
|
||
for (let j = 0; j < M; j++) {
|
||
graph[i][j] = line[j]
|
||
}
|
||
}
|
||
}
|
||
|
||
/**
|
||
* @description: 从节点x,y开始深度优先遍历
|
||
* @param {*} graph 是地图,也就是一个二维数组
|
||
* @param {*} visited 标记访问过的节点,不要重复访问
|
||
* @param {*} x 表示开始搜索节点的下标
|
||
* @param {*} y 表示开始搜索节点的下标
|
||
* @return {*}
|
||
*/
|
||
const dfs = (graph, visited, x, y) => {
|
||
for (let i = 0; i < 4; i++) {
|
||
const nextx = x + dir[i][0]
|
||
const nexty = y + dir[i][1]
|
||
if (nextx < 0 || nextx >= N || nexty < 0 || nexty >= M) continue
|
||
if (!visited[nextx][nexty] && graph[nextx][nexty] === 1) {
|
||
visited[nextx][nexty] = true
|
||
dfs(graph, visited, nextx, nexty)
|
||
}
|
||
}
|
||
}
|
||
|
||
(async function () {
|
||
|
||
// 读取输入,初始化地图
|
||
await initGraph()
|
||
|
||
// 统计岛屿数
|
||
for (let i = 0; i < N; i++) {
|
||
for (let j = 0; j < M; j++) {
|
||
if (!visited[i][j] && graph[i][j] === 1) {
|
||
// 标记已访问
|
||
visited[i][j] = true
|
||
|
||
// 遇到没访问过的陆地,+1
|
||
result++
|
||
|
||
// 深度优先遍历,将相邻陆地标记为已访问
|
||
dfs(graph, visited, i, j)
|
||
}
|
||
}
|
||
}
|
||
console.log(result);
|
||
})()
|
||
```
|
||
|
||
|
||
|
||
### TypeScript
|
||
|
||
### PhP
|
||
|
||
### Swift
|
||
|
||
### Scala
|
||
```scala
|
||
import util.control.Breaks._
|
||
|
||
object Solution {
|
||
val dir = List((-1,0), (0,-1), (1,0), (0,1)) // 四个方向
|
||
|
||
def dfs(grid: Array[Array[Char]], visited: Array[Array[Boolean]], row: Int, col: Int): Unit = {
|
||
(0 until 4).map { x =>
|
||
val nextR = row + dir(x)(0)
|
||
val nextC = col + dir(x)(1)
|
||
breakable {
|
||
if(nextR < 0 || nextR >= grid.length || nextC < 0 || nextC >= grid(0).length) break
|
||
if (!visited(nextR)(nextC) && grid(nextR)(nextC) == '1') {
|
||
visited(nextR)(nextC) = true // 经过就记录
|
||
dfs(grid, visited, nextR, nextC)
|
||
}
|
||
}
|
||
}
|
||
}
|
||
|
||
def numIslands(grid: Array[Array[Char]]): Int = {
|
||
val row = grid.length
|
||
val col = grid(0).length
|
||
var visited = Array.fill(row)(Array.fill(col)(false))
|
||
var counter = 0
|
||
|
||
(0 until row).map{ r =>
|
||
(0 until col).map{ c =>
|
||
if (!visited(r)(c) && grid(r)(c) == '1') {
|
||
visited(r)(c) = true // 经过就记录
|
||
dfs(grid, visited, r, c)
|
||
counter += 1
|
||
}
|
||
}
|
||
}
|
||
|
||
counter
|
||
}
|
||
}
|
||
```
|
||
|
||
### C#
|
||
|
||
### Dart
|
||
|
||
### C
|
||
|