611 lines
20 KiB
Markdown
Executable File
611 lines
20 KiB
Markdown
Executable File
* [做项目(多个C++、Java、Go、测开、前端项目)](https://www.programmercarl.com/other/kstar.html)
|
||
* [刷算法(两个月高强度学算法)](https://www.programmercarl.com/xunlian/xunlianying.html)
|
||
* [背八股(40天挑战高频面试题)](https://www.programmercarl.com/xunlian/bagu.html)
|
||
|
||
|
||
> 前K个大数问题,老生常谈,不得不谈
|
||
|
||
# 347.前 K 个高频元素
|
||
|
||
[力扣题目链接](https://leetcode.cn/problems/top-k-frequent-elements/)
|
||
|
||
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
|
||
|
||
示例 1:
|
||
* 输入: nums = [1,1,1,2,2,3], k = 2
|
||
* 输出: [1,2]
|
||
|
||
示例 2:
|
||
* 输入: nums = [1], k = 1
|
||
* 输出: [1]
|
||
|
||
提示:
|
||
* 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
|
||
* 你的算法的时间复杂度必须优于 $O(n \log n)$ , n 是数组的大小。
|
||
* 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
|
||
* 你可以按任意顺序返回答案。
|
||
|
||
## 算法公开课
|
||
|
||
**[《代码随想录》算法视频公开课](https://programmercarl.com/other/gongkaike.html):[优先级队列正式登场!大顶堆、小顶堆该怎么用?| LeetCode:347.前 K 个高频元素](https://www.bilibili.com/video/BV1Xg41167Lz),相信结合视频再看本篇题解,更有助于大家对本题的理解**。
|
||
|
||
## 思路
|
||
|
||
这道题目主要涉及到如下三块内容:
|
||
1. 要统计元素出现频率
|
||
2. 对频率排序
|
||
3. 找出前K个高频元素
|
||
|
||
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
|
||
|
||
然后是对频率进行排序,这里我们可以使用一种 容器适配器就是**优先级队列**。
|
||
|
||
什么是优先级队列呢?
|
||
|
||
其实**就是一个披着队列外衣的堆**,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
|
||
|
||
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
|
||
|
||
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
|
||
|
||
什么是堆呢?
|
||
|
||
**堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。** 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
|
||
|
||
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
|
||
|
||
本题我们就要使用优先级队列来对部分频率进行排序。
|
||
|
||
为什么不用快排呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
|
||
|
||
此时要思考一下,是使用小顶堆呢,还是大顶堆?
|
||
|
||
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
|
||
|
||
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
|
||
|
||
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
|
||
|
||
**所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。**
|
||
|
||
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
|
||
|
||
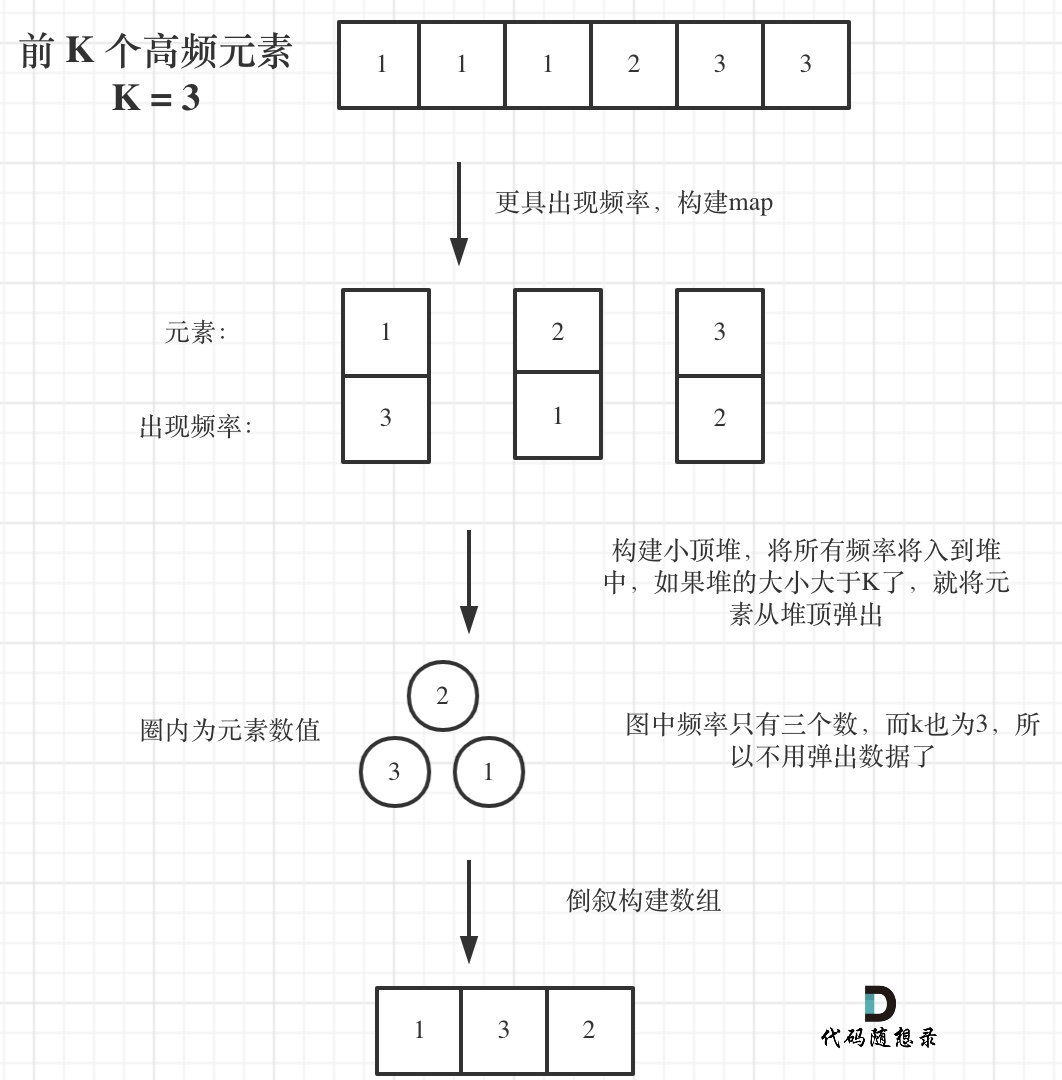
|
||
|
||
|
||
我们来看一下C++代码:
|
||
|
||
|
||
```CPP
|
||
class Solution {
|
||
public:
|
||
// 小顶堆
|
||
class mycomparison {
|
||
public:
|
||
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
|
||
return lhs.second > rhs.second;
|
||
}
|
||
};
|
||
vector<int> topKFrequent(vector<int>& nums, int k) {
|
||
// 要统计元素出现频率
|
||
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
|
||
for (int i = 0; i < nums.size(); i++) {
|
||
map[nums[i]]++;
|
||
}
|
||
|
||
// 对频率排序
|
||
// 定义一个小顶堆,大小为k
|
||
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
|
||
|
||
// 用固定大小为k的小顶堆,扫面所有频率的数值
|
||
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
|
||
pri_que.push(*it);
|
||
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
|
||
pri_que.pop();
|
||
}
|
||
}
|
||
|
||
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
|
||
vector<int> result(k);
|
||
for (int i = k - 1; i >= 0; i--) {
|
||
result[i] = pri_que.top().first;
|
||
pri_que.pop();
|
||
}
|
||
return result;
|
||
|
||
}
|
||
};
|
||
```
|
||
|
||
* 时间复杂度: O(nlogk)
|
||
* 空间复杂度: O(n)
|
||
|
||
## 拓展
|
||
大家对这个比较运算在建堆时是如何应用的,为什么左大于右就会建立小顶堆,反而建立大顶堆比较困惑。
|
||
|
||
确实 例如我们在写快排的cmp函数的时候,`return left>right` 就是从大到小,`return left<right` 就是从小到大。
|
||
|
||
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),我估计是底层实现上优先队列队首指向后面,队尾指向最前面的缘故!
|
||
|
||
|
||
## 其他语言版本
|
||
|
||
### Java:
|
||
|
||
```java
|
||
|
||
/*Comparator接口说明:
|
||
* 返回负数,形参中第一个参数排在前面;返回正数,形参中第二个参数排在前面
|
||
* 对于队列:排在前面意味着往队头靠
|
||
* 对于堆(使用PriorityQueue实现):从队头到队尾按从小到大排就是最小堆(小顶堆),
|
||
* 从队头到队尾按从大到小排就是最大堆(大顶堆)--->队头元素相当于堆的根节点
|
||
* */
|
||
class Solution {
|
||
//解法1:基于大顶堆实现
|
||
public int[] topKFrequent1(int[] nums, int k) {
|
||
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
|
||
for (int num : nums) {
|
||
map.put(num, map.getOrDefault(num,0) + 1);
|
||
}
|
||
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
|
||
//出现次数按从队头到队尾的顺序是从大到小排,出现次数最多的在队头(相当于大顶堆)
|
||
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair2[1] - pair1[1]);
|
||
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {//大顶堆需要对所有元素进行排序
|
||
pq.add(new int[]{entry.getKey(), entry.getValue()});
|
||
}
|
||
int[] ans = new int[k];
|
||
for (int i = 0; i < k; i++) { //依次从队头弹出k个,就是出现频率前k高的元素
|
||
ans[i] = pq.poll()[0];
|
||
}
|
||
return ans;
|
||
}
|
||
//解法2:基于小顶堆实现
|
||
public int[] topKFrequent2(int[] nums, int k) {
|
||
Map<Integer,Integer> map = new HashMap<>(); //key为数组元素值,val为对应出现次数
|
||
for (int num : nums) {
|
||
map.put(num, map.getOrDefault(num, 0) + 1);
|
||
}
|
||
//在优先队列中存储二元组(num, cnt),cnt表示元素值num在数组中的出现次数
|
||
//出现次数按从队头到队尾的顺序是从小到大排,出现次数最低的在队头(相当于小顶堆)
|
||
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair1[1] - pair2[1]);
|
||
for (Map.Entry<Integer, Integer> entry : map.entrySet()) { //小顶堆只需要维持k个元素有序
|
||
if (pq.size() < k) { //小顶堆元素个数小于k个时直接加
|
||
pq.add(new int[]{entry.getKey(), entry.getValue()});
|
||
} else {
|
||
if (entry.getValue() > pq.peek()[1]) { //当前元素出现次数大于小顶堆的根结点(这k个元素中出现次数最少的那个)
|
||
pq.poll(); //弹出队头(小顶堆的根结点),即把堆里出现次数最少的那个删除,留下的就是出现次数多的了
|
||
pq.add(new int[]{entry.getKey(), entry.getValue()});
|
||
}
|
||
}
|
||
}
|
||
int[] ans = new int[k];
|
||
for (int i = k - 1; i >= 0; i--) { //依次弹出小顶堆,先弹出的是堆的根,出现次数少,后面弹出的出现次数多
|
||
ans[i] = pq.poll()[0];
|
||
}
|
||
return ans;
|
||
}
|
||
}
|
||
```
|
||
简化版代码:
|
||
```java
|
||
class Solution {
|
||
public int[] topKFrequent(int[] nums, int k) {
|
||
// 优先级队列,为了避免复杂 api 操作,pq 存储数组
|
||
// lambda 表达式设置优先级队列从大到小存储 o1 - o2 为从小到大,o2 - o1 反之
|
||
PriorityQueue<int[]> pq = new PriorityQueue<>((o1, o2) -> o1[1] - o2[1]);
|
||
int[] res = new int[k]; // 答案数组为 k 个元素
|
||
Map<Integer, Integer> map = new HashMap<>(); // 记录元素出现次数
|
||
for (int num : nums) map.put(num, map.getOrDefault(num, 0) + 1);
|
||
for (var x : map.entrySet()) { // entrySet 获取 k-v Set 集合
|
||
// 将 kv 转化成数组
|
||
int[] tmp = new int[2];
|
||
tmp[0] = x.getKey();
|
||
tmp[1] = x.getValue();
|
||
pq.offer(tmp);
|
||
// 下面的代码是根据小根堆实现的,我只保留优先队列的最后的k个,只要超出了k我就将最小的弹出,剩余的k个就是答案
|
||
if(pq.size() > k) {
|
||
pq.poll();
|
||
}
|
||
}
|
||
for (int i = 0; i < k; i++) {
|
||
res[i] = pq.poll()[0]; // 获取优先队列里的元素
|
||
}
|
||
return res;
|
||
}
|
||
}
|
||
```
|
||
|
||
### Python:
|
||
解法一:
|
||
```python
|
||
#时间复杂度:O(nlogk)
|
||
#空间复杂度:O(n)
|
||
import heapq
|
||
class Solution:
|
||
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
|
||
#要统计元素出现频率
|
||
map_ = {} #nums[i]:对应出现的次数
|
||
for i in range(len(nums)):
|
||
map_[nums[i]] = map_.get(nums[i], 0) + 1
|
||
|
||
#对频率排序
|
||
#定义一个小顶堆,大小为k
|
||
pri_que = [] #小顶堆
|
||
|
||
#用固定大小为k的小顶堆,扫描所有频率的数值
|
||
for key, freq in map_.items():
|
||
heapq.heappush(pri_que, (freq, key))
|
||
if len(pri_que) > k: #如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
|
||
heapq.heappop(pri_que)
|
||
|
||
#找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
|
||
result = [0] * k
|
||
for i in range(k-1, -1, -1):
|
||
result[i] = heapq.heappop(pri_que)[1]
|
||
return result
|
||
```
|
||
解法二:
|
||
```python
|
||
class Solution:
|
||
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
|
||
# 使用字典统计数字出现次数
|
||
time_dict = defaultdict(int)
|
||
for num in nums:
|
||
time_dict[num] += 1
|
||
# 更改字典,key为出现次数,value为相应的数字的集合
|
||
index_dict = defaultdict(list)
|
||
for key in time_dict:
|
||
index_dict[time_dict[key]].append(key)
|
||
# 排序
|
||
key = list(index_dict.keys())
|
||
key.sort()
|
||
result = []
|
||
cnt = 0
|
||
# 获取前k项
|
||
while key and cnt != k:
|
||
result += index_dict[key[-1]]
|
||
cnt += len(index_dict[key[-1]])
|
||
key.pop()
|
||
|
||
return result[0: k]
|
||
```
|
||
|
||
### Go:
|
||
|
||
```go
|
||
//方法一:小顶堆
|
||
func topKFrequent(nums []int, k int) []int {
|
||
map_num:=map[int]int{}
|
||
//记录每个元素出现的次数
|
||
for _,item:=range nums{
|
||
map_num[item]++
|
||
}
|
||
h:=&IHeap{}
|
||
heap.Init(h)
|
||
//所有元素入堆,堆的长度为k
|
||
for key,value:=range map_num{
|
||
heap.Push(h,[2]int{key,value})
|
||
if h.Len()>k{
|
||
heap.Pop(h)
|
||
}
|
||
}
|
||
res:=make([]int,k)
|
||
//按顺序返回堆中的元素
|
||
for i:=0;i<k;i++{
|
||
res[k-i-1]=heap.Pop(h).([2]int)[0]
|
||
}
|
||
return res
|
||
}
|
||
|
||
//构建小顶堆
|
||
type IHeap [][2]int
|
||
|
||
func (h IHeap) Len()int {
|
||
return len(h)
|
||
}
|
||
|
||
func (h IHeap) Less (i,j int) bool {
|
||
return h[i][1]<h[j][1]
|
||
}
|
||
|
||
func (h IHeap) Swap(i,j int) {
|
||
h[i],h[j]=h[j],h[i]
|
||
}
|
||
|
||
func (h *IHeap) Push(x interface{}){
|
||
*h=append(*h,x.([2]int))
|
||
}
|
||
func (h *IHeap) Pop() interface{}{
|
||
old:=*h
|
||
n:=len(old)
|
||
x:=old[n-1]
|
||
*h=old[0:n-1]
|
||
return x
|
||
}
|
||
|
||
|
||
//方法二:利用O(nlogn)排序
|
||
func topKFrequent(nums []int, k int) []int {
|
||
ans:=[]int{}
|
||
map_num:=map[int]int{}
|
||
for _,item:=range nums {
|
||
map_num[item]++
|
||
}
|
||
for key,_:=range map_num{
|
||
ans=append(ans,key)
|
||
}
|
||
//核心思想:排序
|
||
//可以不用包函数,自己实现快排
|
||
sort.Slice(ans,func (a,b int)bool{
|
||
return map_num[ans[a]]>map_num[ans[b]]
|
||
})
|
||
return ans[:k]
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### JavaScript:
|
||
|
||
解法一:
|
||
Leetcode 提供了优先队列的库,具体文档可以参见 [@datastructures-js/priority-queue](https://github.com/datastructures-js/priority-queue/blob/v5/README.md)。
|
||
|
||
```js
|
||
var topKFrequent = function (nums, k) {
|
||
const map = new Map();
|
||
const res = [];
|
||
//使用 map 统计元素出现频率
|
||
for (const num of nums) {
|
||
map.set(num, (map.get(num) || 0) + 1);
|
||
}
|
||
//创建小顶堆
|
||
const heap = new PriorityQueue({
|
||
compare: (a, b) => a.value - b.value
|
||
})
|
||
for (const [key, value] of map) {
|
||
heap.enqueue({ key, value });
|
||
if (heap.size() > k) heap.dequeue();
|
||
}
|
||
//处理输出
|
||
while (heap.size()) res.push(heap.dequeue().key);
|
||
return res;
|
||
};
|
||
```
|
||
|
||
解法二:
|
||
手写实现优先队列
|
||
|
||
```js
|
||
// js 没有堆 需要自己构造
|
||
class Heap {
|
||
constructor(compareFn) {
|
||
this.compareFn = compareFn;
|
||
this.queue = [];
|
||
}
|
||
|
||
// 添加
|
||
push(item) {
|
||
// 推入元素
|
||
this.queue.push(item);
|
||
|
||
// 上浮
|
||
let index = this.size() - 1; // 记录推入元素下标
|
||
let parent = Math.floor((index - 1) / 2); // 记录父节点下标
|
||
|
||
while (parent >= 0 && this.compare(parent, index) > 0) { // 注意compare参数顺序
|
||
[this.queue[index], this.queue[parent]] = [this.queue[parent], this.queue[index]];
|
||
|
||
// 更新下标
|
||
index = parent;
|
||
parent = Math.floor((index - 1) / 2);
|
||
}
|
||
}
|
||
|
||
// 获取堆顶元素并移除
|
||
pop() {
|
||
// 边界情况,只有一个元素或没有元素应直接弹出
|
||
if (this.size() <= 1) {
|
||
return this.queue.pop()
|
||
}
|
||
|
||
// 堆顶元素
|
||
const out = this.queue[0];
|
||
|
||
// 移除堆顶元素 填入最后一个元素
|
||
this.queue[0] = this.queue.pop();
|
||
|
||
// 下沉
|
||
let index = 0; // 记录下沉元素下标
|
||
let left = 1; // left 是左子节点下标 left + 1 则是右子节点下标
|
||
let searchChild = this.compare(left, left + 1) > 0 ? left + 1 : left;
|
||
|
||
while (this.compare(index, searchChild) > 0) { // 注意compare参数顺序
|
||
[this.queue[index], this.queue[searchChild]] = [this.queue[searchChild], this.queue[index]];
|
||
|
||
// 更新下标
|
||
index = searchChild;
|
||
left = 2 * index + 1;
|
||
searchChild = this.compare(left, left + 1) > 0 ? left + 1 : left;
|
||
}
|
||
|
||
return out;
|
||
}
|
||
|
||
size() {
|
||
return this.queue.length;
|
||
}
|
||
|
||
// 使用传入的 compareFn 比较两个位置的元素
|
||
compare(index1, index2) {
|
||
// 处理下标越界问题
|
||
if (this.queue[index1] === undefined) return 1;
|
||
if (this.queue[index2] === undefined) return -1;
|
||
|
||
return this.compareFn(this.queue[index1], this.queue[index2]);
|
||
}
|
||
|
||
}
|
||
|
||
const topKFrequent = function (nums, k) {
|
||
const map = new Map();
|
||
|
||
for (const num of nums) {
|
||
map.set(num, (map.get(num) || 0) + 1);
|
||
}
|
||
|
||
// 创建小顶堆
|
||
const heap= new Heap((a, b) => a[1] - b[1]);
|
||
|
||
// entry 是一个长度为2的数组,0位置存储key,1位置存储value
|
||
for (const entry of map.entries()) {
|
||
heap.push(entry);
|
||
|
||
if (heap.size() > k) {
|
||
heap.pop();
|
||
}
|
||
}
|
||
|
||
// return heap.queue.map(e => e[0]);
|
||
|
||
const res = [];
|
||
|
||
for (let i = heap.size() - 1; i >= 0; i--) {
|
||
res[i] = heap.pop()[0];
|
||
}
|
||
|
||
return res;
|
||
};
|
||
```
|
||
|
||
### TypeScript:
|
||
|
||
```typescript
|
||
function topKFrequent(nums: number[], k: number): number[] {
|
||
const countMap: Map<number, number> = new Map();
|
||
for (let num of nums) {
|
||
countMap.set(num, (countMap.get(num) || 0) + 1);
|
||
}
|
||
// tS没有最小堆的数据结构,所以直接对整个数组进行排序,取前k个元素
|
||
return [...countMap.entries()]
|
||
.sort((a, b) => b[1] - a[1])
|
||
.slice(0, k)
|
||
.map(i => i[0]);
|
||
};
|
||
```
|
||
|
||
### C#:
|
||
|
||
```csharp
|
||
public int[] TopKFrequent(int[] nums, int k) {
|
||
//哈希表-标权重
|
||
Dictionary<int,int> dic = new();
|
||
for(int i = 0; i < nums.Length; i++){
|
||
if(dic.ContainsKey(nums[i])){
|
||
dic[nums[i]]++;
|
||
}else{
|
||
dic.Add(nums[i], 1);
|
||
}
|
||
}
|
||
//优先队列-从小到大排列
|
||
PriorityQueue<int,int> pq = new();
|
||
foreach(var num in dic){
|
||
pq.Enqueue(num.Key, num.Value);
|
||
if(pq.Count > k){
|
||
pq.Dequeue();
|
||
}
|
||
}
|
||
|
||
// //Stack-倒置
|
||
// Stack<int> res = new();
|
||
// while(pq.Count > 0){
|
||
// res.Push(pq.Dequeue());
|
||
// }
|
||
// return res.ToArray();
|
||
|
||
//数组倒装
|
||
int[] res = new int[k];
|
||
for(int i = k - 1; i >= 0; i--){
|
||
res[i] = pq.Dequeue();
|
||
}
|
||
return res;
|
||
}
|
||
|
||
```
|
||
|
||
### Scala:
|
||
|
||
解法一: 优先级队列
|
||
```scala
|
||
object Solution {
|
||
import scala.collection.mutable
|
||
def topKFrequent(nums: Array[Int], k: Int): Array[Int] = {
|
||
val map = mutable.HashMap[Int, Int]()
|
||
// 将所有元素都放入Map
|
||
for (num <- nums) {
|
||
map.put(num, map.getOrElse(num, 0) + 1)
|
||
}
|
||
// 声明一个优先级队列,在函数柯里化那块需要指明排序方式
|
||
var queue = mutable.PriorityQueue[(Int, Int)]()(Ordering.fromLessThan((x, y) => x._2 > y._2))
|
||
// 将map里面的元素送入优先级队列
|
||
for (elem <- map) {
|
||
queue.enqueue(elem)
|
||
if(queue.size > k){
|
||
queue.dequeue // 如果队列元素大于k个,出队
|
||
}
|
||
}
|
||
// 最终只需要key的Array形式就可以了,return关键字可以省略
|
||
queue.map(_._1).toArray
|
||
}
|
||
}
|
||
```
|
||
解法二: 相当于一个wordCount程序
|
||
```scala
|
||
object Solution {
|
||
def topKFrequent(nums: Array[Int], k: Int): Array[Int] = {
|
||
// 首先将数据变为(x,1),然后按照x分组,再使用map进行转换(x,sum),变换为Array
|
||
// 再使用sort针对sum进行排序,最后take前k个,再把数据变为x,y,z这种格式
|
||
nums.map((_, 1)).groupBy(_._1)
|
||
.map {
|
||
case (x, arr) => (x, arr.map(_._2).sum)
|
||
}
|
||
.toArray
|
||
.sortWith(_._2 > _._2)
|
||
.take(k)
|
||
.map(_._1)
|
||
}
|
||
}
|
||
```
|
||
|
||
### Rust
|
||
|
||
小根堆
|
||
|
||
```rust
|
||
use std::cmp::Reverse;
|
||
use std::collections::{BinaryHeap, HashMap};
|
||
impl Solution {
|
||
pub fn top_k_frequent(nums: Vec<i32>, k: i32) -> Vec<i32> {
|
||
let mut hash = HashMap::new();
|
||
let mut heap = BinaryHeap::with_capacity(k as usize);
|
||
nums.into_iter().for_each(|k| {
|
||
*hash.entry(k).or_insert(0) += 1;
|
||
});
|
||
|
||
for (k, v) in hash {
|
||
if heap.len() == heap.capacity() {
|
||
if *heap.peek().unwrap() < (Reverse(v), k) {
|
||
continue;
|
||
} else {
|
||
heap.pop();
|
||
}
|
||
}
|
||
heap.push((Reverse(v), k));
|
||
}
|
||
heap.into_iter().map(|(_, k)| k).collect()
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|