diff --git a/note/hadoop/[干货]HDFS是怎么做文件管理和容错的?.md b/note/hadoop/[干货]HDFS是怎么做文件管理和容错的?.md
new file mode 100644
index 0000000..bb0adca
--- /dev/null
+++ b/note/hadoop/[干货]HDFS是怎么做文件管理和容错的?.md
@@ -0,0 +1,176 @@
+ 在 HDFS 中,NameNode 作为整个集群的管理中心,保存着整个 HDFS 中的元数据信息,而真正保存数据的是 DataNode。那么, **Hadoop HDFS 是如何管理这些文件的呢**?本期内容就来为大家解答:
+
+
+***
+
+## HDFS 文件管理
+
+### 1、HDFS 的块分布
+ HDFS 会将数据文件切分成一个个小的数据块进行存储,同时会将这些数据块的副本保存多份,分别保存到不同的 DataNode 上。HDFS 中数据块的副本数由 `hdfs-site.xml`文件中的`dfs.replication`属性决定,配置属性如下:
+
+```xml
+
+ dfs.replication
+ 3
+
+```
+ Hadoop 默认的副本数为3,并且在机架的存放上也有一定的**策略**。Hadoop 的默认布局策略,即默认的**副本存放策略**如下:
+
+ (1)第 1 个副本存放在 HDFS 客户端所在的节点上。
+
+ (2)第 2 个副本存放在与第1个副本不同的机架上,并且是随机选择的节点。
+
+ (3)第 3 个副本存放在与第2个副本相同的机架上,并且是不同的节点。
+
+### 2、数据读取
+ HDFS 的数据读取过程需要客户端先访问 NameNode,获取元数据信息,然后到具体的 DataNode 上读取数据,如下图所示:
+
+
+
+
+ (1)**客户端向NameNode发起请求,读取元数据信息**。**NameNode上存储着整个HDFS集群的元数据信息**,这些元数据信息包括**文件名,所有者,所在组,权限,数据块和 DataNode列表**。
+
+ 这个过程中还要对客户端的身份信息进行**验证**,同时检测是否存在要读取的文件,并且需要验证客户端的身份是否具有**访问权限**。
+
+ (2)**NameNode 将相关的元数据信息返回给客户端**。
+
+ (3)**客户端到指定的 DataNode 上读取相应的数据块**。
+
+ (4)**DataNode 返回相应的数据块信息**。
+
+ 第(3)和(4)步会持续进行,一直到文件的所有数据块都读取完毕或者 HDFS 客户端主动关闭了文件流为止。
+
+
+### 3、数据写入
+ HDFS 中的数据写入过程同样需要客户端先访问 NameNode,获取元数据信息,然后到具体的 DataNode 上写入数据,如图所示
+
+
+
+
+
+
+ 以下是具体步骤:
+
+ (1)客户端请求 NameNode 获取元数据信息。这个过程中,NameNode 要对客户端的省份信息进行验证,同时需要**验证**客户端的身份是否具有**写权限**。
+
+ (2)**NameNode 返回相应的元数据信息给客户端**。
+
+ (3)**客户端向第一个 DataNode 写数据**。
+
+ (4)**第 1 个 DataNode 向第 2 个 DataNode 写数据**。
+
+ (5)**第 2 个 DataNode 向第 3 个 DataNode 写数据**。
+
+ (6)**第 3 个 DataNode 向第 2 个 DataNode 返回确认结果信息**。
+
+ (7)**第 2 个 DataNode 向第 1 个 DataNode 返回确认结果信息**。
+
+ (8)**第 1 个 DataNode 向客户端返回确认结果信息**。
+
+
+ 其中,第(4)步和第(5)步是异步执行的,当 HDFS 中的多个 DataNode 发生故障或者发生错误时,只要正确写入了满足最少数目要求的数据副本数,HDFS客户端就可以从数据块的副本中恢复数据。
+
+ 最少数目要求的数据副本数由`hdfs-site.xml`文件中的`dfs.namenode.replication.min`属性决定,配置属性如下:
+
+```bash
+
+ dfs.namenode.replication.min
+ 1
+
+```
+ **最少数目要求的数据副本数默认为1,即只要正确写入了数据的一个副本,客户端就可以从数据副本中恢复数据**。
+
+
+### 4、数据完整性
+ 通常,在校验数据是否损坏时可以用如下方式。
+
+ (1)当数据**第一次引入时**,计算**校验和**,
+
+ (2)当数据经过一系列的**传输或者复制时**,再次**计算校验和**。
+
+ (3)对比第(1)和第(2)步的校验和是否一致,如果两次数据的校验和不一致,则证明数据已经被破坏。
+
+> **注意:这种使用校验和来验证数据的技术只能检测数据是否被损坏,并不能修复数据。**
+
+ HDFS中校验数据是否损坏使用的也是校验和技术,无论是进行数据的写入还是进行数据的读取,都会验证数据的校验和。校验和的字节数由`core-site.xml`文件中的`io.bytes.per.checksum`属性指定,默认的字节长度为 512 B,具体配置如下:
+
+```bash
+
+ io.bytes.per.checksum
+ 512
+
+```
+ **当 HDFS 写数据时**,HDFS 客户端会将**要写入的数据及对应数据的校验和**发送到 DataNode 组成的复制管道中,其中最后一个 DataNode 负责验证数据的校验和是否一致。**如果检测到校验和与 HDFS 客户端发送的校验和不一致,则 HDFS 客户端 会收到校验和异常的信息,可以在程序中捕获到这个异常,进行相应的处理,如重新写入数据或者用其他方式处理**。
+
+ H**DFS 读数据时**也会验证校验和,此时会将它们**与 DataNode 中存储的校验和进行比较**。如果其与 DataNode 中存储的校验和不一致,则说明数据已经损坏,需要重新从其他 DataNode 读取数据。其中,**每个 DataNode 都会保存一个校验和日志,客户端成功验证一个数据块之后,DataNode会更新该校验和日志**。
+
+ 除此之外,**每个 DataNode 也会在后台运行一个扫描器(DataBlockScanner),定期验证存储在这个 DataNode 上的所有数据块**。
+
+ 由于 **HDFS** 提供的**数据块副本机制**,**当一个数据块损坏时,HDFS 能够自动复制其他完好的数据块来修复损坏的数据块**,得到一个新的,完好的数据块,以达到系统设置的副本数要求,因此在某些数据块出现损坏时,保证了数据的完整性。
+
+### 5、 HDFS 容错
+ HDFS 的容错机制大体上可以分为两个方面:文件系统的容错和 Hadoop 自身的容错。
+
+#### 5.1 文件系统的容错
+ 文件系统的容错可以通过 NameNode 高可用、SecondaryNameNode 机制、数据块副本机制和心跳机制来实现。
+
+> **注意:当以本地模式或者伪集群模式部署 Hadoop 时,会存在 SeconddayNameNode;当以集群模式部署 Hadoop 时,如果配置了 NameNode 的 HA 机制,则不会存在 SecondaryNameNode,此时会存在备 NameNode**。
+
+ 在这里重点说下集群模式下 HDFS 的容错,有关 SecondaryNameNode 机制可参见上一篇文章《[前方高能 | HDFS 的架构,你吃透了吗?](https://alice.blog.csdn.net/article/details/114212487)》的说明:
+
+ HDFS 的容错机制如图所示:
+
+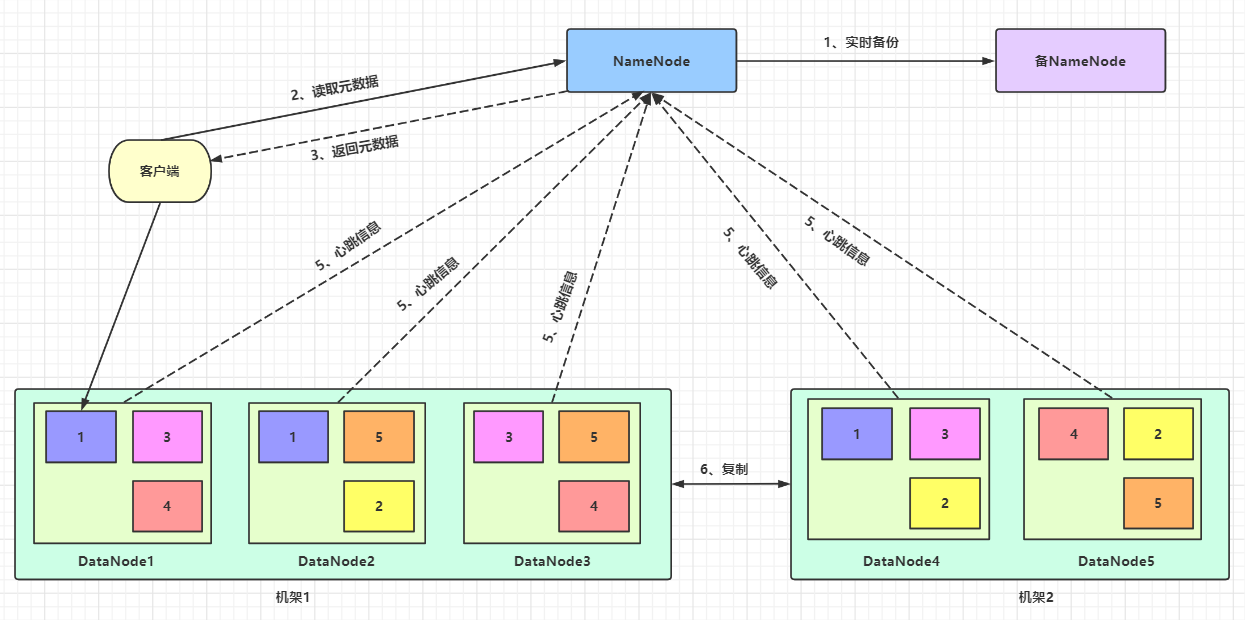
+ 具体的流程如下:
+
+ (1)备 NameNode 实时备份主 NameNode 上的元数据信息,一旦主 NameNode 发生故障不可用,则备 NameNode 迅速接管主 NameNode 的工作。
+
+ (2)客户端向 NameNode 读取元数据信息。
+
+ (3)NameNode 向客户端返回元数据信息。
+
+ (4)客户端向 DataNode 读取/写入 数据,此时会分为读取数据和写入数据两种情况。
+
+ ① 读取数据:HDFS 会检测文件块的完整性,确认文件块的**检验和**是否一致,如果不一致,则从其他的 DataNode 上获取相应的副本。
+
+ ② 写入数据:HDFS 会检测文件块的完整性,同时记录新创建的文件的所有文件块的**校验和**。
+
+ (5) **DataNode 会定期向 NameNode 发送心跳信息,将自身节点的状态告知 NameNode**;**NameNode 会将 DataNode 需要执行的命令放入心跳信息的返回结果中,返回给 DataNode 执**行。
+
+ **当 DataNode 发生故障没有正常发送心跳信息时,NameNode 会检测文件块的副本数是否小于 系统设置值,如果小于设置值,则自动复制新的副本并分发到其他的 DataNode 上**。
+
+ (6)集群中有数据关联的 DataNode 之间复制数据副本。
+
+ 当集群中的 DataNode 发生故障而失效,或者在集群中添加新的 DataNode 时,可能会导致**数据分布不均匀**。**当某个 DataNode 上的空闲空间资源大于系统设置的临界值时,HDFS 就会从 其他的 DataNode 上将数据迁移过来**。相对地,**如果某个 DataNode 上的资源出现超负荷运载,HDFS 就会根据一定的规则寻找有空闲资源的 DataNode,将数据迁移过去**。
+
+ 还有一种从侧面说明 HDFS 支持容错的机制,即当**从 HDFS 中删除数据时,数据并不是马上就会从 HDFS 中被删除,而是会将这些数据放到“回收站”目录中,随时可以恢复,直到超过了一定的时间才会真正删除这些数据**。
+
+
+
+#### 5.2 Hadoop自身的容错
+ Hadoop 自身的容错理解起来比较简单,当升级 Hadoop 系统时,如果出现 Hadoop 版本不兼容的问题,可以通过**回滚 Hadoop 版本的方式**来实现自身的容错。
+
+### 6、通过命令行管理文件
+ 这部分内容在之前的文章中已经介绍,大概常用的有40个命令,详情👉[干货 | HDFS常用的40个命令,你都知道吗?
+](https://blog.csdn.net/weixin_44318830/article/details/112752525?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522161502761316780264016467%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=161502761316780264016467&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-112752525.pc_v1_rank_blog_v1&utm_term=%E5%91%BD%E4%BB%A4)
+
+
+## 巨人的肩膀
+>
+> 1、《海量数据处理与大数据技术实践》
+> 2、《大数据平台架构与原型实现》
+> 3、https://www.cnblogs.com/mayundalao/p/11799849.html
+
+## 小结
+ 本篇内容在上一篇文章[《前方高能 | HDFS 的架构,你吃透了吗?》](https://alice.blog.csdn.net/article/details/114212487)为大家介绍 HDFS 架构的基础之上,又引入了新鲜的血液,对于**HDFS 数据块的分布**,以及**经典读写流程**,**数据完整性**和**容错机制** 作出了清晰的解释。希望大家看完之后能够有所收获!你知道的越多,你不知道的也越多,我是大数据梦想家,我们下一期见!
+
+
+## 彩蛋
+ 我在经历了太多技术群沦落为广告群,水文群,聊天群之后,立志打造一个真正的技术交流社区,于是和我现在的管理成立了「大数据梦想家」技术交流群,希望有更多热爱并渴望学习大数据技术的小伙伴加入到我们的队伍。以下是部分群规,群里设置有**严格的制度**以及**不错的福利制度**。
+
+
+
+
+ 想了解更多信息,加入我们的学习群,可以关注下方公众号,后台回复“**加群**”即可。
+
+
\ No newline at end of file