更新readme文件,添加一篇文章链接
This commit is contained in:
48
.idea/workspace.xml
generated
48
.idea/workspace.xml
generated
@@ -20,6 +20,7 @@
|
||||
</component>
|
||||
<component name="ChangeListManager">
|
||||
<list default="true" id="1f4b9d3c-5ec4-4f92-99a5-47a66eed35c3" name="Default Changelist" comment="">
|
||||
<change afterPath="$PROJECT_DIR$/note/面试杀招/看完了108份面试题,我为你总结出了这 10 个【Hive】高频考点(建议收藏).md" afterDir="false" />
|
||||
<change beforePath="$PROJECT_DIR$/.idea/workspace.xml" beforeDir="false" afterPath="$PROJECT_DIR$/.idea/workspace.xml" afterDir="false" />
|
||||
<change beforePath="$PROJECT_DIR$/README.md" beforeDir="false" afterPath="$PROJECT_DIR$/README.md" afterDir="false" />
|
||||
</list>
|
||||
@@ -58,7 +59,7 @@
|
||||
<property name="RunOnceActivity.ShowReadmeOnStart" value="true" />
|
||||
<property name="WebServerToolWindowFactoryState" value="false" />
|
||||
<property name="aspect.path.notification.shown" value="true" />
|
||||
<property name="last_opened_file_path" value="$PROJECT_DIR$" />
|
||||
<property name="last_opened_file_path" value="$PROJECT_DIR$/note/面试杀招" />
|
||||
<property name="node.js.detected.package.eslint" value="true" />
|
||||
<property name="node.js.detected.package.tslint" value="true" />
|
||||
<property name="node.js.path.for.package.eslint" value="project" />
|
||||
@@ -72,13 +73,6 @@
|
||||
<property name="settings.editor.selected.configurable" value="MavenSettings" />
|
||||
</component>
|
||||
<component name="RecentsManager">
|
||||
<key name="CopyFile.RECENT_KEYS">
|
||||
<recent name="F:\github\TheKingOfBigData\code\SparkBase" />
|
||||
<recent name="F:\github\TheKingOfBigData\code\FlinkBase" />
|
||||
<recent name="F:\github\TheKingOfBigData\resources\简历模板" />
|
||||
<recent name="F:\github\TheKingOfBigData\resources\大数据面试题" />
|
||||
<recent name="F:\github\TheKingOfBigData\resources\Java面试题" />
|
||||
</key>
|
||||
<key name="MoveFile.RECENT_KEYS">
|
||||
<recent name="F:\github\TheKingOfBigData\note\其他组件" />
|
||||
<recent name="F:\github\TheKingOfBigData\note\hadoop" />
|
||||
@@ -86,6 +80,13 @@
|
||||
<recent name="F:\github\TheKingOfBigData\note\hive" />
|
||||
<recent name="F:\github\TheKingOfBigData\note" />
|
||||
</key>
|
||||
<key name="CopyFile.RECENT_KEYS">
|
||||
<recent name="F:\github\TheKingOfBigData\note\面试杀招" />
|
||||
<recent name="F:\github\TheKingOfBigData\code\SparkBase" />
|
||||
<recent name="F:\github\TheKingOfBigData\code\FlinkBase" />
|
||||
<recent name="F:\github\TheKingOfBigData\resources\简历模板" />
|
||||
<recent name="F:\github\TheKingOfBigData\resources\大数据面试题" />
|
||||
</key>
|
||||
</component>
|
||||
<component name="ServiceViewManager">
|
||||
<option name="viewStates">
|
||||
@@ -150,14 +151,8 @@
|
||||
<workItem from="1617117672628" duration="2947000" />
|
||||
<workItem from="1617243627654" duration="724000" />
|
||||
<workItem from="1617869636389" duration="705000" />
|
||||
<workItem from="1618154426788" duration="621000" />
|
||||
</task>
|
||||
<task id="LOCAL-00042" summary="添加思维导图部分内容">
|
||||
<created>1613553599741</created>
|
||||
<option name="number" value="00042" />
|
||||
<option name="presentableId" value="LOCAL-00042" />
|
||||
<option name="project" value="LOCAL" />
|
||||
<updated>1613553599741</updated>
|
||||
<workItem from="1618154426788" duration="1898000" />
|
||||
<workItem from="1619103265928" duration="1986000" />
|
||||
</task>
|
||||
<task id="LOCAL-00043" summary="补充新的干货">
|
||||
<created>1613566085749</created>
|
||||
@@ -495,7 +490,14 @@
|
||||
<option name="project" value="LOCAL" />
|
||||
<updated>1618154514145</updated>
|
||||
</task>
|
||||
<option name="localTasksCounter" value="91" />
|
||||
<task id="LOCAL-00091" summary="更新readme文件,添加3篇文章的链接">
|
||||
<created>1618155085683</created>
|
||||
<option name="number" value="00091" />
|
||||
<option name="presentableId" value="LOCAL-00091" />
|
||||
<option name="project" value="LOCAL" />
|
||||
<updated>1618155085683</updated>
|
||||
</task>
|
||||
<option name="localTasksCounter" value="92" />
|
||||
<servers />
|
||||
</component>
|
||||
<component name="TypeScriptGeneratedFilesManager">
|
||||
@@ -515,7 +517,6 @@
|
||||
</option>
|
||||
</component>
|
||||
<component name="VcsManagerConfiguration">
|
||||
<MESSAGE value="更新画像文章" />
|
||||
<MESSAGE value="调整内容格式" />
|
||||
<MESSAGE value="更新Hbase的应用" />
|
||||
<MESSAGE value="更新Hbase的文章的排版和readme文件" />
|
||||
@@ -540,7 +541,8 @@
|
||||
<MESSAGE value="添加了2篇关于Kylin新的文章" />
|
||||
<MESSAGE value="更新 readme 文件,新加入2篇文章的链接" />
|
||||
<MESSAGE value="新加入3篇文章" />
|
||||
<option name="LAST_COMMIT_MESSAGE" value="新加入3篇文章" />
|
||||
<MESSAGE value="更新readme文件,添加3篇文章的链接" />
|
||||
<option name="LAST_COMMIT_MESSAGE" value="更新readme文件,添加3篇文章的链接" />
|
||||
</component>
|
||||
<component name="WindowStateProjectService">
|
||||
<state x="249" y="0" key="#Project_Structure" timestamp="1614052957576">
|
||||
@@ -555,11 +557,11 @@
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
<state x="506" y="327" key="#com.intellij.framework.addSupport.AddSupportForSingleFrameworkDialog/0.0.1536.824/1920.0.1536.824@0.0.1536.824" timestamp="1614136268236" />
|
||||
<state x="400" y="0" key="CommitChangelistDialog2" timestamp="1618154512761">
|
||||
<state x="400" y="0" key="CommitChangelistDialog2" timestamp="1618155084912">
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
<state x="367" y="0" key="CommitChangelistDialog2/0.0.1536.824/1920.0.1536.824@0.0.1536.824" timestamp="1616726432133" />
|
||||
<state x="400" y="0" key="CommitChangelistDialog2/0.0.1536.824@0.0.1536.824" timestamp="1618154512761" />
|
||||
<state x="400" y="0" key="CommitChangelistDialog2/0.0.1536.824@0.0.1536.824" timestamp="1618155084912" />
|
||||
<state x="93" y="93" width="1350" height="638" key="DiffContextDialog" timestamp="1613631431416">
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
@@ -573,11 +575,11 @@
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
<state x="270" y="57" key="SettingsEditor/0.0.1536.824@0.0.1536.824" timestamp="1615778393772" />
|
||||
<state x="361" y="145" key="Vcs.Push.Dialog.v2" timestamp="1618154518227">
|
||||
<state x="361" y="145" key="Vcs.Push.Dialog.v2" timestamp="1618155087253">
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
<state x="361" y="145" key="Vcs.Push.Dialog.v2/0.0.1536.824/1920.0.1536.824@0.0.1536.824" timestamp="1616726435098" />
|
||||
<state x="361" y="145" key="Vcs.Push.Dialog.v2/0.0.1536.824@0.0.1536.824" timestamp="1618154518227" />
|
||||
<state x="361" y="145" key="Vcs.Push.Dialog.v2/0.0.1536.824@0.0.1536.824" timestamp="1618155087253" />
|
||||
<state x="572" y="322" key="com.intellij.openapi.vcs.update.UpdateOrStatusOptionsDialogupdate-v2" timestamp="1613133100634">
|
||||
<screen x="0" y="0" width="1536" height="824" />
|
||||
</state>
|
||||
|
||||
15
README.md
15
README.md
@@ -104,6 +104,10 @@
|
||||
5. [实时分析数据库 Druid,Mark 一下](https://github.com/BigDataScholar/TheKingOfBigData/blob/master/note/%E5%85%B6%E4%BB%96%E7%BB%84%E4%BB%B6/%E5%AE%9E%E6%97%B6%E5%88%86%E6%9E%90%E6%95%B0%E6%8D%AE%E5%BA%93%20Druid%EF%BC%8CMark%20%E4%B8%80%E4%B8%8B.md)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### [大数据实战]电商用户行为数据分析
|
||||
|
||||
1. [基于 flink 的电商用户行为数据分析【1】项目整体介绍](https://github.com/BigDataScholar/TheKingOfBigData/blob/master/note/%E5%AE%9E%E6%88%98%E9%A1%B9%E7%9B%AE/%E5%9F%BA%E4%BA%8Eflink%E7%9A%84%E7%94%B5%E5%95%86%E7%94%A8%E6%88%B7%E8%A1%8C%E4%B8%BA%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E3%80%901%E3%80%91%20%E9%A1%B9%E7%9B%AE%E6%95%B4%E4%BD%93%E4%BB%8B%E7%BB%8D.md)
|
||||
@@ -158,12 +162,11 @@
|
||||
2. [简单谈谈最近在看的几本书「数据中台,用户画像」](https://github.com/BigDataScholar/TheKingOfBigData/blob/master/note/%E7%A8%8B%E5%BA%8F%E4%BA%BA%E7%94%9F/%E7%AE%80%E5%8D%95%E8%B0%88%E8%B0%88%E6%9C%80%E8%BF%91%E5%9C%A8%E7%9C%8B%E7%9A%84%E5%87%A0%E6%9C%AC%E4%B9%A6%E3%80%8C%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%8F%B0%EF%BC%8C%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E3%80%8D.md)
|
||||
3. [[云上有为 · 未来无界] 2021上海站 ECUG Con 第一天回忆录](https://github.com/BigDataScholar/TheKingOfBigData/blob/master/note/%E7%A8%8B%E5%BA%8F%E4%BA%BA%E7%94%9F/%5B%E4%BA%91%E4%B8%8A%E6%9C%89%E4%B8%BA%20%C2%B7%20%E6%9C%AA%E6%9D%A5%E6%97%A0%E7%95%8C%5D%202021%E4%B8%8A%E6%B5%B7%E7%AB%99%20ECUG%20Con%20%E7%AC%AC%E4%B8%80%E5%A4%A9%E5%9B%9E%E5%BF%86%E5%BD%95.md)
|
||||
|
||||
|
||||
### 中间件
|
||||
|
||||
1. [从 0 到 1 学习 elasticsearch ,这一篇就够了!(建议收藏)](https://github.com/BigDataScholar/TheKingOfBigData/blob/master/note/%E4%B8%AD%E9%97%B4%E4%BB%B6/%E4%BB%8E%200%20%E5%88%B0%201%20%E5%AD%A6%E4%B9%A0%20elasticsearch%20%EF%BC%8C%E8%BF%99%E4%B8%80%E7%AF%87%E5%B0%B1%E5%A4%9F%E4%BA%86%EF%BC%81(%E5%BB%BA%E8%AE%AE%E6%94%B6%E8%97%8F).md)
|
||||
|
||||
|
||||
|
||||
|
||||
### 其他技术
|
||||
|
||||
1. [零基础带你硬核了解并上手“Ansible“!](https://alice.blog.csdn.net/article/details/109771486)
|
||||
@@ -176,8 +179,6 @@
|
||||
8. [零基础学Docker【4】 | 一文带你理解Docker镜像原理之联合文件系统](https://alice.blog.csdn.net/article/details/109638410)
|
||||
9. [万字长文带你快速了解并上手Testcontainers](https://alice.blog.csdn.net/article/details/111790143)
|
||||
|
||||
|
||||
|
||||
### 企业级真实应用
|
||||
1. [腾讯基于 Flink SQL 的功能扩展与深度优化实践](https://mp.weixin.qq.com/s/vgpeZKFR13sSPwvtPvaDNA)
|
||||
2. [网易云音乐基于 Flink + Kafka 的实时数仓建设实践](https://mp.weixin.qq.com/s/JcuW0_YDQj0rlgPMmuwzYQ)
|
||||
@@ -186,6 +187,7 @@
|
||||
5. [分析 BAT 互联网巨头在大数据方向布局及大数据未来发展趋势](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&tempkey=MTEwMV9qbmlobnBUUXNVNDVOb3d6Vk1BWlRhUExybUJnYmhrRExWTllDT2FNRzVWRC1lb1JuYzdUQVl4bkI0QnUwckNSN3g1dTQ1cGdQMVYyZktmNWMtelVIVV9PWmZzR1NpVHVoQTI0Z0k2emNrN0ZFSmNPODV2VFVZcVRkZmJodDRjeERpakQxQlZ6RmlkOWlodzZPRmhETE05Y2dlOHRaYTNRN0VFbVJnfn4%3D&chksm=68d842d55fafcbc37adf1768525d80aabf26baf743c145b6c10b31fb801b55e5b22c1b7bbd59&__mpa_temp_link_flag=1&token=330116486#rd)
|
||||
6. [结合公司业务分析离线数仓建设](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&mid=2247490484&idx=1&sn=6f26e9c4ded5188748d1bf9a4be72a20&chksm=e8d84366dfafca70c6f36ba84a6c43ebf59b4a7898f20598f0d3cea9a4579f442c67473c8ef3&token=1819206302&lang=zh_CN#rd)
|
||||
7. [网易云音乐数仓维度建模实践-模型设计篇](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&tempkey=MTEwM184TW5iS04wSDY1djhaSjduckJ2QTJHbEszVi00SjBOcFZQUkNJby1ReEpIWWtFNURHQ0dKdE9NOHU1TXByMWN6Zy1VOXdwX2xZeFM3T2dWbENWckhuaGM0TzlLUkRWVVY4N1M0bE40dm1ySjd0UFdmcWE0NDhkWDllR0hHb0lPdVdab1VFWEVTUE11YURNOXVwN1lBbjN3UTFUZXM0S3dwNkU1RGhBfn4%3D&chksm=68dbb8705fac31664b48442294a3b4f61175f480f05ea5320a3126c038d99da5669169e346d5&__mpa_temp_link_flag=1&token=1690256264#rd)
|
||||
8. [Apache Doris 在京东广告的应用实践 ](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&mid=2247493960&idx=1&sn=ccfa5073bf7d47eb85cfe9cf2475eecf&chksm=e8dbb19adfac388c36484241ddf78236f8af533ad159870be36c56cb3f528e35529cb28d55d3&token=1073059733&lang=zh_CN#rd)
|
||||
|
||||
|
||||
### 超强总结
|
||||
@@ -199,6 +201,9 @@
|
||||
### 精华面经
|
||||
1. [美团优选大数据开发岗面试真题-附答案详细解析](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&mid=2247492683&idx=1&sn=6a7483a9ad93493555a52a419b960ed1&chksm=e8dbbc99dfac358f95524c7bc90a4a2dc4699ce376f19b613b2aee984bb03b1a31da9cd8cd7e&token=1777830110&lang=zh_CN#rd)
|
||||
|
||||
### 有趣有料
|
||||
1. [ETL和ELT到底有啥区别???](https://mp.weixin.qq.com/s?__biz=MzIzNjM2MDEyNQ==&mid=2247494017&idx=1&sn=92c3f3991eeece3d092eeaa69bc25e89&chksm=e8dbb153dfac3845510b85da4c583bf3a2343e51b8180f908a43537173cebdbe14277558dbd7&token=1073059733&lang=zh_CN#rd)
|
||||
|
||||
### 福利
|
||||
|
||||
1. [最新Java各知识点综合面试考点+大厂面试题](https://github.com/BigDataScholar/TheKingOfBigData/tree/master/resources/Java%E9%9D%A2%E8%AF%95%E9%A2%98)
|
||||
|
||||
296
note/面试杀招/看完了108份面试题,我为你总结出了这 10 个【Hive】高频考点(建议收藏).md
Normal file
296
note/面试杀招/看完了108份面试题,我为你总结出了这 10 个【Hive】高频考点(建议收藏).md
Normal file
@@ -0,0 +1,296 @@
|
||||
## 前言
|
||||
之前听 CSDN 头牌博主 @沉默王二 说过一句话,我觉得十分在理:<font color='MediumSlateBlue'>**处在互联网时代,是一种幸福,因为各式各样的信息非常容易触达,如果掌握了信息筛选的能力,就真的是“运筹帷幄之中,决胜千里之外”**</font>。就像现在各行业都内卷不断,我们要从中破圈,只有想办法提升自己的竞争力!例如备战面试,广泛无脑地刷题只会消耗完你最后一丝精力,而多刷别人总结复盘记录下来的面经,有利于我们为下一次的“跨越”做好准备!
|
||||
|
||||
<font color='RoyalBlue'>**笔者是一名专注研究大数据基础,架构和原型实现的“终身学者”**</font>,最近在看了108份面经之后,想对大数据面试中高频的知识考点做一个汇总,巩固自己记忆的同时,也希望能给带给读者一些正确复习方向。本期内容我们介绍的是【Hive】篇 !
|
||||

|
||||
## 1、 使用过 Hive 吗?介绍一下什么是 Hive ?
|
||||
Hive 是基于 Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL),提供快速开发的能力。Hive本质是将SQL转换为 MapReduce的任务进行运算,减少开发人员的学习成本,功能扩展很方便。
|
||||
|
||||
|
||||
> **拓展**:
|
||||
> 1、hive存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的文件,HQL就是用sql语法来写的mr程序
|
||||
> 2、数据仓库是大多数企业“试水”大数据的首选切入点 ,因为数据仓库主要编程语言还是 SQL,而在大数据平台上,不论是 Hive 还是 SparkSQL,都是通过高度标准化的 SQL 来进行开发,这对于很多从传统数据仓库向大数据转型的开发人员和团队来说,是一种较为平滑的过渡。
|
||||
|
||||
## 2、介绍一下Hive的架构
|
||||
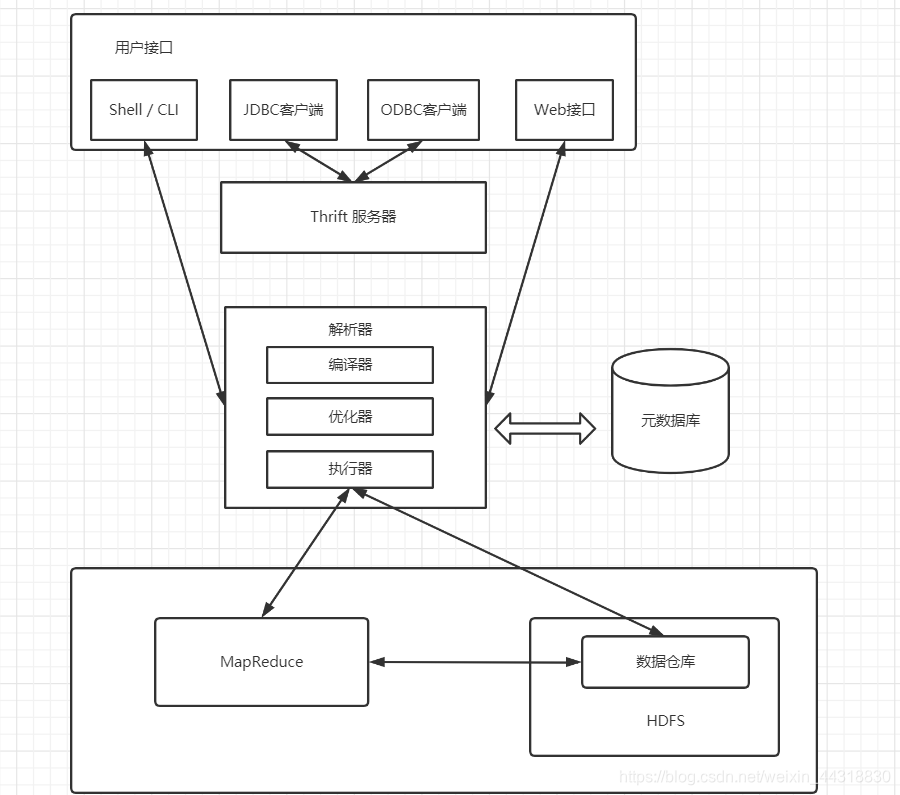
需要对 Hive 的架构有个大致的印象:
|
||||
|
||||
|
||||
|
||||
- Hive可以通过CLI,JDBC和 ODBC 等客户端进行访问。除此之外,Hive还支持 WUI 访问
|
||||
- Hive内部执行流程:解析器(解析SQL语句)、编译器(把SQL语句编译成MapReduce程序)、优化器(优化MapReduce程序)、执行器(将MapReduce程序运行的结果提交到HDFS)
|
||||
- Hive的**元数据**保存在数据库中,如保存在MySQL,SQLServer,PostgreSQL,Oracle及Derby等数据库中。Hive中的元数据信息包含表名,列名,分区及其属性,表的属性(包括是否为外部表),表数据所在目录等。
|
||||
- <font color='BlueViolet'>Hive将大部分 HiveSQL语句转化为MapReduce作业提交到Hadoop上执行</font>;<font color='red'>少数HiveSQL语句不会转化为MapReduce作业,直接从DataNode上获取数据后按照顺序输出</font>。
|
||||
|
||||
> **拓展:**
|
||||
> 这里有有个易混淆点,Hive 元数据默认存储在 derby 数据库,不支持多客户端访问,所以将元数据存储在 MySQL 等数据库,支持多客户端访问。
|
||||
|
||||
|
||||
## 3、使用过哪些 Hive 函数
|
||||
Hive的函数种类众多,如果一定要分类的话
|
||||
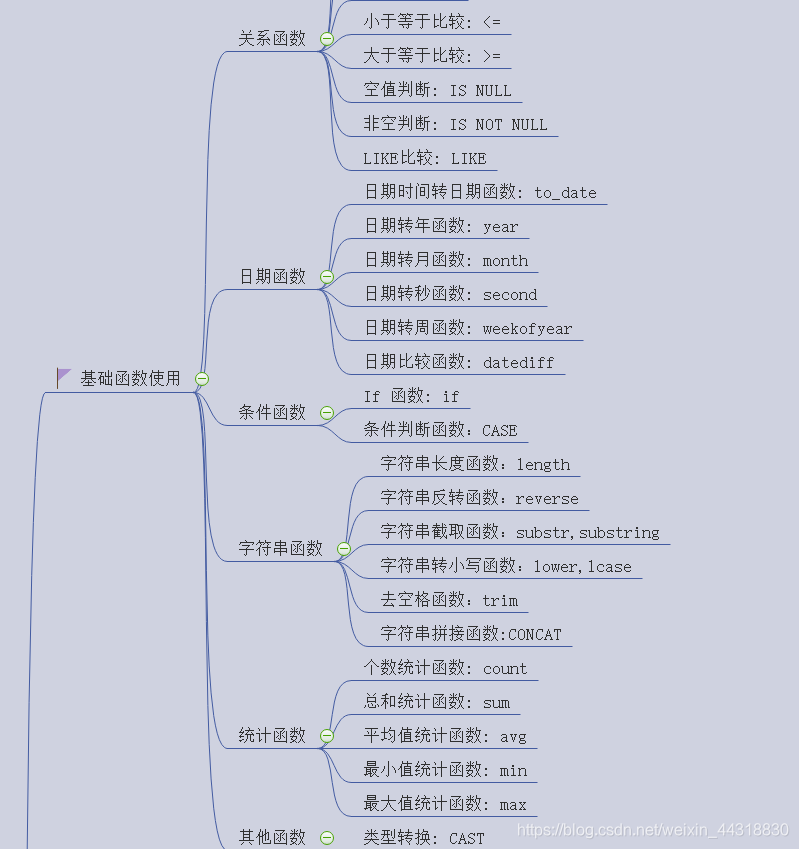
|
||||
这些还都是最简单的,想提高自己实力,可以私聊我获取收藏的一本Hive函数大全,从最简单的**关系运算**,到各种**数值计算的函数**,**日期函数**,**条件函数**,**字符串函数**,甚至是**混合函数**,**汇总函数**等等,都有详细的解释说明 ...
|
||||
> **拓展:**
|
||||
> 面试一般喜欢通过笔试题或者真实场景题,来让你给出SQL思路或者现场手写,所以了解常用的 Hive函数非常重要,这直接就反映了自己的基本功。
|
||||
|
||||
## 4、Hive内部表、外部表、分区表、分桶表的区别,以及各自的使用场景
|
||||
- **内部表**
|
||||
|
||||
如果Hive中没有特别指定,则默认创建的表都是**管理表**,也称**内部表**。由Hive负责管理表中的数据,管理表不共享数据。删除管理表时,会删除管理表中的数据和元数据信息。
|
||||
|
||||
- **外部表**
|
||||
|
||||
当一份数据需要被共享时,可以创建一个外部表指向这份数据。
|
||||
|
||||
删除该表并不会删除掉原始数据,删除的是表的元数据。当表结构或者分区数发生变化时,需要进行一步修复的操作。
|
||||
|
||||
- **分区表**
|
||||
|
||||
分区表使用的是表外字段,需要指定字段类型,并通过关键字partitioned by(partition_name string)声明,但是分区划分粒度较粗 。
|
||||
|
||||
优势也很明显,就是将数据按区域划分开,查询时不用扫描无关的数据,加快查询速度 。
|
||||
|
||||
|
||||
- **分桶表**
|
||||
|
||||
分桶使用的是表内字段,已经知道字段类型,不需要再指定。通过关键字 `clustered by(column_name) into … buckets`声明。**分桶是更细粒度的划分、管理数据,可以对表进行先分区再分桶的划分策略**
|
||||
|
||||
分桶最大的优势就是:用于数据取样,可以起到优化加速的作用。
|
||||
|
||||
> **拓展:**
|
||||
关于**内部表**,**外部表**,**分区表**,**分桶表** 知识的考察是面试的**重点**,需要留意。其中**分桶逻辑**为:对分桶字段求哈希值,用哈希值与分桶的数量取余,余几,这个数据就放在那个桶内。
|
||||
|
||||
## 5、介绍一下 Order By,Sort By,Distrbute By,Cluster By的区别
|
||||
- **Order By(全局排序)**
|
||||
|
||||
order by 会对输入做全局排序,因此只有一个reduce(多个reducer无法保证全局有序),也正因为只有一个 reducer,所以当输入的数据规模较大时,会导致计算的时间较长。
|
||||
> **注意:**
|
||||
Order by 和 数据库中的 Order by 功能一致,按照某一个或者字段排序输出。与数据库中 order by的区别在于在 hive 的严格模式下(<font color=' Tomato'>**hive.mapred.mode = strict**</font>)下,必须指定 limit ,否则执行会报错!
|
||||
|
||||
- **Sort By(每个MapReduce排序)**
|
||||
|
||||
sort by并不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置 mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
|
||||
> **拓展:**
|
||||
> ①sort by 不受 hive.mapred.mode 是否为strict ,nostrict 的影响
|
||||
②sort by 的数据只能保证在同一reduce中的数据可以按指定字段排序
|
||||
③使用sort by 你可以指定执行的reduce 个数 (set mapred.reduce.tasks=),对输出的数据再执行归并排序,即可以得到全部结果
|
||||
**注意:**
|
||||
可以用 limit 子句大大减少数据量。使用 limit n 后,传输到 reduce 端(单机)的数据记录数就减少到 n* (map个数)。否则由于数据过大可能出不了结果。
|
||||
|
||||
- **Distrbute By(每个分区排序)**
|
||||
|
||||
在有些情况下,我们需要控制某个特定行应该到哪个 reducer ,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。distribute by 和 sort by 的常见使用场景有:
|
||||
|
||||
1. Map输出的文件大小不均
|
||||
2. Reduce输出文件不均
|
||||
3. 小文件过多
|
||||
4. 文件超大
|
||||
|
||||
- **Cluster By**
|
||||
|
||||
当 distribute by 和 sorts by字段相同时,可以使用 cluster by 方式代替。cluster by除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是<font color='blue'> **升序** </font>排序,不能像distribute by 一样去指定排序的规则为 **ASC** 或者 **DESC** 。
|
||||
|
||||
## 6、动态分区和静态分区的区别 + 使用场景
|
||||
关于动态分区在实际生产环境中的使用也是比较的多,所以这道题出现的频率也很高,但是不难。
|
||||
|
||||
- **静态分区:**
|
||||
|
||||
定义:对于静态分区,从字面就可以理解:表的分区数量和分区值是固定的。静态分区需要手动指定,列是在编译时期通过用户传递来决定的。
|
||||
|
||||
应用场景:需要提前知道所有分区。适用于分区定义得早且数量少的用例,不适用于生产。
|
||||
|
||||
- **动态分区:**
|
||||
|
||||
定义:是基于查询参数的位置去推断分区的名称,只有在 SQL 执行时才能确定,会根据数据自动的创建新的分区。
|
||||
|
||||
应用场景:有很多分区,无法提前预估新分区,动态分区是合适的,一般用于生产环境。
|
||||
|
||||
|
||||
## 7、HiveSQL 语句中 select from where group by having order by 的执行顺序
|
||||
平时没有仔细研究过,这题还真不好猜。
|
||||
|
||||
实际上,在 hive 和 mysql 中都可以通过 `explain+sql` 语句,来查看**执行顺序**。对于一条标准 sql 语句,它的书写顺序是这样的:
|
||||
|
||||
`select … from … where … group by … having … order by … limit …`
|
||||
|
||||
(1)mysql 语句执行顺序:
|
||||
|
||||
`from... where...group by... having.... select ... order by... limit …`
|
||||
|
||||
(2)hive 语句执行顺序:
|
||||
|
||||
`from … where … select … group by … having … order by … limit …`
|
||||
|
||||
> **拓展:**
|
||||
> 要搞清楚面试官问执行顺序背后的原因是什么,不是单纯的看你有没有背过这道题,而是看你是否能够根据执行顺序,写出不被人喷的 SQL
|
||||
> <br>
|
||||
> **根据执行顺序,我们平时编写时需要记住以下几点:**
|
||||
> - 使用分区剪裁、列剪裁,分区一定要加
|
||||
> - 少用 COUNT DISTINCT,group by 代替 distinct
|
||||
> - 是否存在多对多的关联
|
||||
> - 连接表时使用相同的关键词,这样只会产生一个 job
|
||||
> - 减少每个阶段的数据量,只选出需要的,在 join 表前就进行过滤
|
||||
> - 大表放后面
|
||||
> - 谓词下推:where 谓词逻辑都尽可能提前执行,减少下游处理的数据量
|
||||
> - sort by 代替 order by
|
||||
|
||||
|
||||
## 8、如何做 Hive优化
|
||||
只要你是老司机,多面试几趟,你就会发现常用的组件,中大型公司面试基本都会问到你如何对其调优。这个我正好之前总结过,大家可以看下:
|
||||
|
||||
- <font color='MediumVioletRed'>MapJoin</font>
|
||||
|
||||
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
|
||||
|
||||
- <font color='MediumVioletRed'>行列过滤</font>
|
||||
|
||||
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
|
||||
|
||||
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
|
||||
|
||||
- <font color='MediumVioletRed'>合理设置Map数</font>
|
||||
|
||||
是不是map数越多越好?
|
||||
|
||||
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而<font color='red'>一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费</font> 。而且,同时可执行的map数是**受限**的。此时我们就应该减少map数量。
|
||||
|
||||
|
||||
- <font color='MediumVioletRed'>合理设置Reduce数</font>
|
||||
|
||||
Reduce个数并不是越多越好
|
||||
|
||||
(1)过多的启动和初始化Reduce也会消耗时间和资源;
|
||||
(2)另外,有多少个Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
|
||||
|
||||
在设置Reduce个数的时候也需要考虑这两个**原则**:<font color='red'>处理大数据量利用合适的Reduce数;使单个Reduce任务处理数据量大小要合适</font>;
|
||||
|
||||
|
||||
- <font color='MediumVioletRed'>严格模式</font>
|
||||
|
||||
严格模式下,会有以下特点:
|
||||
|
||||
①对于分区表,用户不允许扫描所有分区
|
||||
|
||||
②使用了order by语句的查询,要求必须使用limit语句
|
||||
|
||||
③限制笛卡尔积的查询
|
||||
|
||||
- <font color='MediumVioletRed'>开启map端combiner(不影响最终业务逻辑)</font>
|
||||
|
||||
这个就属于配置层面上的优化了,需要我们手动开启 `set hive.map.aggr=true;`
|
||||
|
||||
|
||||
- <font color='MediumVioletRed'>压缩(选择快的)</font>
|
||||
|
||||
设置map端输出中间结、果压缩。(不完全是解决数据倾斜的问题,但是减少了IO读写和网络传输,能提高很多效率)
|
||||
|
||||
|
||||
- <font color='MediumVioletRed'>小文件进行合并</font>
|
||||
|
||||
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
|
||||
|
||||
- <font color='MediumVioletRed'>其他</font>
|
||||
|
||||
<font color='RoyalBlue'>列式存储,采用分区技术,开启JVM重用</font>...类似的技术非常多,大家选择一些方便记忆的就足以在面试时回答这道题。
|
||||
|
||||
> **拓展:**
|
||||
> 想了解更多关于Hive/HiveSQL常用优化方法可以参考**苹果大数据布道师**王知无前辈的这篇文章:[https://cloud.tencent.com/developer/article/1453464](https://cloud.tencent.com/developer/article/1453464)
|
||||
|
||||
## 9、Hive数据倾斜如何定位 + 怎么解决?
|
||||
倾斜问题非常经典,一般的面试官都会问你如何解决数据倾斜,细致一点的就会问你如何定位数据倾斜以及怎么解决,这里我们也简单地说一下:
|
||||
|
||||
- **Hive 中数据倾斜的基本表现:**
|
||||
|
||||
① 一般都发生在 Sql 中 group by 和 join on 上,而且和数据逻辑绑定比较深。
|
||||
② 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大
|
||||
|
||||
- **如何产生**
|
||||
|
||||
① key的分布不均匀或者说某些key太集中
|
||||
② 业务数据自身的特性,例如不同数据类型关联产生数据倾斜
|
||||
③ SQL语句导致的数据倾斜
|
||||
|
||||
- **如何解决**
|
||||
|
||||
① 开启map端combiner(不影响最终业务逻辑)
|
||||
② 开启数据倾斜时负载均衡
|
||||
③ 控制空值分布
|
||||
|
||||
> <font color='black'>将为空的key转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分配到多个Reducer</font>
|
||||
|
||||
|
||||
④ SQL语句调整
|
||||
|
||||
> <font color='black'>a ) 选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表join的时候,数据量相对变小的效果。
|
||||
>
|
||||
> b ) 大小表Join:使用map join让小的维度表(1000条以下的记录条数)先进内存。在Map端完成Reduce。
|
||||
>
|
||||
> c ) 大表Join大表:把空值的Key变成一个字符串加上一个随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终的结果。
|
||||
>
|
||||
> d ) count distinct大量相同特殊值:count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。</font>
|
||||
|
||||
|
||||
## 10、Hive如何避免小文件的产生,你会如何处理大量小文件?
|
||||
关于小文件如何处理,也已经是老生常谈的问题。
|
||||
|
||||
小文件产生的原因有很多,例如:读取数据源时的大量小文件,使用动态分区插入数据时产生,Reduce/Task数量较多。
|
||||
|
||||
我们都知道,HDFS文件元数据存储在 NameNode 的内存中,在 内存空间有限的情况下,小文件过多会影响NameNode 的寿命,同时影响计算引擎的任务数量,比如每个小的文件都会生成一个Map任务。
|
||||
|
||||
那到底该如何解决小文件过多的问题呢?
|
||||
|
||||
**解决的方法有:**
|
||||
|
||||
(1)合并小文件:对小文件进行归档(Har)、自定义Inputformat将小文件存储成SequenceFile文件。
|
||||
|
||||
(2)采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景。
|
||||
|
||||
(3)对于大量小文件Job,可以开启JVM重用。
|
||||
|
||||
(4)当然,也可以直接设置相关的参数
|
||||
|
||||
设置map输入的小文件合并:
|
||||
```bash
|
||||
set mapped. max split size=256000000
|
||||
//一个节点上 split的至少的大小〔这个值决定了多个 DataNode上的文件是否需要合并
|
||||
set mapred. in split. size per.node=100000000
|
||||
//一个交换机下 split的至少的大小〔这个值决定了多个交换机上的文件是否需要合并
|
||||
/执行Map前进行小文件合井
|
||||
set hive. input format=org. apache hadoop. hive. ql.io.CombineHiveInputFormat:
|
||||
```
|
||||
|
||||
设置 map 输出 和 reduce 输出 进行合并的相关参数
|
||||
```bash
|
||||
//设置map端输出进行合并,默认为true
|
||||
set hive. merge mapfiles =true
|
||||
//设置 reduce端输出进行合并,默认为 false
|
||||
set hive. merge. mapredfiles=true
|
||||
//设置合并文件的大小
|
||||
set hive. merge.size.per.task =256*1000*1000
|
||||
//当输出文件的平均大小小于该值时,启动一个独立的 MapReduce任务进行文件 merge
|
||||
set hive.merge.smallfiles.avgsize= 16000000
|
||||
```
|
||||
|
||||
## 小结
|
||||
本篇文章虽然就只写了10个Hive 的考点,但是也花了我不少的精力去整理这些内容。相信大家在看完之后,多少会有点意犹未尽的感觉。如果哪里解释的不到位,也欢迎在评论区或者后台私信我留言讨论 ~ 同时也欢迎大家点个关注,后续其他高频的面试题我也都会整理出来,敬请期待!
|
||||
|
||||
最后再叨叨几句,**<font color=' RoyalBlue'>面试永远是最快查缺补漏的方法,但如果不作任何准备就前去当炮灰,这毫无意义</font>** 。
|
||||
|
||||
## 彩蛋
|
||||
听说你在找我标题中所提到的“**108份面经**”,这当然不是标题党,需要的话请联系我,毕竟**独乐乐不如众乐乐**~
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user