Update
This commit is contained in:
651
problems/kamacoder/0047.参会dijkstra堆.md
Normal file
651
problems/kamacoder/0047.参会dijkstra堆.md
Normal file
@@ -0,0 +1,651 @@
|
||||
|
||||
# dijkstra(堆优化版)精讲
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1047)
|
||||
|
||||
【题目描述】
|
||||
|
||||
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
|
||||
|
||||
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
|
||||
|
||||
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
|
||||
|
||||
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
|
||||
|
||||
【输出描述】
|
||||
|
||||
输出一个整数,代表小明从起点到终点所花费的最小时间。
|
||||
|
||||
输入示例
|
||||
|
||||
```
|
||||
7 9
|
||||
1 2 1
|
||||
1 3 4
|
||||
2 3 2
|
||||
2 4 5
|
||||
3 4 2
|
||||
4 5 3
|
||||
2 6 4
|
||||
5 7 4
|
||||
6 7 9
|
||||
```
|
||||
|
||||
输出示例:12
|
||||
|
||||
【提示信息】
|
||||
|
||||
能够到达的情况:
|
||||
|
||||
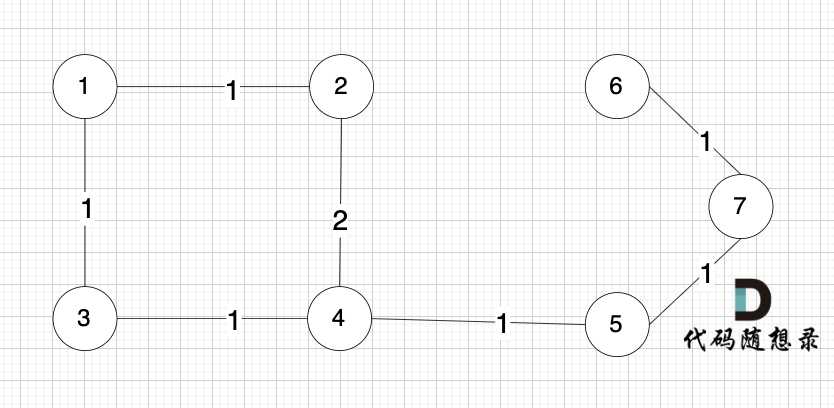
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
|
||||
|
||||

|
||||
|
||||
不能到达的情况:
|
||||
|
||||
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
|
||||
|
||||

|
||||
|
||||
数据范围:
|
||||
|
||||
1 <= N <= 500;
|
||||
1 <= M <= 5000;
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
> 本篇我们来讲解 堆优化版dijkstra,看本篇之前,一定要先看 我讲解的 朴素版dijkstra,否则本篇会有部分内容看不懂。
|
||||
|
||||
在上一篇中,我们讲解了朴素版的dijkstra,该解法的时间复杂度为 O(n^2),可以看出时间复杂度 只和 n (节点数量)有关系。
|
||||
|
||||
如果n很大的话,我们可以换一个角度来优先性能。
|
||||
|
||||
在 讲解 最小生成树的时候,我们 讲了两个算法,[prim算法](https://mp.weixin.qq.com/s/yX936hHC6Z10K36Vm1Wl9w)(从点的角度来求最小生成树)、[Kruskal算法](https://mp.weixin.qq.com/s/rUVaBjCES_4eSjngceT5bw)(从边的角度来求最小生成树)
|
||||
|
||||
这么在n 很大的时候,也有另一个思考维度,即:从边的数量出发。
|
||||
|
||||
当 n 很大,边 的数量 也很多的时候(稠密图),那么 上述解法没问题。
|
||||
|
||||
但 n 很大,边 的数量 很小的时候(稀疏图),是不是可以换成从边的角度来求最短路呢?
|
||||
|
||||
毕竟边的数量少。
|
||||
|
||||
有的录友可能会想,n (节点数量)很大,边不就多吗? 怎么会边的数量少呢?
|
||||
|
||||
别忘了,谁也没有规定 节点之间一定要有边连接着,例如有一万个节点,只有一条边,这也是一张图。
|
||||
|
||||
了解背景之后,再来看 解法思路。
|
||||
|
||||
### 图的存储
|
||||
|
||||
首先是 图的存储。
|
||||
|
||||
关于图的存储 主流有两种方式: 邻接矩阵和邻接表
|
||||
|
||||
#### 邻接矩阵
|
||||
|
||||
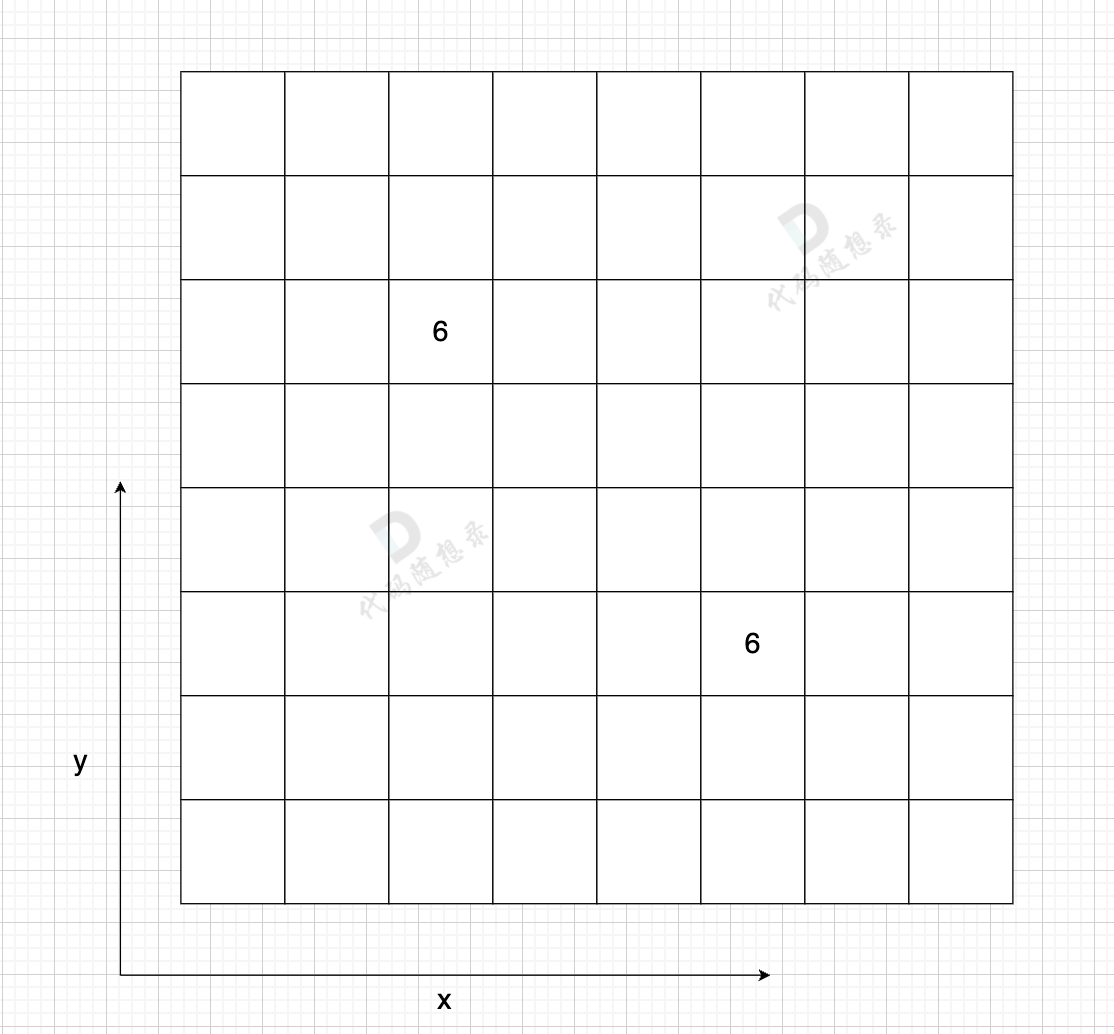
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
|
||||
|
||||
例如: grid[2][5] = 6,表示 节点 2 链接 节点5 为有向图,节点2 指向 节点5,边的权值为6 (套在题意里,可能是距离为6 或者 消耗为6 等等)
|
||||
|
||||
如果想表示无向图,即:grid[2][5] = 6,grid[5][2] = 6,表示节点2 与 节点5 相互连通,权值为6。
|
||||
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间,有一条双向边,即:grid[2][5] = 6,grid[5][2] = 6
|
||||
|
||||
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
|
||||
|
||||
而且在寻找节点链接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
|
||||
|
||||
邻接矩阵的优点:
|
||||
|
||||
* 表达方式简单,易于理解
|
||||
* 检查任意两个顶点间是否存在边的操作非常快
|
||||
* 适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
|
||||
|
||||
缺点:
|
||||
|
||||
* 遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
|
||||
|
||||
#### 邻接表
|
||||
|
||||
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
|
||||
|
||||
邻接表的构造如图:
|
||||
|
||||

|
||||
|
||||
这里表达的图是:
|
||||
|
||||
* 节点1 指向 节点3 和 节点5
|
||||
* 节点2 指向 节点4、节点3、节点5
|
||||
* 节点3 指向 节点4,节点4指向节点1。
|
||||
|
||||
有多少边 邻接表才会申请多少个对应的链表节点。
|
||||
|
||||
从图中可以直观看出 使用 数组 + 链表 来表达 边的链接情况 。
|
||||
|
||||
邻接表的优点:
|
||||
|
||||
* 对于稀疏图的存储,只需要存储边,空间利用率高
|
||||
* 遍历节点链接情况相对容易
|
||||
|
||||
缺点:
|
||||
|
||||
* 检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点链接其他节点的数量。
|
||||
* 实现相对复杂,不易理解
|
||||
|
||||
#### 本题图的存储
|
||||
|
||||
接下来我们继续按照稀疏图的角度来分析本题。
|
||||
|
||||
在第一个版本的实现思路中,我们提到了三部曲:
|
||||
|
||||
1. 第一步,选源点到哪个节点近且该节点未被访问过
|
||||
2. 第二步,该最近节点被标记访问过
|
||||
3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
|
||||
在第一个版本的代码中,这三部曲是套在一个 for 循环里,为什么?
|
||||
|
||||
因为我们是从节点的角度来解决问题。
|
||||
|
||||
三部曲中第一步(选源点到哪个节点近且该节点未被访问过),这个操作本身需要for循环遍历 minDist 来寻找最近的节点。
|
||||
|
||||
同时我们需要 遍历所有 未访问过的节点,所以 我们从 节点角度出发,代码会有两层for循环,代码是这样的: (注意代码中的注释,标记两层for循环的用处)
|
||||
|
||||
```CPP
|
||||
|
||||
for (int i = 1; i <= n; i++) { // 遍历所有节点,第一层for循环
|
||||
|
||||
int minVal = INT_MAX;
|
||||
int cur = 1;
|
||||
|
||||
// 1、选距离源点最近且未访问过的节点 , 第二层for循环
|
||||
for (int v = 1; v <= n; ++v) {
|
||||
if (!visited[v] && minDist[v] < minVal) {
|
||||
minVal = minDist[v];
|
||||
cur = v;
|
||||
}
|
||||
}
|
||||
|
||||
visited[cur] = true; // 2、标记该节点已被访问
|
||||
|
||||
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
那么当从 边 的角度出发, 在处理 三部曲里的第一步(选源点到哪个节点近且该节点未被访问过)的时候 ,我们可以不用去遍历所有节点了。
|
||||
|
||||
而且 直接把 边(带权值)加入到 小顶堆(利用堆来自动排序),那么每次我们从 堆顶里 取出 边 自然就是 距离源点最近的节点所在的边。
|
||||
|
||||
这样我们就不需要两层for循环来寻找最近的节点了。
|
||||
|
||||
了解了大体思路,我们再来看代码实现。
|
||||
|
||||
首先是 如何使用 邻接表来表述图结构,这是摆在很多录友面前的第一个难题。
|
||||
|
||||
邻接表用 数组+链表 来表示,代码如下:(C++中 vector 为数组,list 为链表, 定义了 n+1 这么大的数组空间)
|
||||
|
||||
```CPP
|
||||
vector<list<int>> grid(n + 1);
|
||||
```
|
||||
|
||||
不少录友,不知道 如何定义的数据结构,怎么表示邻接表的,我来给大家画一个图:
|
||||
|
||||

|
||||
|
||||
图中邻接表表示:
|
||||
|
||||
* 节点1 指向 节点3 和 节点5
|
||||
* 节点2 指向 节点4、节点3、节点5
|
||||
* 节点3 指向 节点4
|
||||
* 节点4 指向 节点1
|
||||
|
||||
大家发现图中的边没有权值,而本题中 我们的边是有权值的,权值怎么表示?在哪里表示?
|
||||
|
||||
所以 在`vector<list<int>> grid(n + 1);` 中 就不能使用int了,而是需要一个键值对 来存两个数字,一个数表示节点,一个数表示 指向该节点的这条边的权值。
|
||||
|
||||
那么 代码可以改成这样: (pair 为键值对,可以存放两个int)
|
||||
|
||||
```CPP
|
||||
vector<list<pair<int,int>>> grid(n + 1);
|
||||
```
|
||||
|
||||
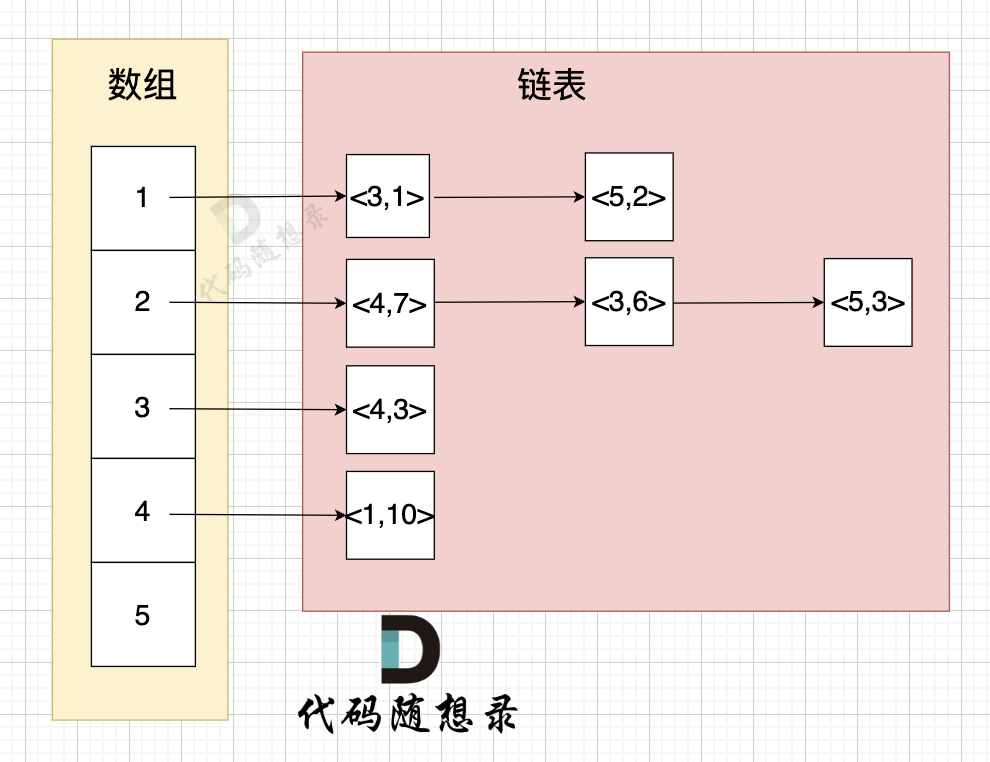
举例来给大家展示 该代码表达的数据 如下:
|
||||
|
||||
|
||||
|
||||
* 节点1 指向 节点3 权值为 1
|
||||
* 节点1 指向 节点5 权值为 2
|
||||
* 节点2 指向 节点4 权值为 7
|
||||
* 节点2 指向 节点3 权值为 6
|
||||
* 节点2 指向 节点5 权值为 3
|
||||
* 节点3 指向 节点4 权值为 3
|
||||
* 节点5 指向 节点1 权值为 10
|
||||
|
||||
这样 我们就把图中权值表示出来了。
|
||||
|
||||
但是在代码中 使用 `pair<int, int>` 很容易让我们搞混了,第一个int 表示什么,第二个int表示什么,导致代码可读性很差,或者说别人看你的代码看不懂。
|
||||
|
||||
那么 可以 定一个类 来取代 `pair<int, int>`
|
||||
|
||||
类(或者说是结构体)定义如下:
|
||||
|
||||
```CPP
|
||||
struct Edge {
|
||||
int to; // 邻接顶点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
```
|
||||
|
||||
这个类里有两个成员变量,有对应的命名,这样不容易搞混 两个int的含义。
|
||||
|
||||
所以 本题中邻接表的定义如下:
|
||||
|
||||
```CPP
|
||||
struct Edge {
|
||||
int to; // 链接的节点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
vector<list<Edge>> grid(n + 1); // 邻接表
|
||||
|
||||
```
|
||||
|
||||
(我们在下面的讲解中会直接使用这个邻接表的代码表示方式)
|
||||
|
||||
### 堆优化细节
|
||||
|
||||
其实思路依然是 dijkstra 三部曲:
|
||||
|
||||
1. 第一步,选源点到哪个节点近且该节点未被访问过
|
||||
2. 第二步,该最近节点被标记访问过
|
||||
3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
|
||||
只不过之前是 通过遍历节点来遍历边,通过两层for循环来寻找距离源点最近节点。 这次我们直接遍历边,且通过堆来对边进行排序,达到直接选择距离源点最近节点。
|
||||
|
||||
先来看一下针对这三部曲,如果用 堆来优化。
|
||||
|
||||
那么三部曲中的第一步(选源点到哪个节点近且该节点未被访问过),我们如何选?
|
||||
|
||||
我们要选择距离源点近的节点(即:该边的权值最小),所以 我们需要一个 小顶堆 来帮我们对边的权值排序,每次从小顶堆堆顶 取边就是权值最小的边。
|
||||
|
||||
C++定义小顶堆,可以用优先级队列实现,代码如下:
|
||||
|
||||
```CPP
|
||||
// 小顶堆
|
||||
class mycomparison {
|
||||
public:
|
||||
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
|
||||
return lhs.second > rhs.second;
|
||||
}
|
||||
};
|
||||
// 优先队列中存放 pair<节点编号,源点到该节点的权值>
|
||||
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;
|
||||
```
|
||||
|
||||
(`pair<int, int>`中 第二个int 为什么要存 源点到该节点的权值,因为 这个小顶堆需要按照权值来排序)
|
||||
|
||||
|
||||
有了小顶堆自动对边的权值排序,那我们只需要直接从 堆里取堆顶元素(小顶堆中,最小的权值在上面),就可以取到离源点最近的节点了 (未访问过的节点,不会加到堆里进行排序)
|
||||
|
||||
所以三部曲中的第一步,我们不用 for循环去遍历,直接取堆顶元素:
|
||||
|
||||
```CPP
|
||||
// pair<节点编号,源点到该节点的权值>
|
||||
pair<int, int> cur = pq.top(); pq.pop();
|
||||
|
||||
```
|
||||
|
||||
第二步(该最近节点被标记访问过) 这个就是将 节点做访问标记,和 朴素dijkstra 一样 ,代码如下:
|
||||
|
||||
```CPP
|
||||
// 2. 第二步,该最近节点被标记访问过
|
||||
visited[cur.first] = true;
|
||||
|
||||
```
|
||||
|
||||
(`cur.first` 是指取 `pair<int, int>` 里的第一个int,即节点编号 )
|
||||
|
||||
第三步(更新非访问节点到源点的距离),这里的思路 也是 和朴素dijkstra一样的。
|
||||
|
||||
但很多录友对这里是最懵的,主要是因为两点:
|
||||
|
||||
* 没有理解透彻 dijkstra 的思路
|
||||
* 没有理解 邻接表的表达方式
|
||||
|
||||
我们来回顾一下 朴素dijkstra 在这一步的代码和思路(如果没看过我讲解的朴素版dijkstra,这里会看不懂)
|
||||
|
||||
```CPP
|
||||
|
||||
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
其中 for循环是用来做什么的? 是为了 找到 节点cur 链接指向了哪些节点,因为使用邻接矩阵的表达方式 所以把所有节点遍历一遍。
|
||||
|
||||
而在邻接表中,我们可以以相对高效的方式知道一个节点链接指向哪些节点。
|
||||
|
||||
再回顾一下邻接表的构造(数组 + 链表):
|
||||
|
||||

|
||||
|
||||
假如 加入的cur 是节点 2, 那么 grid[2] 表示的就是图中第二行链表。 (grid数组的构造我们在 上面 「图的存储」中讲过)
|
||||
|
||||
所以在邻接表中,我们要获取 节点cur 链接指向哪些节点,就是遍历 grid[cur节点编号] 这个链表。
|
||||
|
||||
这个遍历方式,C++代码如下:
|
||||
|
||||
```CPP
|
||||
for (Edge edge : grid[cur.first])
|
||||
```
|
||||
|
||||
(如果不知道 Edge 是什么,看上面「图的存储」中邻接表的讲解)
|
||||
|
||||
`cur.first` 就是cur节点编号, 参考上面pair的定义: pair<节点编号,源点到该节点的权值>
|
||||
|
||||
接下来就是更新 非访问节点到源点的距离,代码实现和 朴素dijkstra 是一样的,代码如下:
|
||||
|
||||
```CPP
|
||||
// 3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (Edge edge : grid[cur.first]) { // 遍历 cur指向的节点,cur指向的节点为 edge
|
||||
// cur指向的节点edge.to,这条边的权值为 edge.val
|
||||
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
|
||||
minDist[edge.to] = minDist[cur.first] + edge.val;
|
||||
pq.push(pair<int, int>(edge.to, minDist[edge.to]));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
但为什么思路一样,有的录友能写出朴素dijkstra,但堆优化这里的逻辑就是写不出来呢?
|
||||
|
||||
**主要就是因为对邻接表的表达方式不熟悉**!
|
||||
|
||||
以上代码中,cur 链接指向的节点编号 为 edge.to, 这条边的权值为 edge.val ,如果对这里模糊的就再回顾一下 Edge的定义:
|
||||
|
||||
```CPP
|
||||
struct Edge {
|
||||
int to; // 邻接顶点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
```
|
||||
|
||||
确定该节点没有被访问过,`!visited[edge.to]` , 目前 源点到cur.first的最短距离(minDist) + cur.first 到 edge.to 的距离 (edge.val) 是否 小于 minDist已经记录的 源点到 edge.to 的距离 (minDist[edge.to])
|
||||
|
||||
如果是的话,就开始更新操作。
|
||||
|
||||
即:
|
||||
|
||||
```CPP
|
||||
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
|
||||
minDist[edge.to] = minDist[cur.first] + edge.val;
|
||||
pq.push(pair<int, int>(edge.to, minDist[edge.to])); // 由于cur节点的加入,而新链接的边,加入到优先级队里中
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
同时,由于cur节点的加入,源点又有可以新链接到的边,将这些边加入到优先级队里中。
|
||||
|
||||
|
||||
以上代码思路 和 朴素版dijkstra 是一样一样的,主要区别是两点:
|
||||
|
||||
* 邻接表的表示方式不同
|
||||
* 使用优先级队列(小顶堆)来对新链接的边排序
|
||||
|
||||
### 代码实现
|
||||
|
||||
堆优化dijkstra完整代码如下:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <queue>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
// 小顶堆
|
||||
class mycomparison {
|
||||
public:
|
||||
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
|
||||
return lhs.second > rhs.second;
|
||||
}
|
||||
};
|
||||
// 定义一个结构体来表示带权重的边
|
||||
struct Edge {
|
||||
int to; // 邻接顶点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<list<Edge>> grid(n + 1);
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1].push_back(Edge(p2, val));
|
||||
|
||||
}
|
||||
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
// 存储从源点到每个节点的最短距离
|
||||
std::vector<int> minDist(n + 1, INT_MAX);
|
||||
|
||||
// 记录顶点是否被访问过
|
||||
std::vector<bool> visited(n + 1, false);
|
||||
|
||||
// 优先队列中存放 pair<节点,源点到该节点的权值>
|
||||
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;
|
||||
|
||||
|
||||
// 初始化队列,源点到源点的距离为0,所以初始为0
|
||||
pq.push(pair<int, int>(start, 0));
|
||||
|
||||
minDist[start] = 0; // 起始点到自身的距离为0
|
||||
|
||||
while (!pq.empty()) {
|
||||
// 1. 第一步,选源点到哪个节点近且该节点未被访问过 (通过优先级队列来实现)
|
||||
// <节点, 源点到该节点的距离>
|
||||
pair<int, int> cur = pq.top(); pq.pop();
|
||||
|
||||
if (visited[cur.first]) continue;
|
||||
|
||||
// 2. 第二步,该最近节点被标记访问过
|
||||
visited[cur.first] = true;
|
||||
|
||||
// 3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (Edge edge : grid[cur.first]) { // 遍历 cur指向的节点,cur指向的节点为 edge
|
||||
// cur指向的节点edge.to,这条边的权值为 edge.val
|
||||
if (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDist
|
||||
minDist[edge.to] = minDist[cur.first] + edge.val;
|
||||
pq.push(pair<int, int>(edge.to, minDist[edge.to]));
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度:O(ElogE) E 为边的数量
|
||||
* 空间复杂度:O(N + E) N 为节点的数量
|
||||
|
||||
堆优化的时间复杂度 只和边的数量有关 和节点数无关,在 优先级队列中 放的也是边。
|
||||
|
||||
以上代码中,`while (!pq.empty())` 里套了 `for (Edge edge : grid[cur.first])`
|
||||
|
||||
`for` 里 遍历的是 当前节点 cur 所连接边。
|
||||
|
||||
那 当前节点cur 所连接的边 也是不固定的, 这就让大家分不清,这时间复杂度究竟是多少?
|
||||
|
||||
其实 `for (Edge edge : grid[cur.first])` 里最终的数据走向 是 给队列里添加边。
|
||||
|
||||
那么跳出局部代码,整个队列 一定是 所有边添加了一次,同时也弹出了一次。
|
||||
|
||||
所以边添加一次时间复杂度是 O(E), `while (!pq.empty())` 里每次都要弹出一个边来进行操作,在优先级队列(小顶堆)中 弹出一个元素的时间复杂度是 O(logE) ,这是堆排序的时间复杂度。
|
||||
|
||||
(当然小顶堆里 是 添加元素的时候 排序,还是 取数元素的时候排序,这个无所谓,时间复杂度都是O(E),总之是一定要排序的,而小顶堆里也不会滞留元素,有多少元素添加 一定就有多少元素弹出)
|
||||
|
||||
所以 该算法整体时间复杂度为 O(ElogE)
|
||||
|
||||
网上的不少分析 会把 n (节点的数量)算进来,这个分析是有问题的,举一个极端例子,在n 为 10000,且是有一条边的 图里,以上代码,大家感觉执行了多少次?
|
||||
|
||||
`while (!pq.empty())` 中的 pq 存的是边,其实只执行了一次。
|
||||
|
||||
所以该算法时间复杂度 和 节点没有关系。
|
||||
|
||||
至于空间复杂度,邻接表是 数组 + 链表 数组的空间 是 N ,有E条边 就申请对应多少个链表节点,所以是 复杂度是 N + E
|
||||
|
||||
## 拓展
|
||||
|
||||
当然也有录友可能想 堆优化dijkstra 中 我为什么一定要用邻接表呢,我就用邻接矩阵 行不行 ?
|
||||
|
||||
也行的。
|
||||
|
||||
但 正是因为稀疏图,所以我们使用堆优化的思路, 如果我们还用 邻接矩阵 去表达这个图的话,就是 **一个高效的算法 使用了低效的数据结构,那么 整体算法效率 依然是低的**。
|
||||
|
||||
如果还不清楚为什么要使用 邻接表,可以再看看上面 我在 「图的存储」标题下的讲解。
|
||||
|
||||
这里我也给出 邻接矩阵版本的堆优化dijkstra代码:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
// 小顶堆
|
||||
class mycomparison {
|
||||
public:
|
||||
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
|
||||
return lhs.second > rhs.second;
|
||||
}
|
||||
};
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1][p2] = val;
|
||||
}
|
||||
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
// 存储从源点到每个节点的最短距离
|
||||
std::vector<int> minDist(n + 1, INT_MAX);
|
||||
|
||||
// 记录顶点是否被访问过
|
||||
std::vector<bool> visited(n + 1, false);
|
||||
|
||||
// 优先队列中存放 pair<节点,源点到该节点的距离>
|
||||
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;
|
||||
|
||||
|
||||
// 初始化队列,源点到源点的距离为0,所以初始为0
|
||||
pq.push(pair<int, int>(start, 0));
|
||||
|
||||
minDist[start] = 0; // 起始点到自身的距离为0
|
||||
|
||||
while (!pq.empty()) {
|
||||
// <节点, 源点到该节点的距离>
|
||||
// 1、选距离源点最近且未访问过的节点
|
||||
pair<int, int> cur = pq.top(); pq.pop();
|
||||
|
||||
if (visited[cur.first]) continue;
|
||||
|
||||
visited[cur.first] = true; // 2、标记该节点已被访问
|
||||
|
||||
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (int j = 1; j <= n; j++) {
|
||||
if (!visited[j] && grid[cur.first][j] != INT_MAX && (minDist[cur.first] + grid[cur.first][j] < minDist[j])) {
|
||||
minDist[j] = minDist[cur.first] + grid[cur.first][j];
|
||||
pq.push(pair<int, int>(j, minDist[j]));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度:O(E * (N + logE)) E为边的数量,N为节点数量
|
||||
* 空间复杂度:O(log(N^2))
|
||||
|
||||
`while (!pq.empty())` 时间复杂度为 E ,while 里面 每次取元素 时间复杂度 为 logE,和 一个for循环 时间复杂度 为 N 。
|
||||
|
||||
所以整体是 E * (N + logE)
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
在学习一种优化思路的时候,首先就要知道为什么要优化,遇到了什么问题。
|
||||
|
||||
正如我在开篇就给大家交代清楚 堆优化方式的背景。
|
||||
|
||||
堆优化的整体思路和 朴素版是大体一样的,区别是 堆优化从边的角度出发且利用堆来排序。
|
||||
|
||||
很多录友别说写堆优化 就是看 堆优化的代码也看的很懵。
|
||||
|
||||
主要是因为两点:
|
||||
|
||||
* 不熟悉邻接表的表达方式
|
||||
* 对dijkstra的实现思路还是不熟
|
||||
|
||||
这是我为什么 本篇花了大力气来讲解 图的存储,就是为了让大家彻底理解邻接表以及邻接表的代码写法。
|
||||
|
||||
至于 dijkstra的实现思路 ,朴素版 和 堆优化版本 都是 按照 dijkstra 三部曲来的。
|
||||
|
||||
理解了三部曲,dijkstra 的思路就是清晰的。
|
||||
|
||||
针对邻接表版本代码 我做了详细的 时间复杂度分析,也让录友们清楚,相对于 朴素版,时间都优化到哪了。
|
||||
|
||||
最后 我也给出了 邻接矩阵的版本代码,分析了这一版本的必要性以及时间复杂度。
|
||||
|
||||
至此通过 两篇dijkstra的文章,终于把 dijkstra 讲完了,如果大家对我讲解里所涉及的内容都吃透的话,详细对 dijkstra 算法也就理解到位了。
|
||||
|
||||
|
||||
|
||||
733
problems/kamacoder/0047.参会dijkstra朴素.md
Normal file
733
problems/kamacoder/0047.参会dijkstra朴素.md
Normal file
@@ -0,0 +1,733 @@
|
||||
|
||||
# dijkstra(朴素版)精讲
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1047)
|
||||
|
||||
【题目描述】
|
||||
|
||||
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
|
||||
|
||||
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
|
||||
|
||||
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
|
||||
|
||||
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
|
||||
|
||||
【输出描述】
|
||||
|
||||
输出一个整数,代表小明从起点到终点所花费的最小时间。
|
||||
|
||||
输入示例
|
||||
|
||||
```
|
||||
7 9
|
||||
1 2 1
|
||||
1 3 4
|
||||
2 3 2
|
||||
2 4 5
|
||||
3 4 2
|
||||
4 5 3
|
||||
2 6 4
|
||||
5 7 4
|
||||
6 7 9
|
||||
```
|
||||
|
||||
输出示例:12
|
||||
|
||||
【提示信息】
|
||||
|
||||
能够到达的情况:
|
||||
|
||||
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
|
||||
|
||||

|
||||
|
||||
不能到达的情况:
|
||||
|
||||
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
|
||||
|
||||

|
||||
|
||||
数据范围:
|
||||
|
||||
1 <= N <= 500;
|
||||
1 <= M <= 5000;
|
||||
|
||||
## 思路
|
||||
|
||||
本题就是求最短路,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
|
||||
|
||||
接下来,我们来详细讲解最短路算法中的 dijkstra 算法。
|
||||
|
||||
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
|
||||
|
||||
需要注意两点:
|
||||
|
||||
* dijkstra 算法可以同时求 起点到所有节点的最短路径
|
||||
* 权值不能为负数
|
||||
|
||||
(这两点后面我们会讲到)
|
||||
|
||||
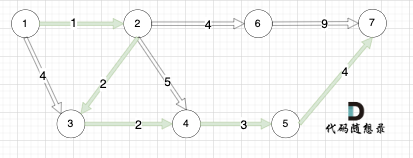
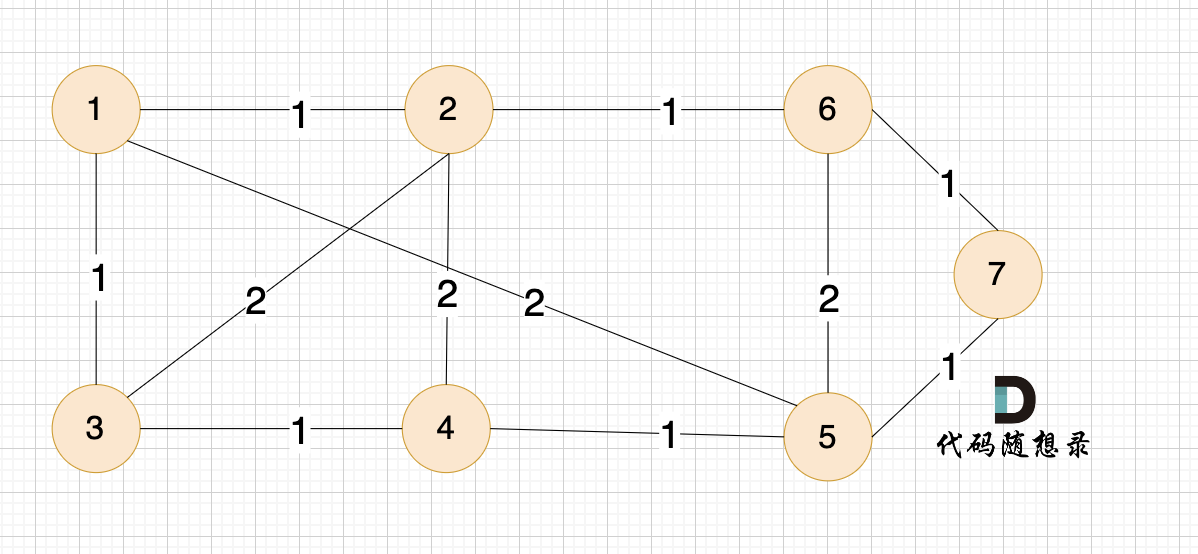
如本题示例中的图:
|
||||
|
||||
|
||||
|
||||
起点(节点1)到终点(节点7) 的最短路径是 图中 标记绿线的部分。
|
||||
|
||||
最短路径的权值为12。
|
||||
|
||||
其实 dijkstra 算法 和 我们之前讲解的prim算法思路非常接近,如果大家认真学过[prim算法](https://mp.weixin.qq.com/s/yX936hHC6Z10K36Vm1Wl9w),那么理解 Dijkstra 算法会相对容易很多。(这也是我要先讲prim再讲dijkstra的原因)
|
||||
|
||||
dijkstra 算法 同样是贪心的思路,不断寻找距离 源点最近的没有访问过的节点。
|
||||
|
||||
这里我也给出 **dijkstra三部曲**:
|
||||
|
||||
1. 第一步,选源点到哪个节点近且该节点未被访问过
|
||||
2. 第二步,该最近节点被标记访问过
|
||||
3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
|
||||
大家此时已经会发现,这和prim算法 怎么这么像呢。
|
||||
|
||||
我在[prim算法](https://mp.weixin.qq.com/s/yX936hHC6Z10K36Vm1Wl9w)讲解中也给出了三部曲。 prim 和 dijkstra 确实很像,思路也是类似的,这一点我在后面还会详细来讲。
|
||||
|
||||
在dijkstra算法中,同样有一个数组很重要,起名为:minDist。
|
||||
|
||||
**minDist数组 用来记录 每一个节点距离源点的最小距离**。
|
||||
|
||||
理解这一点很重要,也是理解 dijkstra 算法的核心所在。
|
||||
|
||||
大家现在看着可能有点懵,不知道什么意思。
|
||||
|
||||
没关系,先让大家有一个印象,对理解后面讲解有帮助。
|
||||
|
||||
我们先来画图看一下 dijkstra 的工作过程,以本题示例为例: (以下为朴素版dijkstra的思路)
|
||||
|
||||
(**示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了,避免大家搞混**)
|
||||
|
||||
## 朴素版dijkstra
|
||||
|
||||
### 模拟过程
|
||||
|
||||
-----------
|
||||
|
||||
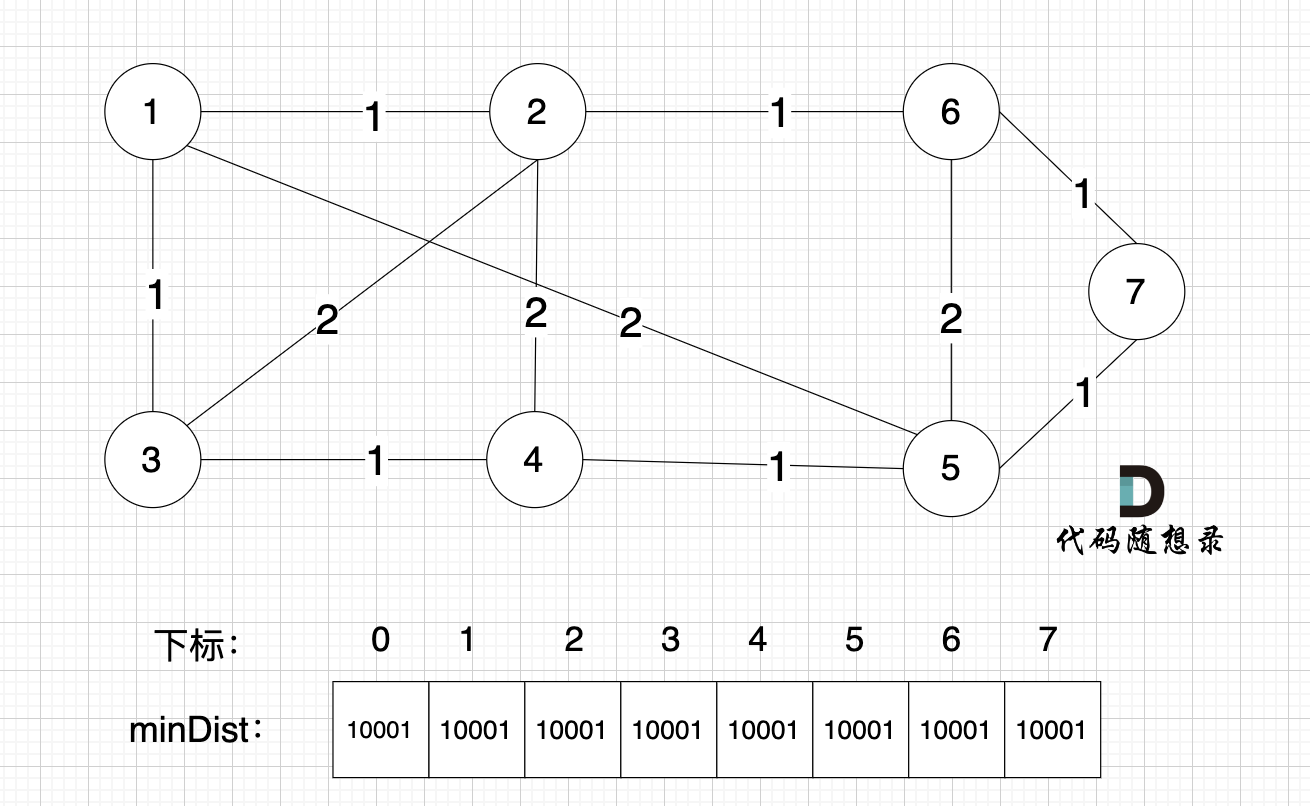
0、初始化
|
||||
|
||||
minDist数组数值初始化为int最大值。
|
||||
|
||||
这里在强点一下 **minDist数组的含义:记录所有节点到源点的最短路径**,那么初始化的时候就应该初始为最大值,这样才能在后续出现最短路径的时候及时更新。
|
||||
|
||||

|
||||
|
||||
(图中,max 表示默认值,节点0 不做处理,统一从下标1 开始计算,这样下标和节点数值统一, 方便大家理解,避免搞混)
|
||||
|
||||
源点(节点1) 到自己的距离为0,所以 minDist[1] = 0
|
||||
|
||||
此时所有节点都没有被访问过,所以 visited数组都为0
|
||||
|
||||
---------------
|
||||
|
||||
以下为dijkstra 三部曲
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离源点最近,距离为0,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记源点访问过
|
||||
|
||||
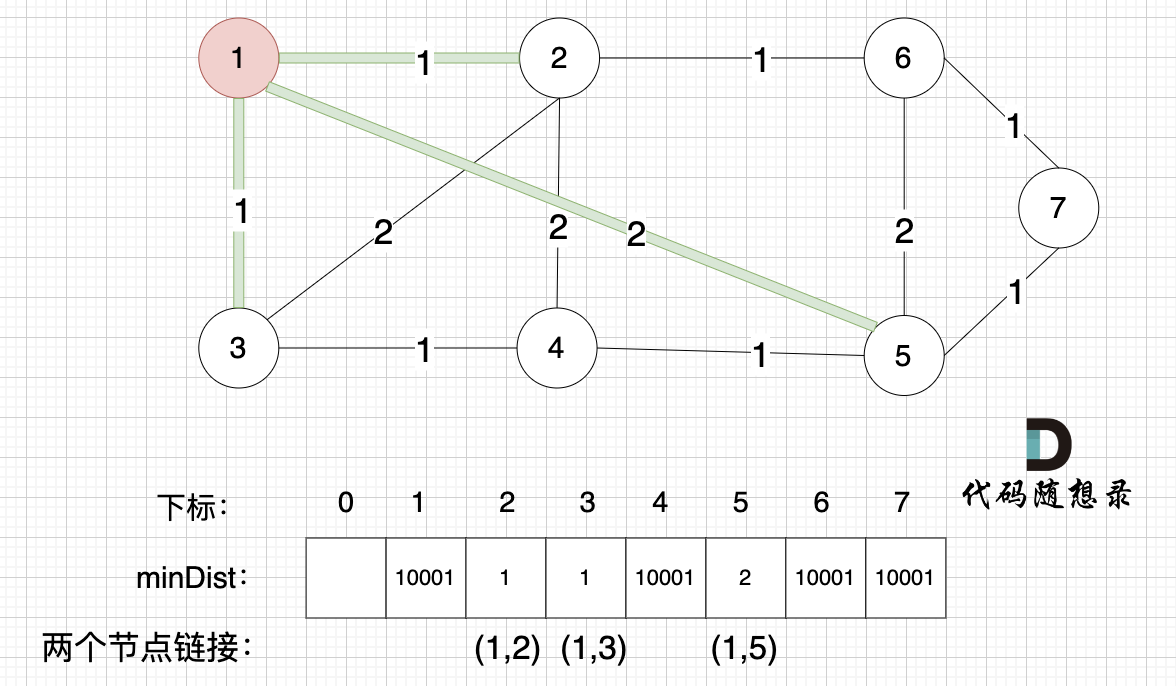
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||

|
||||
|
||||
|
||||
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
|
||||
|
||||
* 源点到节点2的最短距离为1,小于原minDist[2]的数值max,更新minDist[2] = 1
|
||||
* 源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[4] = 4
|
||||
|
||||
可能有录友问:为啥和 minDist[2] 比较?
|
||||
|
||||
再强调一下 minDist[2] 的含义,它表示源点到节点2的最短距离,那么目前我们得到了 源点到节点2的最短距离为1,小于默认值max,所以更新。 minDist[3]的更新同理
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
未访问过的节点中,源点到节点2距离最近,选节点2
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点2被标记访问过
|
||||
|
||||
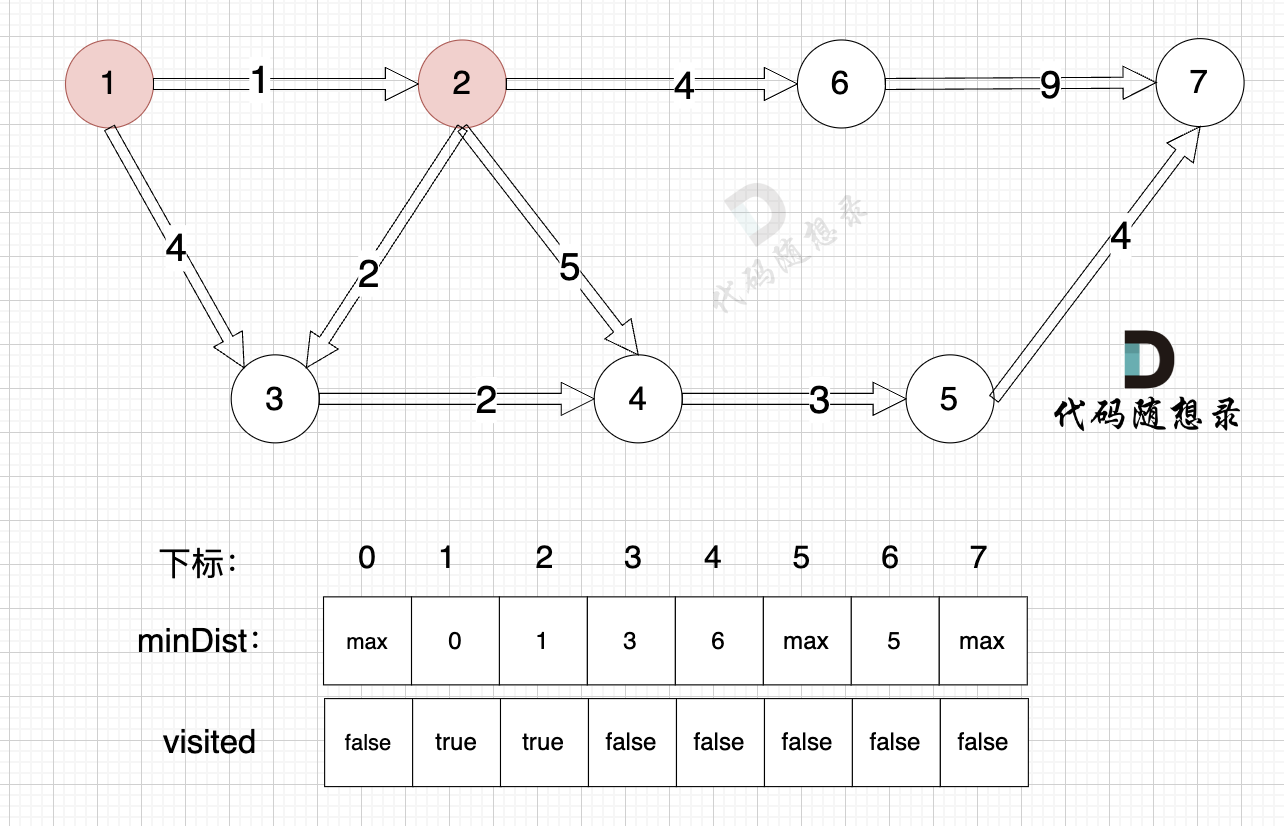
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
更新 minDist数组,即:源点(节点1) 到 节点6 、 节点3 和 节点4的距离。
|
||||
|
||||
**为什么更新这些节点呢? 怎么不更新其他节点呢**?
|
||||
|
||||
因为 源点(节点1)通过 已经计算过的节点(节点2) 可以链接到的节点 有 节点3,节点4和节点6.
|
||||
|
||||
|
||||
更新 minDist数组:
|
||||
|
||||
* 源点到节点6的最短距离为5,小于原minDist[6]的数值max,更新minDist[6] = 5
|
||||
* 源点到节点3的最短距离为3,小于原minDist[3]的数值4,更新minDist[3] = 3
|
||||
* 源点到节点4的最短距离为6,小于原minDist[4]的数值max,更新minDist[4] = 6
|
||||
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
未访问过的节点中,源点距离哪些节点最近,怎么算的?
|
||||
|
||||
其实就是看 minDist数组里的数值,minDist 记录了 源点到所有节点的最近距离,结合visited数组筛选出未访问的节点就好。
|
||||
|
||||
从 上面的图,或者 从minDist数组中,我们都能看出 未访问过的节点中,源点(节点1)到节点3距离最近。
|
||||
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点3被标记访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||

|
||||
|
||||
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
|
||||
|
||||
更新 minDist数组:
|
||||
|
||||
* 源点到节点4的最短距离为5,小于原minDist[4]的数值6,更新minDist[4] = 5
|
||||
|
||||
------------------
|
||||
|
||||
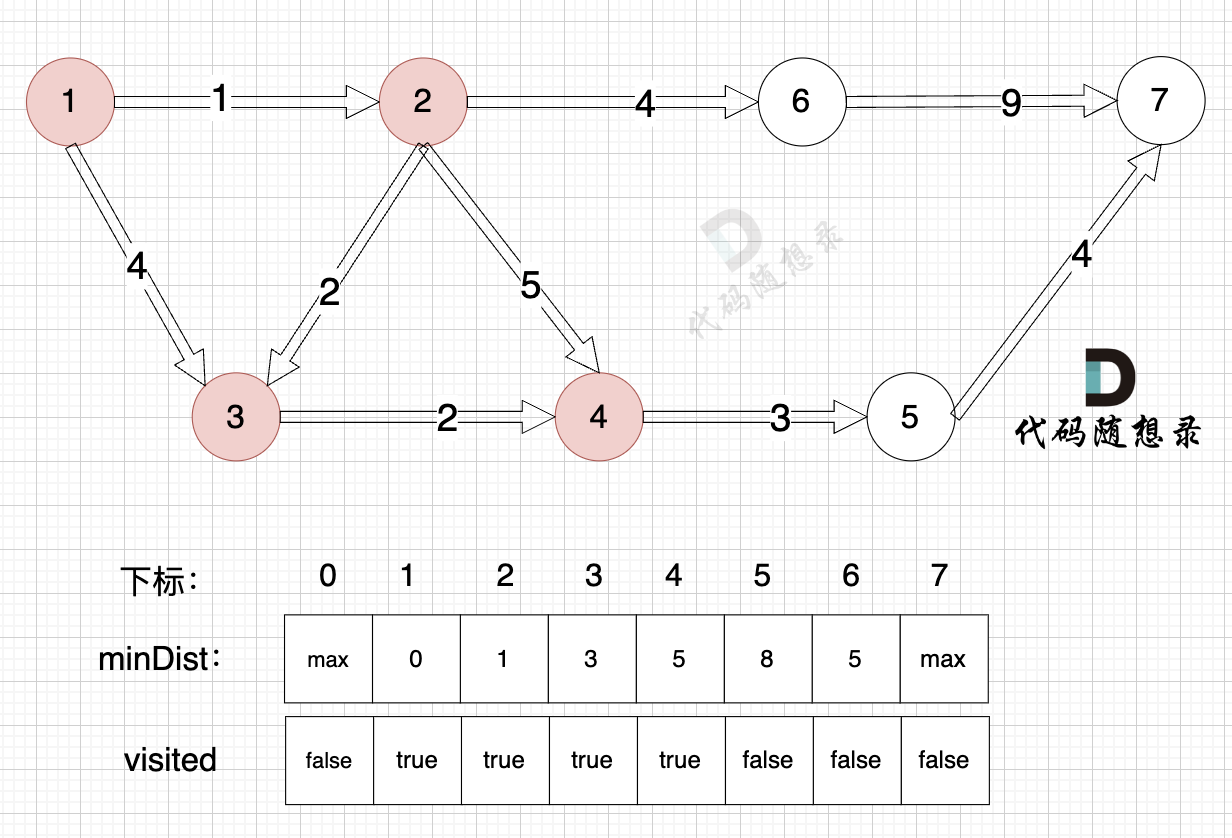
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
距离源点最近且没有被访问过的节点,有节点4 和 节点6,距离源点距离都是 5 (minDist[4] = 5,minDist[6] = 5) ,选哪个节点都可以。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点4被标记访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
由于节点4的加入,那么源点可以链接到节点5 所以更新minDist数组:
|
||||
|
||||
* 源点到节点5的最短距离为8,小于原minDist[5]的数值max,更新minDist[5] = 8
|
||||
|
||||
--------------
|
||||
|
||||
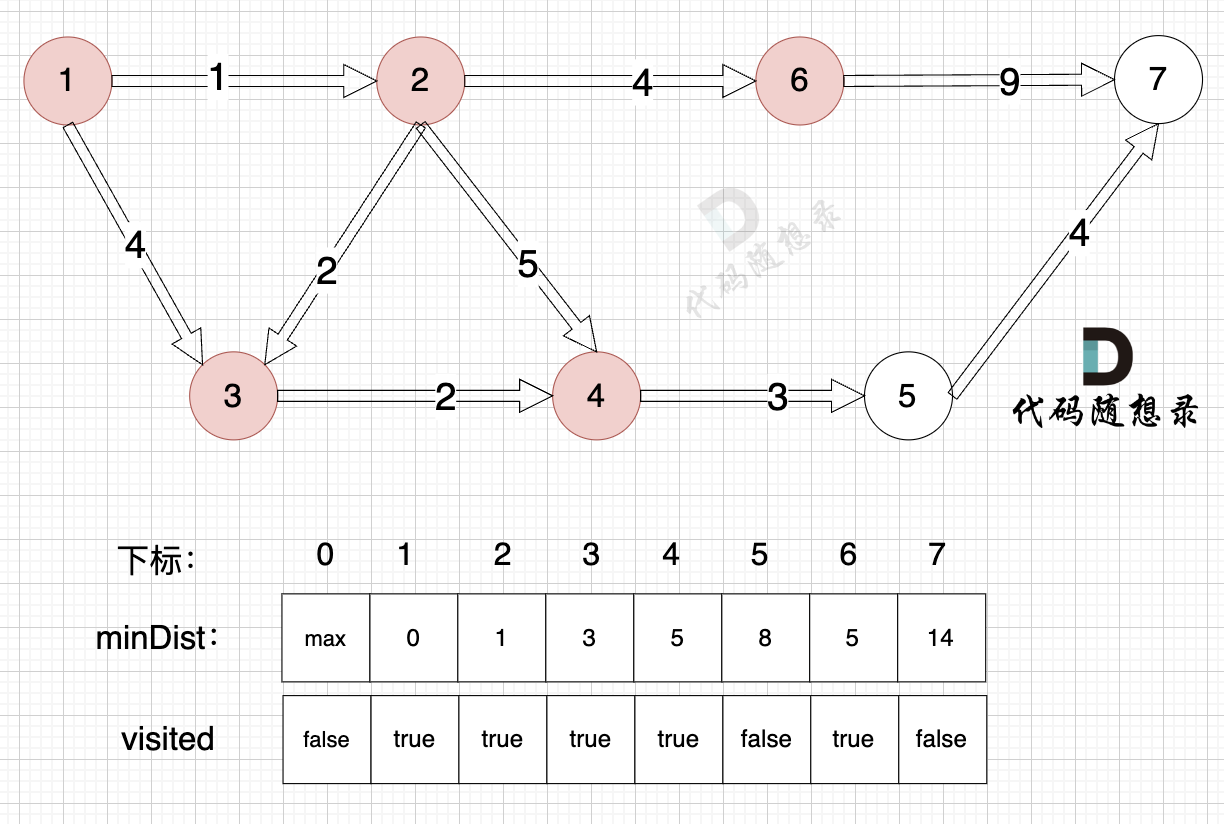
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
距离源点最近且没有被访问过的节点,是节点6,距离源点距离是 5 (minDist[6] = 5)
|
||||
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点6 被标记访问过
|
||||
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
由于节点6的加入,那么源点可以链接到节点7 所以 更新minDist数组:
|
||||
|
||||
* 源点到节点7的最短距离为14,小于原minDist[7]的数值max,更新minDist[7] = 14
|
||||
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
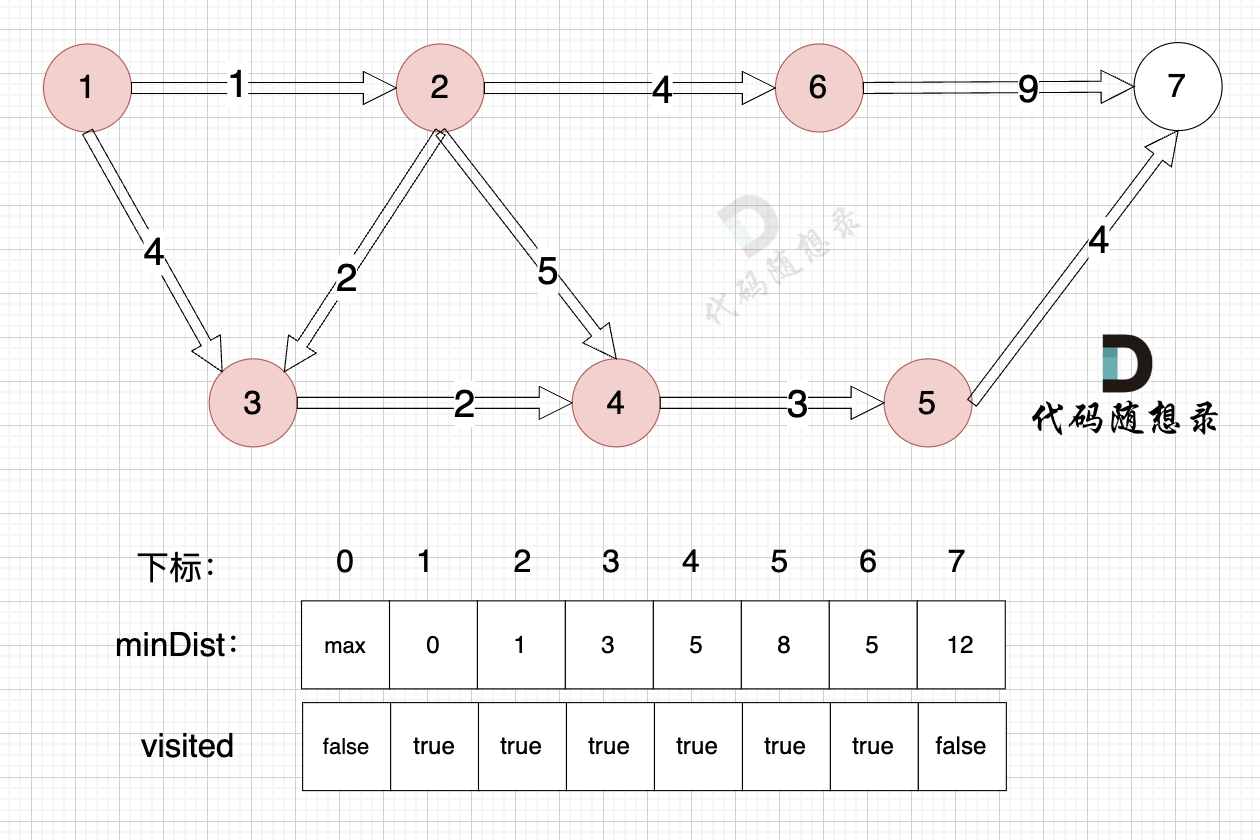
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
距离源点最近且没有被访问过的节点,是节点5,距离源点距离是 8 (minDist[5] = 8)
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点5 被标记访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
由于节点5的加入,那么源点有新的路径可以链接到节点7 所以 更新minDist数组:
|
||||
|
||||
* 源点到节点7的最短距离为12,小于原minDist[7]的数值14,更新minDist[7] = 12
|
||||
|
||||
-----------------
|
||||
|
||||
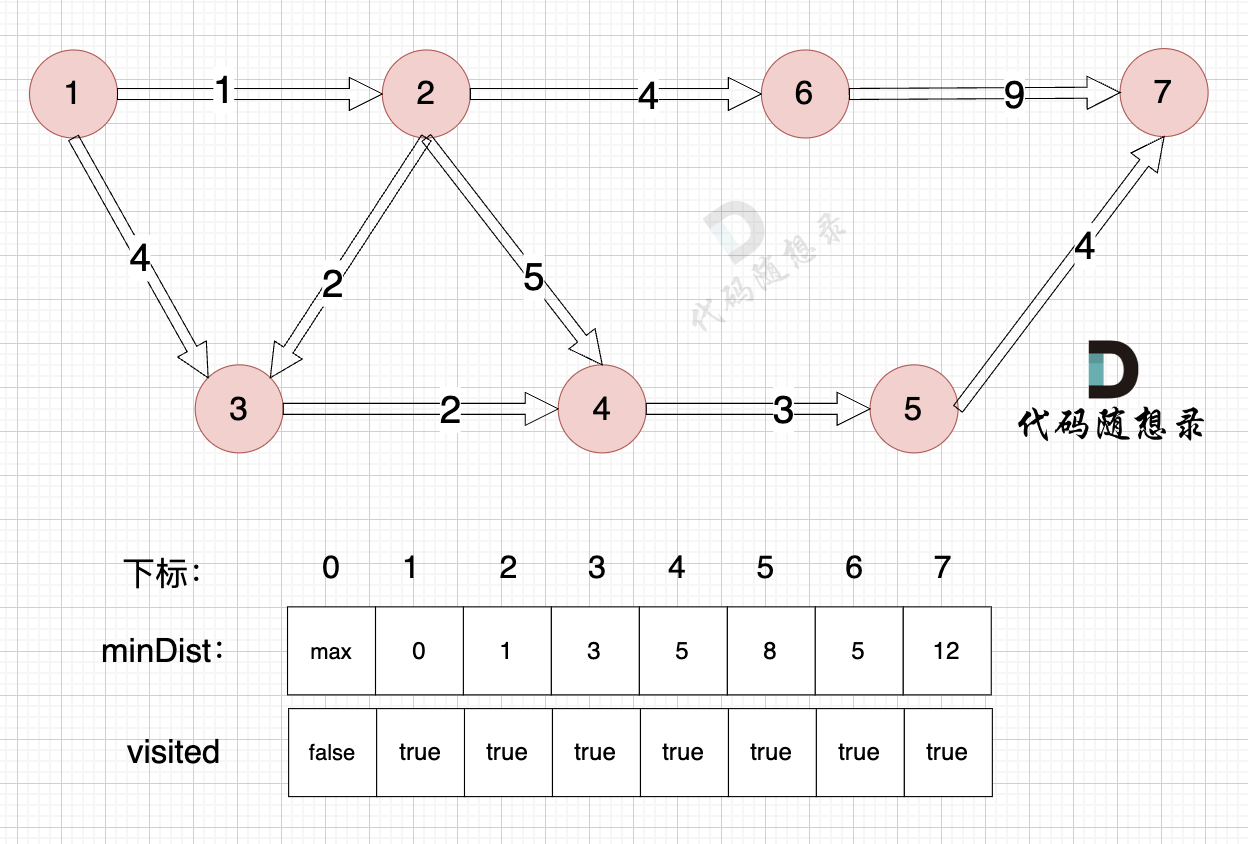
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
距离源点最近且没有被访问过的节点,是节点7(终点),距离源点距离是 12 (minDist[7] = 12)
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
节点7 被标记访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
节点7加入,但节点7到节点7的距离为0,所以 不用更新minDist数组
|
||||
|
||||
--------------------
|
||||
|
||||
最后我们要求起点(节点1) 到终点 (节点7)的距离。
|
||||
|
||||
再来回顾一下minDist数组的含义:记录 每一个节点距离源点的最小距离。
|
||||
|
||||
那么起到(节点1)到终点(节点7)的最短距离就是 minDist[7] ,按上面举例讲解来说,minDist[7] = 12,节点1 到节点7的最短路径为 12。
|
||||
|
||||
路径如图:
|
||||
|
||||
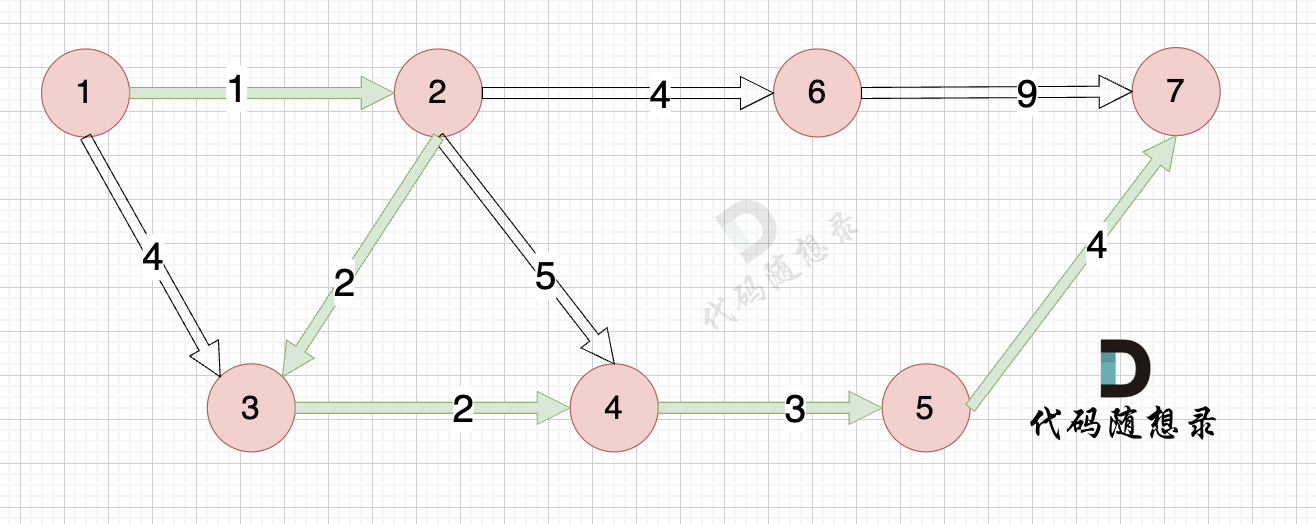
|
||||
|
||||
在上面的讲解中,每一步 我都是按照 dijkstra 三部曲来讲解的,理解了这三部曲,代码也就好懂的。
|
||||
|
||||
### 代码实现
|
||||
|
||||
本题代码如下,里面的 三部曲 我都做了注释,大家按照我上面的讲解 来看如下代码:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2] = val;
|
||||
}
|
||||
|
||||
int start = 1;
|
||||
int end = n;
|
||||
|
||||
// 存储从源点到每个节点的最短距离
|
||||
std::vector<int> minDist(n + 1, INT_MAX);
|
||||
|
||||
// 记录顶点是否被访问过
|
||||
std::vector<bool> visited(n + 1, false);
|
||||
|
||||
minDist[start] = 0; // 起始点到自身的距离为0
|
||||
|
||||
for (int i = 1; i <= n; i++) { // 遍历所有节点
|
||||
|
||||
int minVal = INT_MAX;
|
||||
int cur = 1;
|
||||
|
||||
// 1、选距离源点最近且未访问过的节点
|
||||
for (int v = 1; v <= n; ++v) {
|
||||
if (!visited[v] && minDist[v] < minVal) {
|
||||
minVal = minDist[v];
|
||||
cur = v;
|
||||
}
|
||||
}
|
||||
|
||||
visited[cur] = true; // 2、标记该节点已被访问
|
||||
|
||||
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n^2)
|
||||
* 空间复杂度:O(n^2)
|
||||
|
||||
### debug方法
|
||||
|
||||
写这种题目难免会有各种各样的问题,我们如何发现自己的代码是否有问题呢?
|
||||
|
||||
最好的方式就是打日志,本题的话,就是将 minDist 数组打印出来,就可以很明显发现 哪里出问题了。
|
||||
|
||||
每次选择节点后,minDist数组的变化是否符合预期 ,是否和我上面讲的逻辑是对应的。
|
||||
|
||||
例如本题,如果想debug的话,打印日志可以这样写:
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2] = val;
|
||||
}
|
||||
|
||||
int start = 1;
|
||||
int end = n;
|
||||
|
||||
std::vector<int> minDist(n + 1, INT_MAX);
|
||||
|
||||
std::vector<bool> visited(n + 1, false);
|
||||
|
||||
minDist[start] = 0;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
|
||||
int minVal = INT_MAX;
|
||||
int cur = 1;
|
||||
|
||||
|
||||
for (int v = 1; v <= n; ++v) {
|
||||
if (!visited[v] && minDist[v] < minVal) {
|
||||
minVal = minDist[v];
|
||||
cur = v;
|
||||
}
|
||||
}
|
||||
|
||||
visited[cur] = true;
|
||||
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
}
|
||||
}
|
||||
|
||||
// 打印日志:
|
||||
cout << "select:" << cur << endl;
|
||||
for (int v = 1; v <= n; v++) cout << v << ":" << minDist[v] << " ";
|
||||
cout << endl << endl;;
|
||||
|
||||
}
|
||||
if (minDist[end] == INT_MAX) cout << -1 << endl;
|
||||
else cout << minDist[end] << endl;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
打印后的结果:
|
||||
|
||||
```
|
||||
select:1
|
||||
1:0 2:1 3:4 4:2147483647 5:2147483647 6:2147483647 7:2147483647
|
||||
|
||||
select:2
|
||||
1:0 2:1 3:3 4:6 5:2147483647 6:5 7:2147483647
|
||||
|
||||
select:3
|
||||
1:0 2:1 3:3 4:5 5:2147483647 6:5 7:2147483647
|
||||
|
||||
select:4
|
||||
1:0 2:1 3:3 4:5 5:8 6:5 7:2147483647
|
||||
|
||||
select:6
|
||||
1:0 2:1 3:3 4:5 5:8 6:5 7:14
|
||||
|
||||
select:5
|
||||
1:0 2:1 3:3 4:5 5:8 6:5 7:12
|
||||
|
||||
select:7
|
||||
1:0 2:1 3:3 4:5 5:8 6:5 7:12
|
||||
```
|
||||
|
||||
打印日志可以和上面我讲解的过程进行对比,每一步的结果是完全对应的。
|
||||
|
||||
所以如果大家如果代码有问题,打日志来debug是最好的方法
|
||||
|
||||
### 如何求路径
|
||||
|
||||
如果题目要求把最短路的路径打印出来,应该怎么办呢?
|
||||
|
||||
这里还是有一些“坑”的,本题打印路径和 prim 打印路径是一样的,我在 [prim算法精讲](https://mp.weixin.qq.com/s/yX936hHC6Z10K36Vm1Wl9w) 【拓展】中 已经详细讲解了。
|
||||
|
||||
在这里就不再赘述。
|
||||
|
||||
打印路径只需要添加 几行代码, 打印路径的代码我都加上的日志,如下:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2] = val;
|
||||
}
|
||||
|
||||
int start = 1;
|
||||
int end = n;
|
||||
|
||||
std::vector<int> minDist(n + 1, INT_MAX);
|
||||
|
||||
std::vector<bool> visited(n + 1, false);
|
||||
|
||||
minDist[start] = 0;
|
||||
|
||||
//加上初始化
|
||||
vector<int> parent(n + 1, -1);
|
||||
|
||||
for (int i = 1; i <= n; i++) {
|
||||
|
||||
int minVal = INT_MAX;
|
||||
int cur = 1;
|
||||
|
||||
for (int v = 1; v <= n; ++v) {
|
||||
if (!visited[v] && minDist[v] < minVal) {
|
||||
minVal = minDist[v];
|
||||
cur = v;
|
||||
}
|
||||
}
|
||||
|
||||
visited[cur] = true;
|
||||
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
parent[v] = cur; // 记录边
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// 输出最短情况
|
||||
for (int i = 1; i <= n; i++) {
|
||||
cout << parent[i] << "->" << i << endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
打印结果:
|
||||
|
||||
```
|
||||
-1->1
|
||||
1->2
|
||||
2->3
|
||||
3->4
|
||||
4->5
|
||||
2->6
|
||||
5->7
|
||||
```
|
||||
|
||||
对应如图:
|
||||
|
||||

|
||||
|
||||
### 出现负数
|
||||
|
||||
如果图中边的权值为负数,dijkstra 还合适吗?
|
||||
|
||||
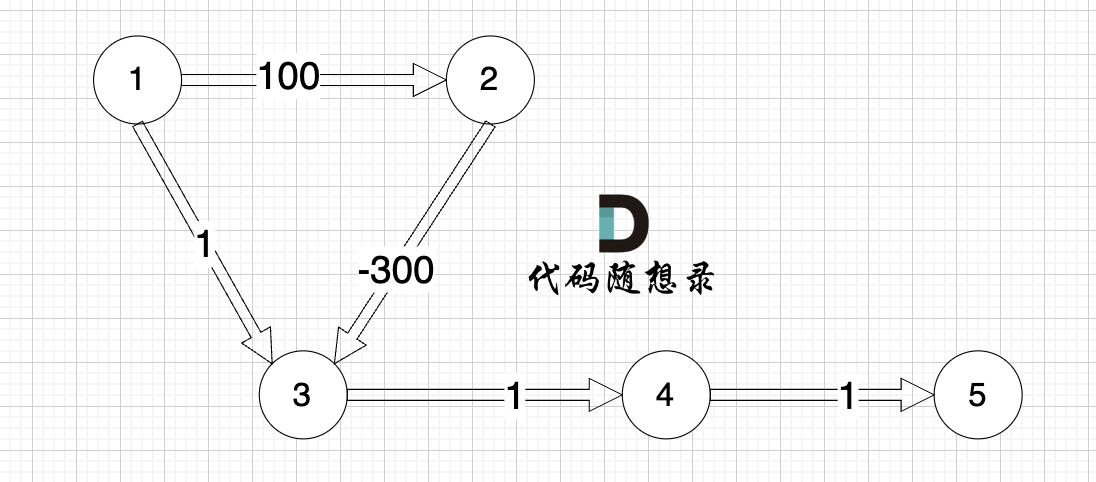
看一下这个图: (有负权值)
|
||||
|
||||
|
||||
|
||||
节点1 到 节点5 的最短路径 应该是 节点1 -> 节点2 -> 节点3 -> 节点4 -> 节点5
|
||||
|
||||
那我们来看dijkstra 求解的路径是什么样的,继续dijkstra 三部曲来模拟 :(dijkstra模拟过程上面已经详细讲过,以下只模拟重要过程,例如如何初始化就省略讲解了)
|
||||
|
||||
-----------
|
||||
|
||||
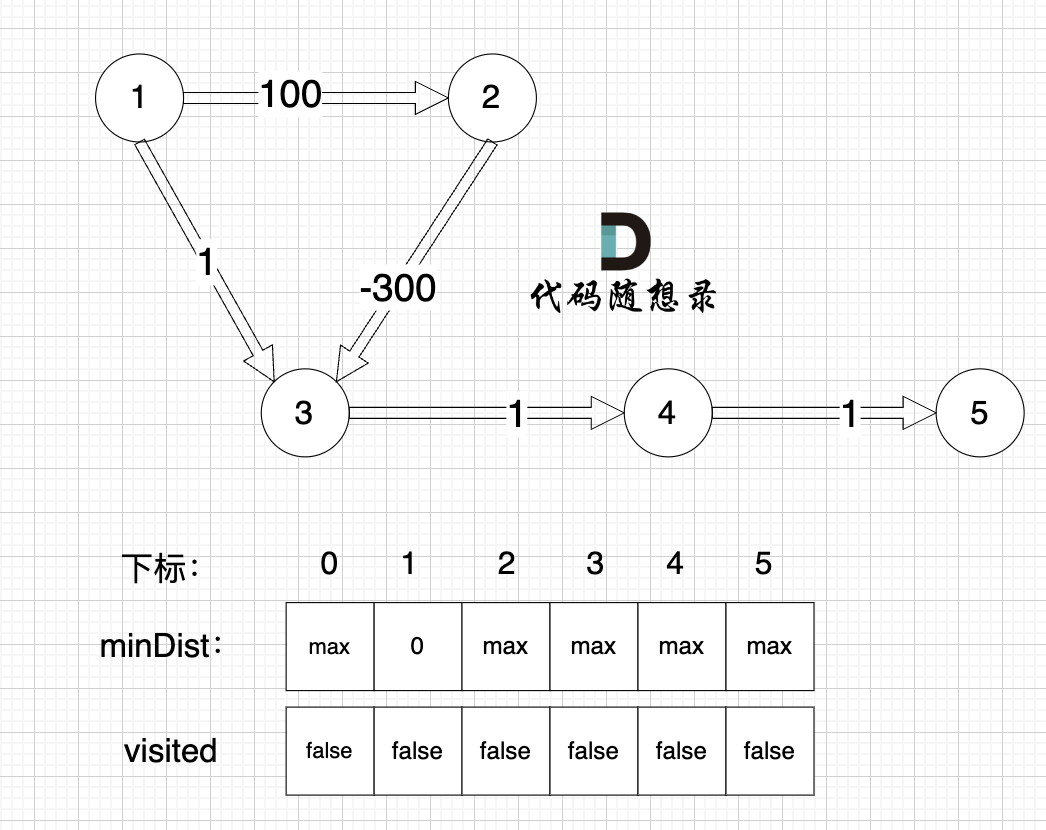
初始化:
|
||||
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
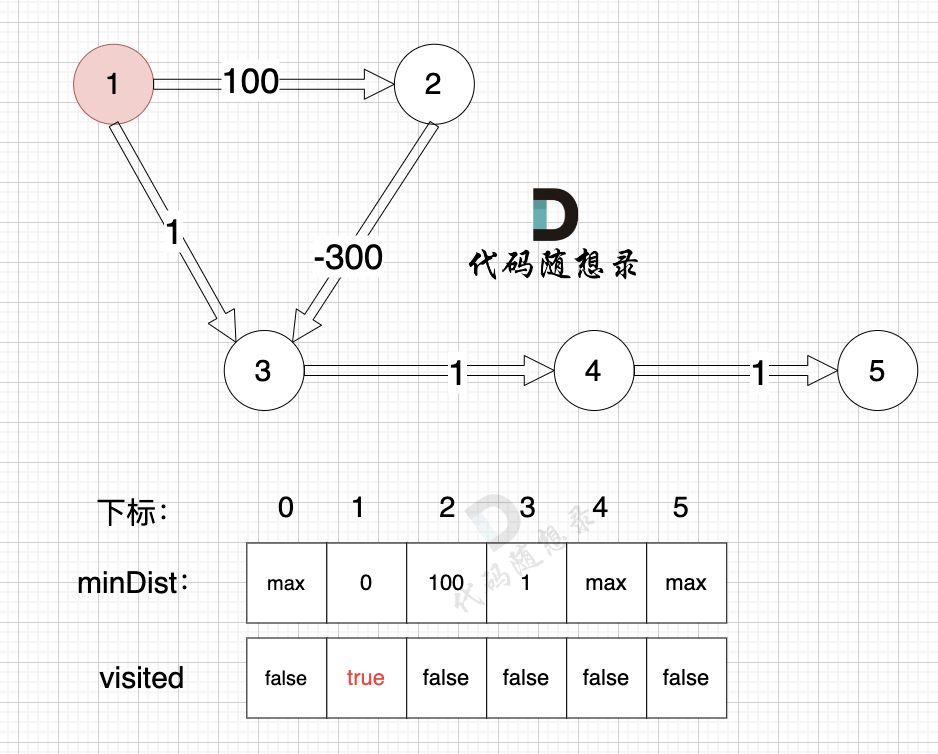
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离源点最近,距离为0,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记源点访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
|
||||
|
||||
* 源点到节点2的最短距离为100,小于原minDist[2]的数值max,更新minDist[2] = 100
|
||||
* 源点到节点3的最短距离为1,小于原minDist[3]的数值max,更新minDist[4] = 1
|
||||
|
||||
-------------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离节点3最近,距离为1,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记节点3访问过
|
||||
|
||||
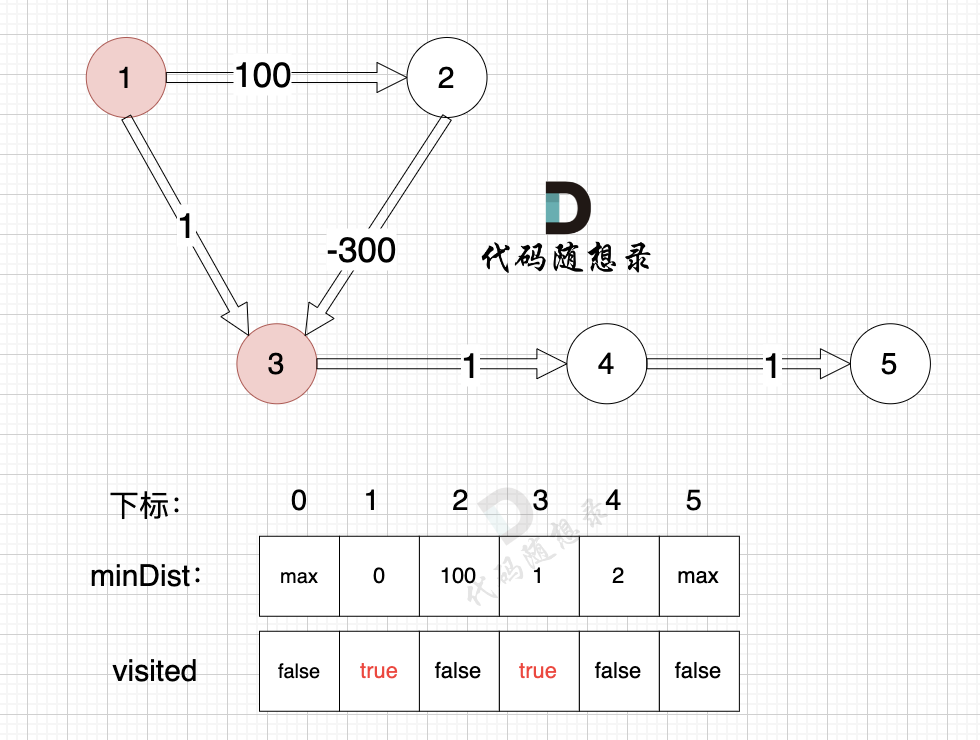
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
由于节点3的加入,那么源点可以有新的路径链接到节点4 所以更新minDist数组:
|
||||
|
||||
* 源点到节点4的最短距离为2,小于原minDist[4]的数值max,更新minDist[4] = 2
|
||||
|
||||
--------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离节点4最近,距离为2,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记节点4访问过
|
||||
|
||||
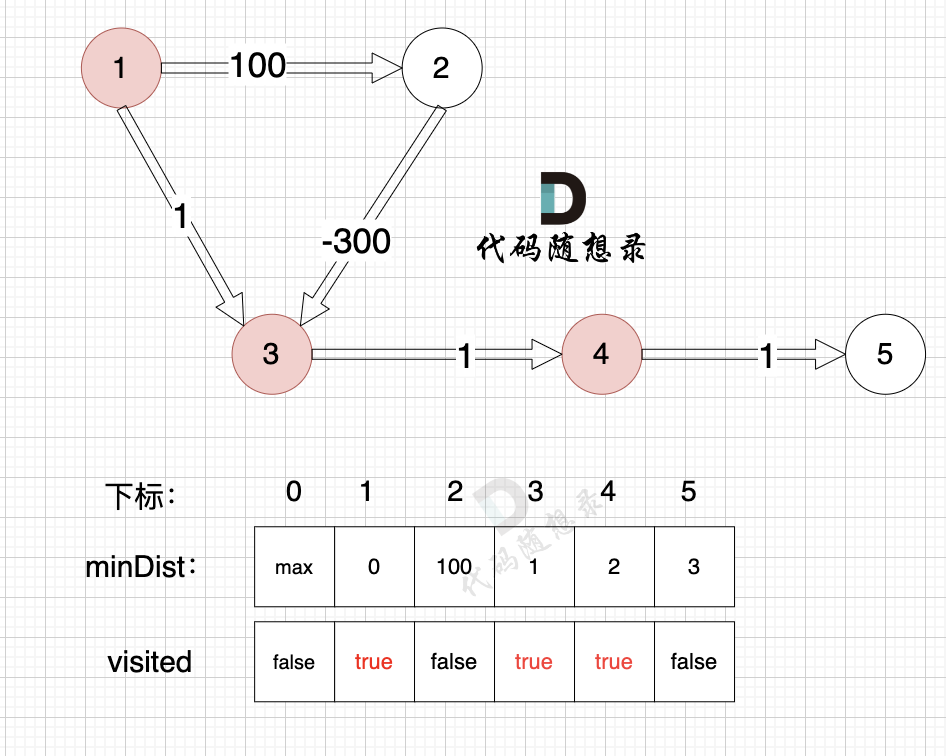
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
由于节点4的加入,那么源点可以有新的路径链接到节点5 所以更新minDist数组:
|
||||
|
||||
* 源点到节点5的最短距离为3,小于原minDist[5]的数值max,更新minDist[5] = 5
|
||||
|
||||
------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离节点5最近,距离为3,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记节点5访问过
|
||||
|
||||
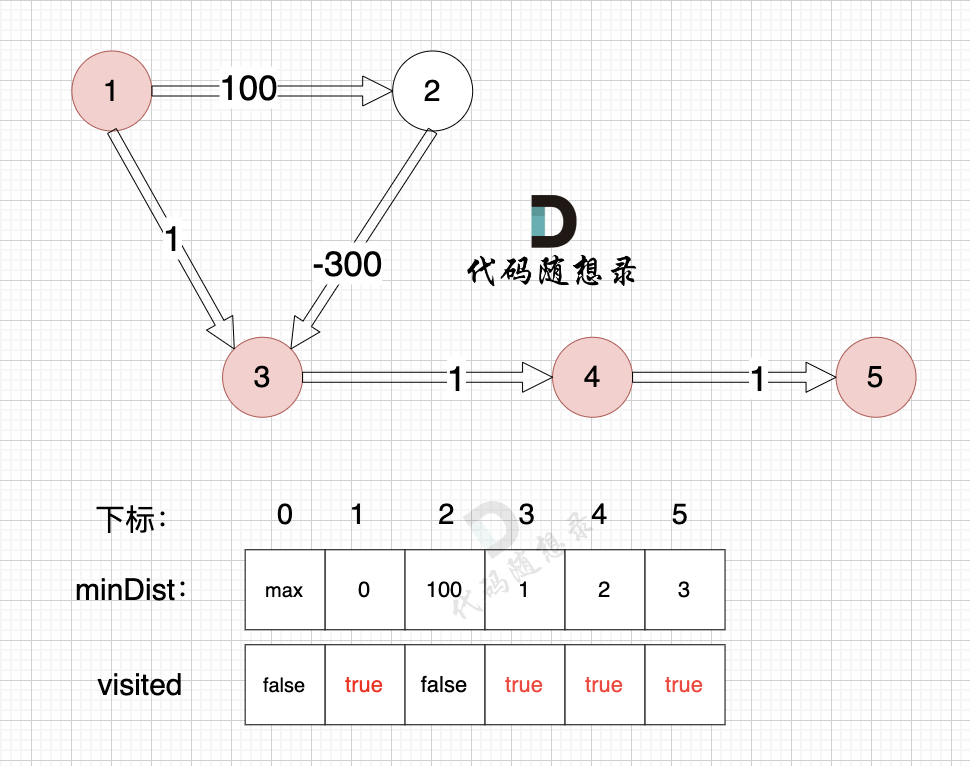
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
|
||||
|
||||
节点5的加入,而节点5 没有链接其他节点, 所以不用更新minDist数组,仅标记节点5被访问过了
|
||||
|
||||
------------
|
||||
|
||||
1、选源点到哪个节点近且该节点未被访问过
|
||||
|
||||
源点距离节点2最近,距离为100,且未被访问。
|
||||
|
||||
2、该最近节点被标记访问过
|
||||
|
||||
标记节点2访问过
|
||||
|
||||
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:
|
||||
|
||||
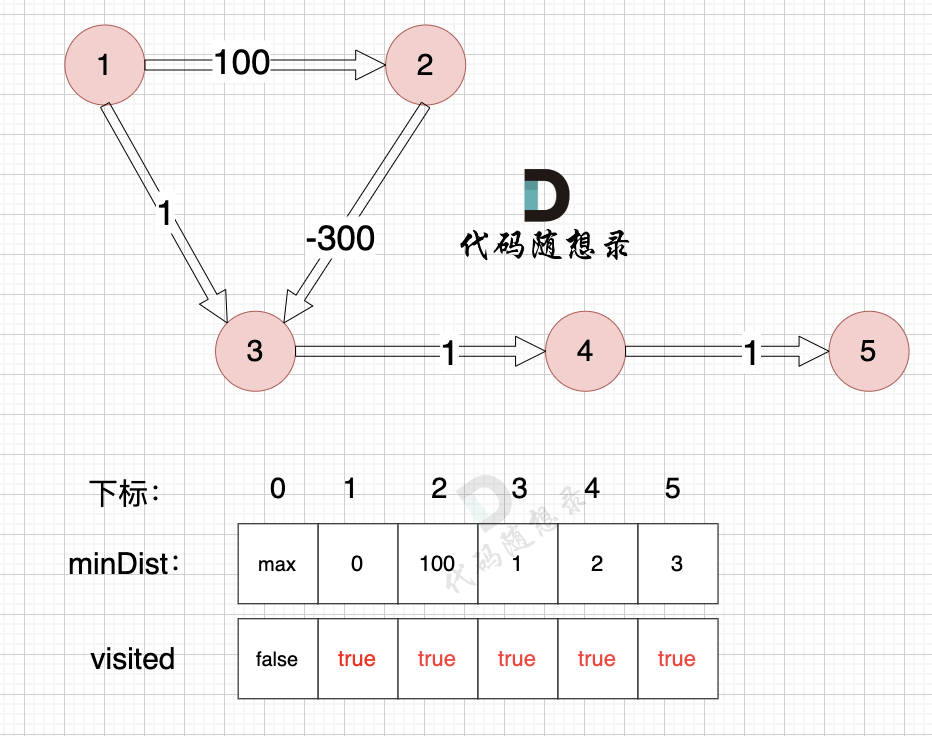
|
||||
|
||||
--------------
|
||||
|
||||
至此dijkstra的模拟过程就结束了,根据最后的minDist数组,我们求 节点1 到 节点5 的最短路径的权值总和为 3,路径: 节点1 -> 节点3 -> 节点4 -> 节点5
|
||||
|
||||
通过以上的过程模拟,我们可以发现 之所以 没有走有负权值的最短路径 是因为 在 访问 节点 2 的时候,节点 3 已经访问过了,就不会再更新了。
|
||||
|
||||
那有录友可能会想: 我可以改代码逻辑啊,访问过的节点,也让它继续访问不就好了?
|
||||
|
||||
那么访问过的节点还能继续访问会不会有死循环的出现呢?控制逻辑不让其死循环?那特殊情况自己能都想清楚吗?(可以试试,实践出真知)
|
||||
|
||||
对于负权值的出现,大家可以针对某一个场景 不断去修改 dijkstra 的代码,**但最终会发现只是 拆了东墙补西墙**,对dijkstra的补充逻辑只能满足某特定场景最短路求解。
|
||||
|
||||
对于求解带有负权值的最短路问题,可以使用 Bellman-Ford 算法 ,我在后序会详细讲解。
|
||||
|
||||
## dijkstra与prim算法的区别
|
||||
|
||||
> 这里再次提示,需要先看我的 [prim算法精讲](https://mp.weixin.qq.com/s/yX936hHC6Z10K36Vm1Wl9w) ,否则可能不知道我下面讲的是什么。
|
||||
|
||||
大家可以发现 dijkstra的代码看上去 怎么和 prim算法这么像呢。
|
||||
|
||||
其实代码大体不差,唯一区别在 三部曲中的 第三步: 更新minDist数组
|
||||
|
||||
因为**prim是求 非访问节点到最小生成树的最小距离,而 dijkstra是求 非访问节点到源点的最小距离**。
|
||||
|
||||
prim 更新 minDist数组的写法:
|
||||
|
||||
|
||||
```CPP
|
||||
for (int j = 1; j <= v; j++) {
|
||||
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
|
||||
minDist[j] = grid[cur][j];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
因为 minDist表示 节点到最小生成树的最小距离,所以 新节点cur的加入,只需要 使用 grid[cur][j] ,grid[cur][j] 就表示 cur 加入生成树后,生成树到 节点j 的距离。
|
||||
|
||||
dijkstra 更新 minDist数组的写法:
|
||||
|
||||
```CPP
|
||||
for (int v = 1; v <= n; v++) {
|
||||
if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {
|
||||
minDist[v] = minDist[cur] + grid[cur][v];
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
因为 minDist表示 节点到源点的最小距离,所以 新节点 cur 的加入,需要使用 源点到cur的距离 (minDist[cur]) + cur 到 节点 v 的距离 (grid[cur][v]),才是 源点到节点v的距离。
|
||||
|
||||
此时大家可能不禁要想 prim算法 可以有负权值吗?
|
||||
|
||||
当然可以!
|
||||
|
||||
录友们可以自己思考思考一下,这是为什么?
|
||||
|
||||
这里我提示一下:prim算法只需要将节点以最小权值和链接在一起,不涉及到单一路径。
|
||||
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
本篇,我们深入讲解的dijkstra算法,详细模拟其工作的流程。
|
||||
|
||||
这里我给出了 **dijkstra 三部曲 来 帮助大家理解 该算法**,不至于 每次写 dijkstra 都是黑盒操作,没有框架没有章法。
|
||||
|
||||
在给出的代码中,我也按照三部曲的逻辑来给大家注释,只要理解这三部曲,即使 过段时间 对 dijkstra 算法有些遗忘,依然可以写出一个框架出来,然后再去调试细节。
|
||||
|
||||
对于图论算法,一般代码都比较长,很难写出代码直接可以提交通过,都需要一个debug的过程,所以 **学习如何debug 非常重要**!
|
||||
|
||||
这也是我为什么 在本文中 单独用来讲解 debug方法。
|
||||
|
||||
本题求的是最短路径和是多少,**同时我们也要掌握 如何把最短路径打印出来**。
|
||||
|
||||
我还写了大篇幅来讲解 负权值的情况, 只有画图带大家一步一步去 看 出现负权值 dijkstra的求解过程,才能帮助大家理解,问题出在哪里。
|
||||
|
||||
如果我直接讲:是**因为访问过的节点 不能再访问,导致错过真正的最短路**,我相信大家都不知道我在说啥。
|
||||
|
||||
最后我还讲解了 dijkstra 和 prim 算法的 相同 与 不同之处, 我在图论的讲解安排中 先讲 prim算法 再讲 dijkstra 是有目的的, **理解这两个算法的相同与不同之处 有助于大家学习的更深入**。
|
||||
|
||||
而不是 学了 dijkstra 就只看 dijkstra, 算法之间 都是有联系的,多去思考 算法之间的相互联系,会帮助大家思考的更深入,掌握的更彻底。
|
||||
|
||||
本篇写了这么长,我也只讲解了 朴素版dijkstra,**关于 堆优化dijkstra,我会在下一篇再来给大家详细讲解**。
|
||||
|
||||
加油
|
||||
|
||||
|
||||
|
||||
400
problems/kamacoder/0053.寻宝-Kruskal.md
Normal file
400
problems/kamacoder/0053.寻宝-Kruskal.md
Normal file
@@ -0,0 +1,400 @@
|
||||
|
||||
# kruskal算法精讲
|
||||
|
||||
[卡码网:53. 寻宝](https://kamacoder.com/problempage.php?pid=1053)
|
||||
|
||||
题目描述:
|
||||
|
||||
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
|
||||
|
||||
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来。
|
||||
|
||||
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
|
||||
|
||||
输入描述:
|
||||
|
||||
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
|
||||
|
||||
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
|
||||
|
||||
输出描述:
|
||||
|
||||
输出联通所有岛屿的最小路径总距离
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
7 11
|
||||
1 2 1
|
||||
1 3 1
|
||||
1 5 2
|
||||
2 6 1
|
||||
2 4 2
|
||||
2 3 2
|
||||
3 4 1
|
||||
4 5 1
|
||||
5 6 2
|
||||
5 7 1
|
||||
6 7 1
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
6
|
||||
|
||||
## 解题思路
|
||||
|
||||
在上一篇 我们讲解了 prim算法求解 最小生成树,本篇我们来讲解另一个算法:Kruskal,同样可以求最小生成树。
|
||||
|
||||
**prim 算法是维护节点的集合,而 Kruskal 是维护边的集合**。
|
||||
|
||||
上来就这么说,大家应该看不太懂,这里是先让大家有这么个印象,带着这个印象在看下文,理解的会更到位一些。
|
||||
|
||||
kruscal的思路:
|
||||
|
||||
* 边的权值排序,因为要优先选最小的边加入到生成树里
|
||||
* 遍历排序后的边
|
||||
* 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
|
||||
* 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
|
||||
|
||||
下面我们画图举例说明kruscal的工作过程。
|
||||
|
||||
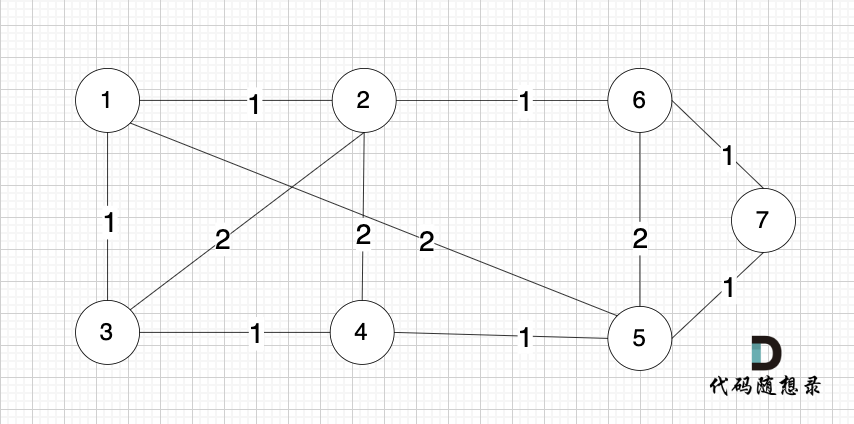
依然以示例中,如下这个图来举例。
|
||||
|
||||
|
||||
|
||||
将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
|
||||
|
||||
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
|
||||
|
||||
> (1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
|
||||
|
||||
**开始从头遍历排序后的边**。
|
||||
|
||||
--------
|
||||
|
||||
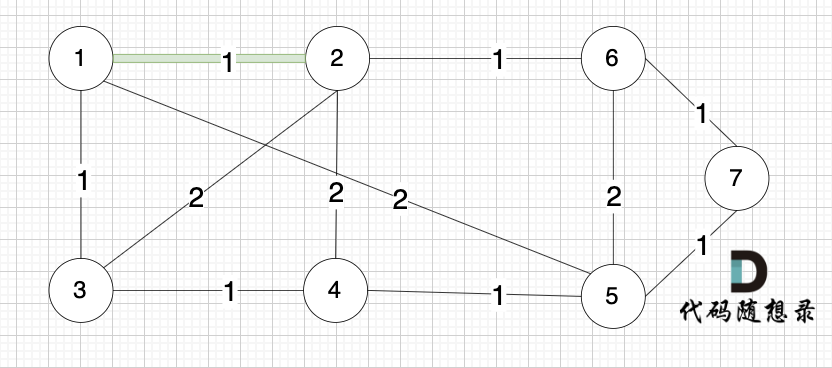
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
|
||||
|
||||
|
||||
|
||||
--------
|
||||
|
||||
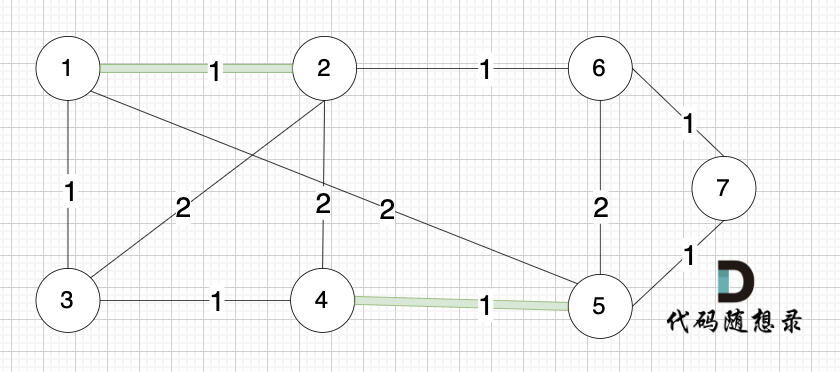
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
**大家判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行**
|
||||
|
||||
------
|
||||
|
||||
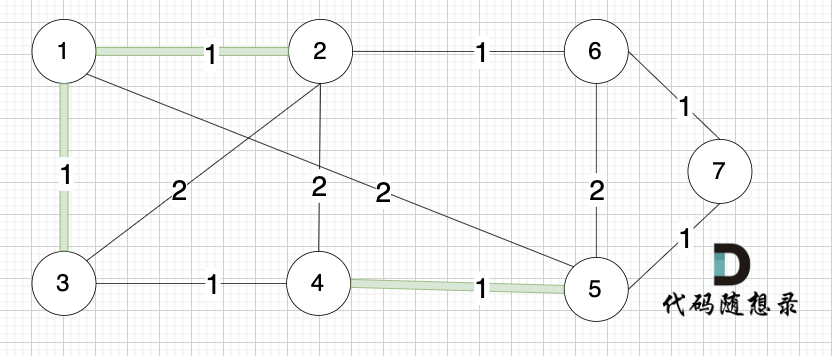
(这里在强调一下,以下选边是按照上面排序好的边的数组来选择的)
|
||||
|
||||
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
---------
|
||||
|
||||
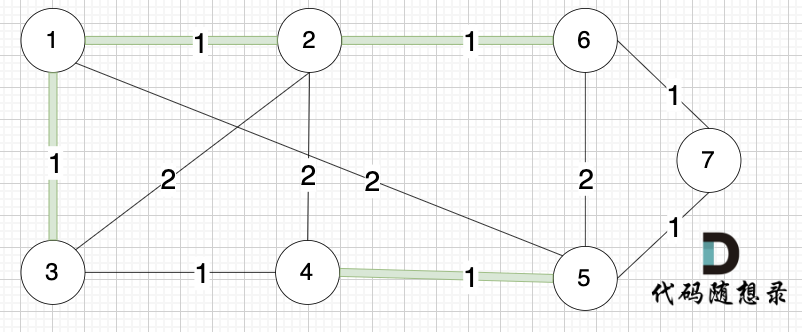
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
--------
|
||||
|
||||
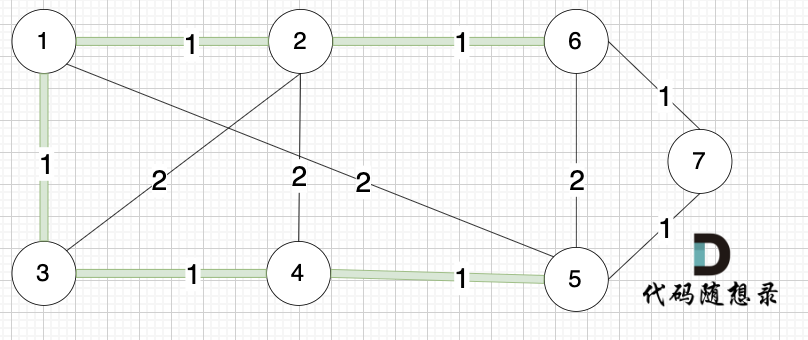
选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
----------
|
||||
|
||||
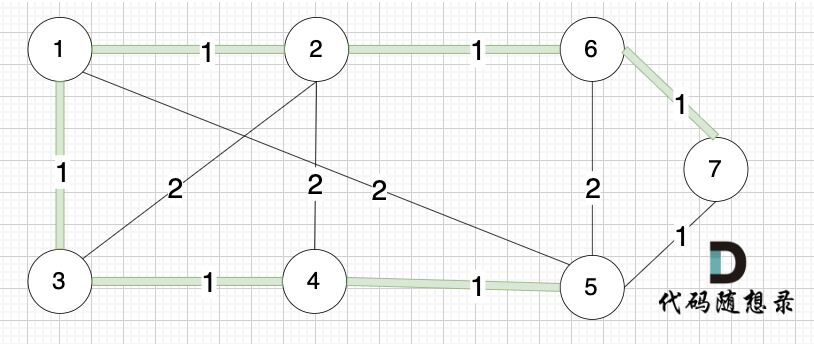
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。
|
||||
|
||||
|
||||
|
||||
-----------
|
||||
|
||||
选边(5,7),节点5 和 节点7 在同一个集合,不做计算。
|
||||
|
||||
选边(1,5),两个节点在同一个集合,不做计算。
|
||||
|
||||
后面遍历 边(3,2),(2,4),(5,6) 同理,都因两个节点已经在同一集合,不做计算。
|
||||
|
||||
|
||||
-------
|
||||
|
||||
此时 我们就已经生成了一个最小生成树,即:
|
||||
|
||||

|
||||
|
||||
在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
|
||||
|
||||
**但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢**?
|
||||
|
||||
这里就涉及到我们之前讲解的[并查集](https://www.programmercarl.com/%E5%9B%BE%E8%AE%BA%E5%B9%B6%E6%9F%A5%E9%9B%86%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html)。
|
||||
|
||||
我们在并查集开篇的时候就讲了,并查集主要就两个功能:
|
||||
|
||||
* 将两个元素添加到一个集合中
|
||||
* 判断两个元素在不在同一个集合
|
||||
|
||||
大家发现这正好符合 Kruskal算法的需求,这也是为什么 **我要先讲并查集,再讲 Kruskal**。
|
||||
|
||||
关于 并查集,我已经在[并查集精讲](https://www.programmercarl.com/%E5%9B%BE%E8%AE%BA%E5%B9%B6%E6%9F%A5%E9%9B%86%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html) 详细讲解过了,所以这里不再赘述,我们直接用。
|
||||
|
||||
本题代码如下,已经详细注释:
|
||||
|
||||
```CPP
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace std;
|
||||
|
||||
// l,r为 边两边的节点,val为边的数值
|
||||
struct Edge {
|
||||
int l, r, val;
|
||||
};
|
||||
|
||||
// 节点数量
|
||||
int n = 10001;
|
||||
// 并查集标记节点关系的数组
|
||||
vector<int> father(n, -1); // 节点编号是从1开始的,n要大一些
|
||||
|
||||
// 并查集初始化
|
||||
void init() {
|
||||
for (int i = 0; i < n; ++i) {
|
||||
father[i] = i;
|
||||
}
|
||||
}
|
||||
|
||||
// 并查集的查找操作
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
|
||||
}
|
||||
|
||||
// 并查集的加入集合
|
||||
void join(int u, int v) {
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
father[v] = u;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
int v, e;
|
||||
int v1, v2, val;
|
||||
vector<Edge> edges;
|
||||
int result_val = 0;
|
||||
cin >> v >> e;
|
||||
while (e--) {
|
||||
cin >> v1 >> v2 >> val;
|
||||
edges.push_back({v1, v2, val});
|
||||
}
|
||||
|
||||
// 执行Kruskal算法
|
||||
// 按边的权值对边进行从小到大排序
|
||||
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
|
||||
return a.val < b.val;
|
||||
});
|
||||
|
||||
// 并查集初始化
|
||||
init();
|
||||
|
||||
// 从头开始遍历边
|
||||
for (Edge edge : edges) {
|
||||
// 并查集,搜出两个节点的祖先
|
||||
int x = find(edge.l);
|
||||
int y = find(edge.r);
|
||||
|
||||
// 如果祖先不同,则不在同一个集合
|
||||
if (x != y) {
|
||||
result_val += edge.val; // 这条边可以作为生成树的边
|
||||
join(x, y); // 两个节点加入到同一个集合
|
||||
}
|
||||
}
|
||||
cout << result_val << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
时间复杂度:nlogn (快排) + logn (并查集) ,所以最后依然是 nlogn 。n为边的数量。
|
||||
|
||||
关于并查集时间复杂度,可以看我在 [并查集理论基础](https://programmercarl.com/%E5%9B%BE%E8%AE%BA%E5%B9%B6%E6%9F%A5%E9%9B%86%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html) 的讲解。
|
||||
|
||||
## 拓展一
|
||||
|
||||
如果题目要求将最小生成树的边输出的话,应该怎么办呢?
|
||||
|
||||
Kruskal 算法 输出边的话,相对prim 要容易很多,因为 Kruskal 本来就是直接操作边,边的结构自然清晰,不用像 prim一样 需要再节点练成线输出边 (因为prim是对节点操作,而 Kruskal是对边操作,这是本质区别)
|
||||
|
||||
本题中,边的结构为:
|
||||
|
||||
```CPP
|
||||
struct Edge {
|
||||
int l, r, val;
|
||||
};
|
||||
```
|
||||
|
||||
那么我们只需要找到 在哪里把生成树的边保存下来就可以了。
|
||||
|
||||
当判断两个节点不在同一个集合的时候,这两个节点的边就加入到最小生成树, 所以添加边的操作在这里:
|
||||
|
||||
```CPP
|
||||
vector<Edge> result; // 存储最小生成树的边
|
||||
// 如果祖先不同,则不在同一个集合
|
||||
if (x != y) {
|
||||
result.push_back(edge); // 记录最小生成树的边
|
||||
result_val += edge.val; // 这条边可以作为生成树的边
|
||||
join(x, y); // 两个节点加入到同一个集合
|
||||
}
|
||||
```
|
||||
|
||||
整体代码如下,为了突出重点,我仅仅将 打印最小生成树的部分代码注释了,大家更容易看到哪些改动。
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace std;
|
||||
|
||||
struct Edge {
|
||||
int l, r, val;
|
||||
};
|
||||
|
||||
|
||||
int n = 10001;
|
||||
|
||||
vector<int> father(n, -1);
|
||||
|
||||
void init() {
|
||||
for (int i = 0; i < n; ++i) {
|
||||
father[i] = i;
|
||||
}
|
||||
}
|
||||
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : father[u] = find(father[u]);
|
||||
}
|
||||
|
||||
void join(int u, int v) {
|
||||
u = find(u);
|
||||
v = find(v);
|
||||
if (u == v) return ;
|
||||
father[v] = u;
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
int v, e;
|
||||
int v1, v2, val;
|
||||
vector<Edge> edges;
|
||||
int result_val = 0;
|
||||
cin >> v >> e;
|
||||
while (e--) {
|
||||
cin >> v1 >> v2 >> val;
|
||||
edges.push_back({v1, v2, val});
|
||||
}
|
||||
|
||||
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
|
||||
return a.val < b.val;
|
||||
});
|
||||
|
||||
vector<Edge> result; // 存储最小生成树的边
|
||||
|
||||
init();
|
||||
|
||||
for (Edge edge : edges) {
|
||||
|
||||
int x = find(edge.l);
|
||||
int y = find(edge.r);
|
||||
|
||||
|
||||
if (x != y) {
|
||||
result.push_back(edge); // 保存最小生成树的边
|
||||
result_val += edge.val;
|
||||
join(x, y);
|
||||
}
|
||||
}
|
||||
|
||||
// 打印最小生成树的边
|
||||
for (Edge edge : result) {
|
||||
cout << edge.l << " - " << edge.r << " : " << edge.val << endl;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
按照题目中的示例,打印边的输出为:
|
||||
|
||||
```
|
||||
1 - 2 : 1
|
||||
1 - 3 : 1
|
||||
2 - 6 : 1
|
||||
3 - 4 : 1
|
||||
4 - 5 : 1
|
||||
5 - 7 : 1
|
||||
```
|
||||
|
||||
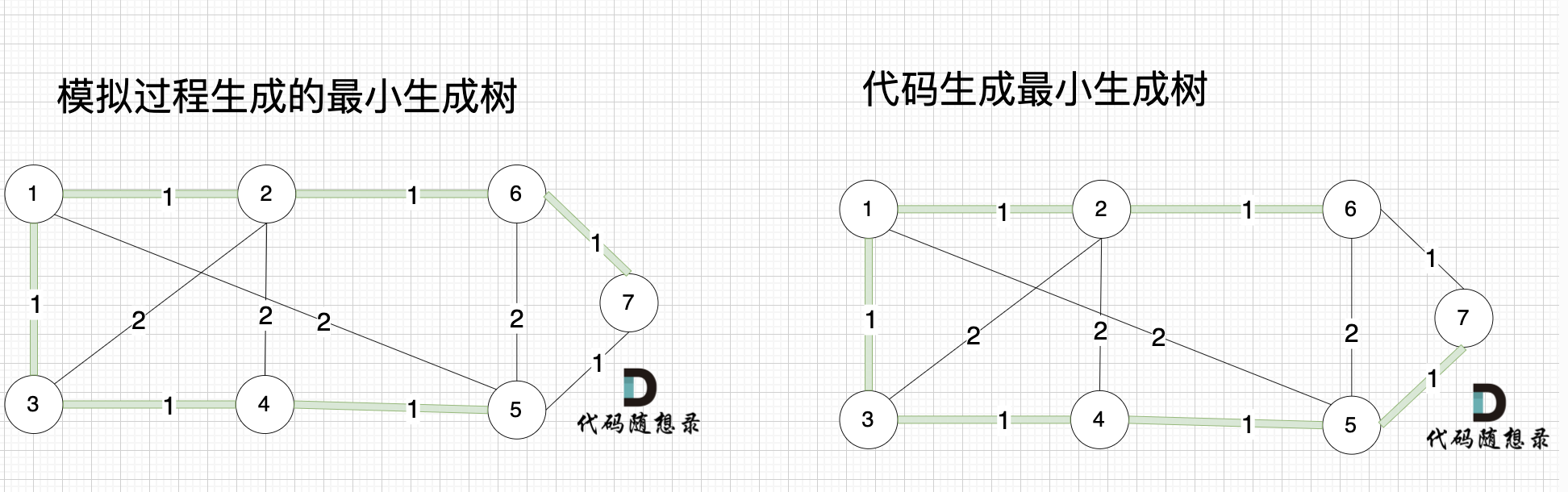
大家可能发现 怎么和我们 模拟画的图不一样,差别在于 代码生成的最小生成树中 节点5 和 节点7相连的。
|
||||
|
||||
|
||||
|
||||
|
||||
其实造成这个差别 是对边排序的时候 权值相同的边先后顺序的问题导致的,无论相同权值边的顺序是什么样的,最后都能得出最小生成树。
|
||||
|
||||
|
||||
## 拓展二
|
||||
|
||||
|
||||
此时我们已经讲完了 Kruskal 和 prim 两个解法来求最小生成树。
|
||||
|
||||
什么情况用哪个算法更合适呢。
|
||||
|
||||
Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 Kruskal 维护的是边的集合。
|
||||
如果 一个图中,节点多,但边相对较少,那么使用Kruskal 更优。
|
||||
|
||||
有录友可能疑惑,一个图里怎么可能节点多,边却少呢?
|
||||
|
||||
节点未必一定要连着边那, 例如 这个图,大家能明显感受到边没有那么多对吧,但节点数量 和 上述我们讲的例子是一样的。
|
||||
|
||||
|
||||
|
||||
为什么边少的话,使用 Kruskal 更优呢?
|
||||
|
||||
因为 Kruskal 是对边进行排序的后 进行操作是否加入到最小生成树。
|
||||
|
||||
边如果少,那么遍历操作的次数就少。
|
||||
|
||||
在节点数量固定的情况下,图中的边越少,Kruskal 需要遍历的边也就越少。
|
||||
|
||||
而 prim 算法是对节点进行操作的,节点数量越少,prim算法效率就越少。
|
||||
|
||||
所以在 稀疏图中,用Kruskal更优。 在稠密图中,用prim算法更优。
|
||||
|
||||
> 边数量较少为稀疏图,接近或等于完全图(所有节点皆相连)为稠密图
|
||||
|
||||
|
||||
Prim 算法 时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
|
||||
|
||||
Kruskal算法 时间复杂度 为 nlogn,其中n 为边的数量,适用稀疏图。
|
||||
|
||||
## 总结
|
||||
|
||||
如果学过了并查集,其实 kruskal 比 prim更好理解一些。
|
||||
|
||||
本篇,我们依然通过模拟 Kruskal 算法的过程,来带大家一步步了解其工作过程。
|
||||
|
||||
在 拓展一 中讲解了 如何输出最小生成树的边。
|
||||
|
||||
在拓展二 中讲解了 prim 和 Kruskal的区别。
|
||||
|
||||
录友们可以细细体会。
|
||||
|
||||
|
||||
516
problems/kamacoder/0053.寻宝-prim.md
Normal file
516
problems/kamacoder/0053.寻宝-prim.md
Normal file
@@ -0,0 +1,516 @@
|
||||
|
||||
# prim算法精讲
|
||||
|
||||
[卡码网:53. 寻宝](https://kamacoder.com/problempage.php?pid=1053)
|
||||
|
||||
题目描述:
|
||||
|
||||
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
|
||||
|
||||
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来。
|
||||
|
||||
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
|
||||
|
||||
输入描述:
|
||||
|
||||
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
|
||||
|
||||
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
|
||||
|
||||
输出描述:
|
||||
|
||||
输出联通所有岛屿的最小路径总距离
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
7 11
|
||||
1 2 1
|
||||
1 3 1
|
||||
1 5 2
|
||||
2 6 1
|
||||
2 4 2
|
||||
2 3 2
|
||||
3 4 1
|
||||
4 5 1
|
||||
5 6 2
|
||||
5 7 1
|
||||
6 7 1
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
6
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
本题是最小生成树的模板题,那么我们来讲一讲最小生成树。
|
||||
|
||||
最小生成树 可以使用 prim算法 也可以使用 kruskal算法计算出来。
|
||||
|
||||
本篇我们先讲解 prim算法。
|
||||
|
||||
最小生成树是所有节点的最小连通子图, 即:以最小的成本(边的权值)将图中所有节点链接到一起。
|
||||
|
||||
图中有n个节点,那么一定可以用 n - 1 条边将所有节点连接到一起。
|
||||
|
||||
那么如何选择 这 n-1 条边 就是 最小生成树算法的任务所在。
|
||||
|
||||
例如本题示例中的无向有权图为:
|
||||
|
||||
|
||||
|
||||
那么在这个图中,如何选取 n-1 条边 使得 图中所有节点连接到一起,并且边的权值和最小呢?
|
||||
|
||||
(图中为n为7,即7个节点,那么只需要 n-1 即 6条边就可以讲所有顶点连接到一起)
|
||||
|
||||
prim算法 是从节点的角度 采用贪心的策略 每次寻找距离 最小生成树最近的节点 并加入到最小生成树中。
|
||||
|
||||
prim算法核心就是三步,我称为**prim三部曲**,大家一定要熟悉这三步,代码相对会好些很多:
|
||||
|
||||
1. 第一步,选距离生成树最近节点
|
||||
2. 第二步,最近节点加入生成树
|
||||
3. 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
现在录友们会对这三步很陌生,不知道这是干啥的,没关系,下面将会画图举例来带大家把这**prim三部曲**理解到位。
|
||||
|
||||
在prim算法中,有一个数组特别重要,这里我起名为:minDist。
|
||||
|
||||
刚刚我有讲过 “每次寻找距离 最小生成树最近的节点 并加入到最小生成树中”,那么如何寻找距离最小生成树最近的节点呢?
|
||||
|
||||
这就用到了 minDist 数组, 它用来作什么呢?
|
||||
|
||||
**minDist数组 用来记录 每一个节点距离最小生成树的最近距离**。 理解这一点非常重要,这也是 prim算法最核心要点所在,很多录友看不懂prim算法的代码,都是因为没有理解透 这个数组的含义。
|
||||
|
||||
接下来,我们来通过一步一步画图,来带大家巩固 **prim三部曲** 以及 minDist数组 的作用。
|
||||
|
||||
(**示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了,避免大家搞混**)
|
||||
|
||||
|
||||
### 1 初始状态
|
||||
|
||||
minDist 数组 里的数值初始化为 最大数,因为本题 节点距离不会超过 10000,所以 初始化最大数为 10001就可以。
|
||||
|
||||
相信这里录友就要问了,为什么这么做?
|
||||
|
||||
现在 还没有最小生成树,默认每个节点距离最小生成树是最大的,这样后面我们在比较的时候,发现更近的距离,才能更新到 minDist 数组上。
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
开始构造最小生成树
|
||||
|
||||
### 2
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那我们选择节点1 (符合遍历数组的习惯,第一个遍历的也是节点1)
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
此时 节点1 已经算最小生成树的节点。
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
接下来,我们要更新所有节点距离最小生成树的距离,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
注意下标0,我们就不管它了,下标 1 与节点 1 对应,这样可以避免大家把节点搞混。
|
||||
|
||||
此时所有非生成树的节点距离 最小生成树(节点1)的距离都已经跟新了 。
|
||||
|
||||
* 节点2 与 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[2]。
|
||||
* 节点3 和 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[3]。
|
||||
* 节点5 和 节点1 的距离为2,比原先的 距离值10001小,所以更新minDist[5]。
|
||||
|
||||
**注意图中我标记了 minDist数组里更新的权值**,是哪两个节点之间的权值,例如 minDist[2] =1 ,这个 1 是 节点1 与 节点2 之间的连线,清楚这一点对最后我们记录 最小生成树的权值总和很重要。
|
||||
|
||||
(我在后面依然会不断重复 prim三部曲,可能基础好的录友会感觉有点啰嗦,但也是让大家感觉这三部曲求解的过程)
|
||||
|
||||
### 3
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
选取一个距离 最小生成树(节点1) 最近的非生成树里的节点,节点2,3,5 距离 最小生成树(节点1) 最近,选节点 2(其实选 节点3或者节点2都可以,距离一样的)加入最小生成树。
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
此时 节点1 和 节点2,已经算最小生成树的节点。
|
||||
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
接下来,我们要更新节点距离最小生成树的距离,如图:
|
||||
|
||||
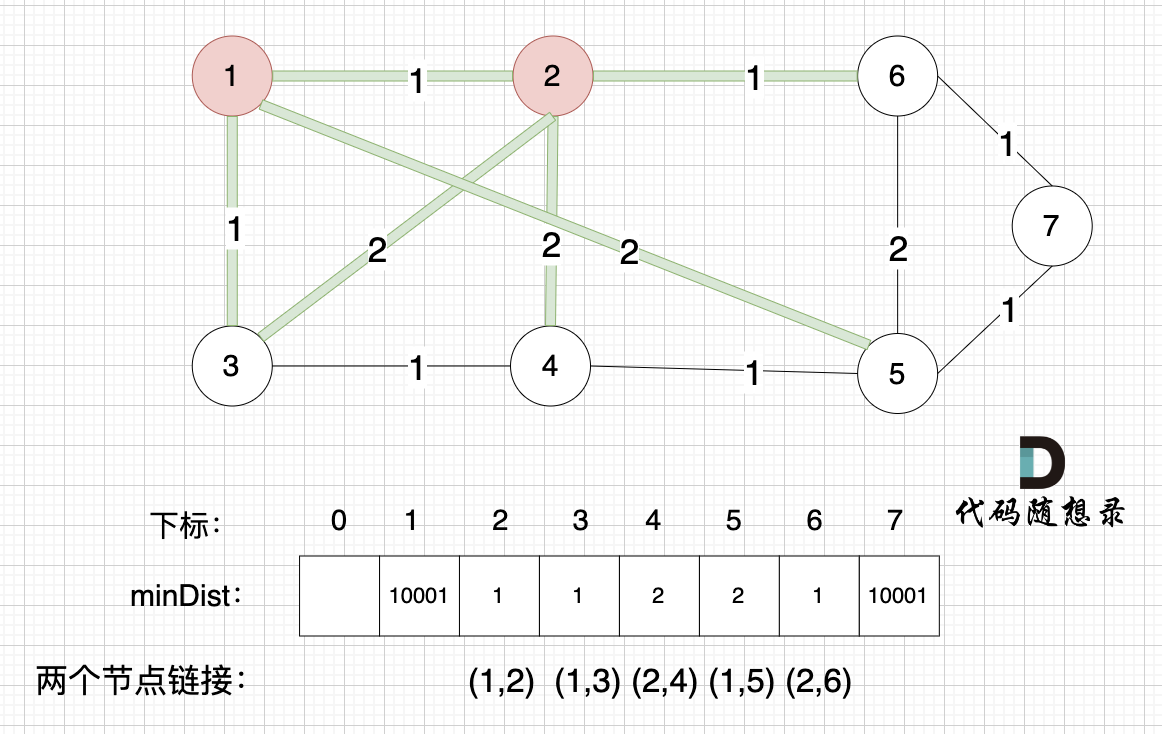
|
||||
|
||||
此时所有非生成树的节点距离 最小生成树(节点1、节点2)的距离都已经跟新了 。
|
||||
|
||||
* 节点3 和 节点2 的距离为2,和原先的距离值1 小,所以不用更新。
|
||||
* 节点4 和 节点2 的距离为2,比原先的距离值10001小,所以更新minDist[4]。
|
||||
* 节点5 和 节点2 的距离为10001(不连接),所以不用更新。
|
||||
* 节点6 和 节点2 的距离为1,比原先的距离值10001小,所以更新minDist[6]。
|
||||
|
||||
### 4
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
选择一个距离 最小生成树(节点1、节点2) 最近的非生成树里的节点,节点3,6 距离 最小生成树(节点1、节点2) 最近,选节点3 (选节点6也可以,距离一样)加入最小生成树。
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
此时 节点1 、节点2 、节点3 算是最小生成树的节点。
|
||||
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||

|
||||
|
||||
所有非生成树的节点距离 最小生成树(节点1、节点2、节点3 )的距离都已经跟新了 。
|
||||
|
||||
* 节点 4 和 节点 3的距离为 1,和原先的距离值 2 小,所以更新minDist[3]为1。
|
||||
|
||||
上面为什么我们只比较 节点4 和 节点3 的距离呢?
|
||||
|
||||
因为节点3加入 最小生成树后,非 生成树节点 只有 节点 4 和 节点3是链接的,所以需要重新更新一下 节点4距离最小生成树的距离,其他节点距离最小生成树的距离 都不变。
|
||||
|
||||
### 5
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
继续选择一个距离 最小生成树(节点1、节点2、节点3) 最近的非生成树里的节点,为了巩固大家对 minDist数组的理解,这里我再啰嗦一遍:
|
||||
|
||||
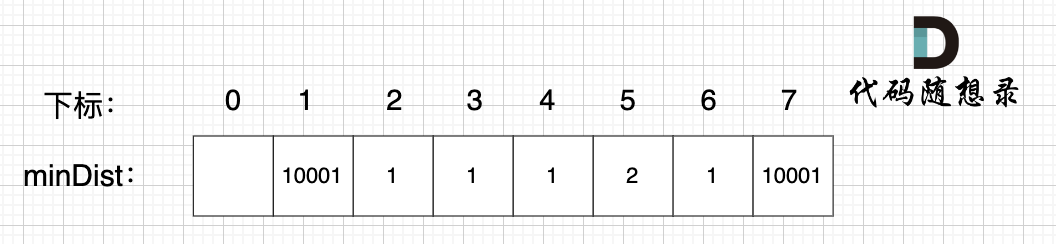
|
||||
|
||||
**minDist数组 是记录了 所有非生成树节点距离生成树的最小距离**,所以 从数组里我们能看出来,非生成树节点 4 和 节点 6 距离 生成树最近。
|
||||
|
||||
|
||||
任选一个加入生成树,我们选 节点4(选节点6也行) 。
|
||||
|
||||
**注意**,我们根据 minDist数组,选取距离 生成树 最近的节点 加入生成树,那么 **minDist数组里记录的其实也是 最小生成树的边的权值**(我在图中把权值对应的是哪两个节点也标记出来了)。
|
||||
|
||||
如果大家不理解,可以跟着我们下面的讲解,看 minDist数组的变化, minDist数组 里记录的权值对应的哪条边。
|
||||
|
||||
理解这一点很重要,因为 最后我们要求 最小生成树里所有边的权值和。
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
此时 节点1、节点2、节点3、节点4 算是 最小生成树的节点。
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
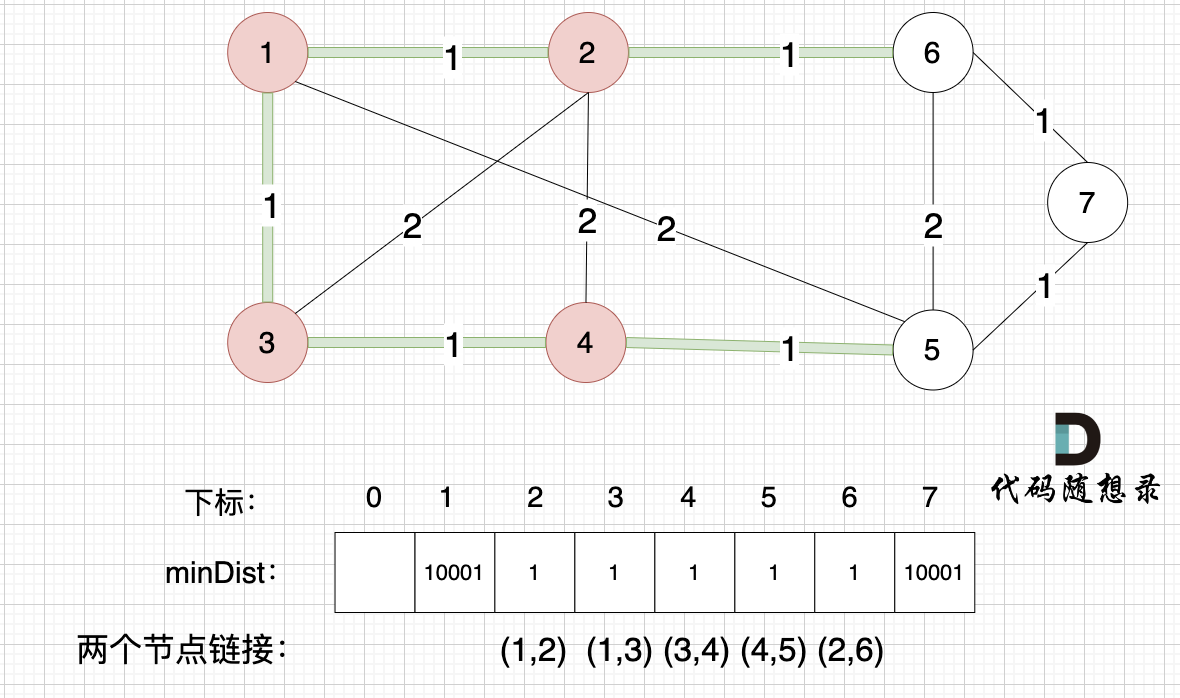
|
||||
|
||||
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 )的距离 。
|
||||
|
||||
* 节点 5 和 节点 4的距离为 1,和原先的距离值 2 小,所以更新minDist[4]为1。
|
||||
|
||||
### 6
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
继续选距离 最小生成树(节点1、节点2、节点3、节点4 )最近的非生成树里的节点,只有 节点 5 和 节点6。
|
||||
|
||||
|
||||
选节点5 (选节点6也可以)加入 生成树。
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
节点1、节点2、节点3、节点4、节点5 算是 最小生成树的节点。
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
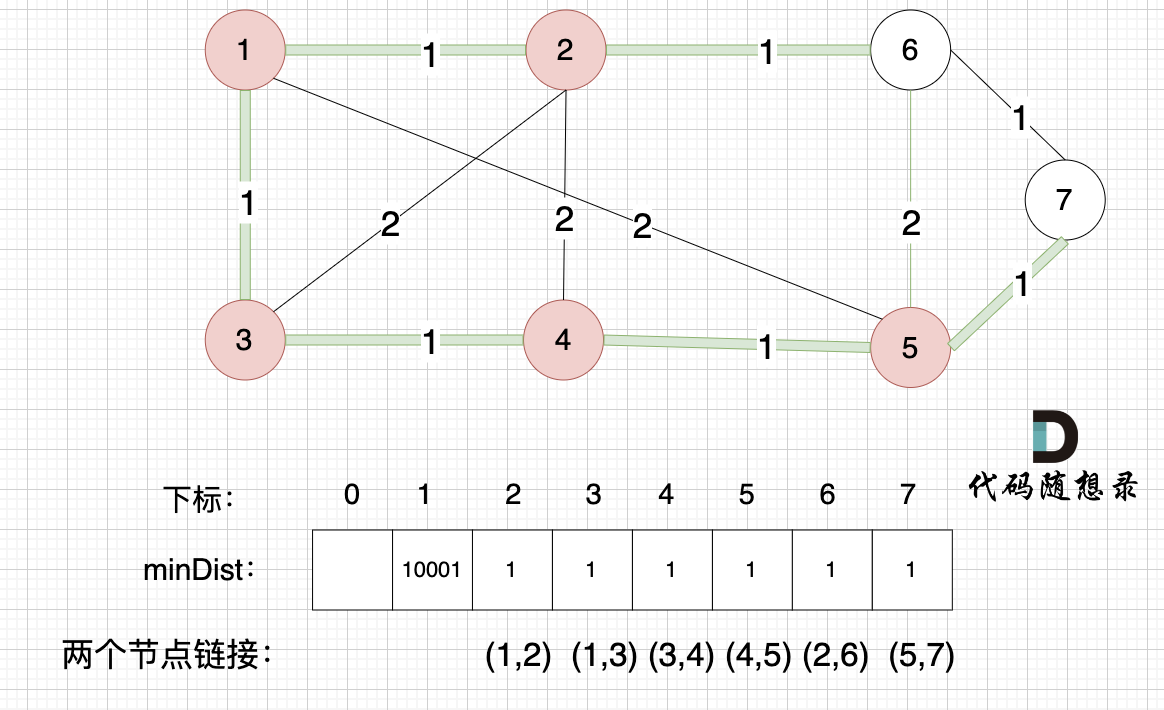
|
||||
|
||||
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)的距离 。
|
||||
|
||||
* 节点 6 和 节点 5 距离为 2,比原先的距离值 1 大,所以不更新
|
||||
* 节点 7 和 节点 5 距离为 1,比原先的距离值 10001小,更新 minDist[7]
|
||||
|
||||
### 7
|
||||
|
||||
1、prim三部曲,第一步:选距离生成树最近节点
|
||||
|
||||
继续选距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)最近的非生成树里的节点,只有 节点 6 和 节点7。
|
||||
|
||||
2、prim三部曲,第二步:最近节点加入生成树
|
||||
|
||||
选节点6 (选节点7也行,距离一样的)加入生成树。
|
||||
|
||||
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
节点1、节点2、节点3、节点4、节点5、节点6 算是 最小生成树的节点 ,接下来更新节点距离最小生成树的距离,如图:
|
||||
|
||||
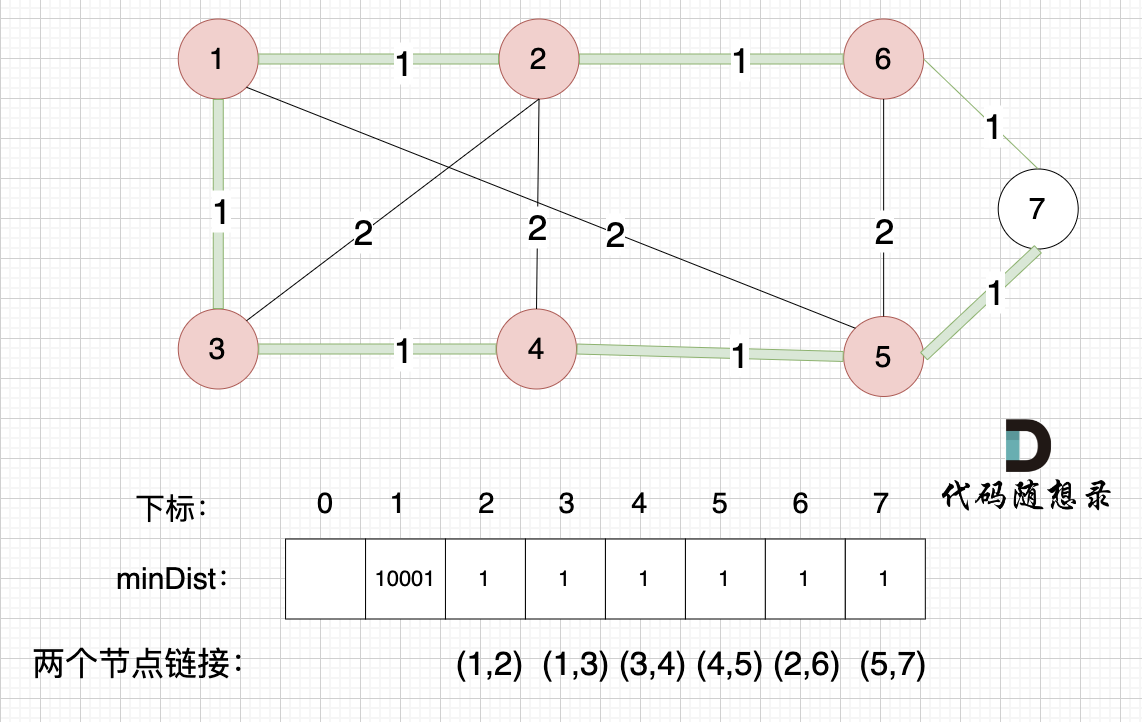
|
||||
|
||||
这里就不在重复描述了,大家类推,最后,节点7加入生成树,如图:
|
||||
|
||||
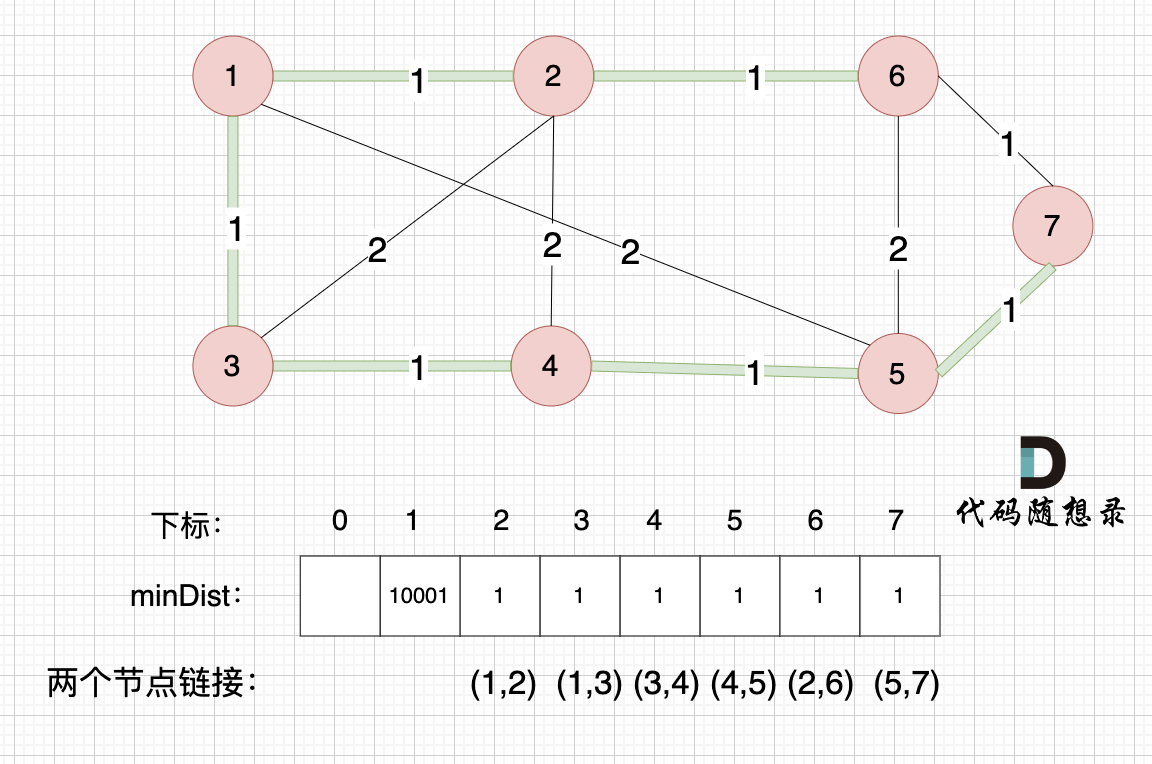
|
||||
|
||||
### 最后
|
||||
|
||||
最后我们就生成了一个 最小生成树, 绿色的边将所有节点链接到一起,并且 保证权值是最小的,因为我们在更新 minDist 数组的时候,都是选距离 最小生成树最近的点 加入到树中。
|
||||
|
||||
讲解上面的模拟过程的时候,我已经强调多次 minDist数组 是记录了 所有非生成树节点距离生成树的最小距离。
|
||||
|
||||
最后,minDist数组 也就是记录的是最小生成树所有边的权值。
|
||||
|
||||
我在图中,特别把 每条边的权值对应的是哪两个节点 标记出来(例如minDist[7] = 1,对应的是节点5 和 节点7之间的边,而不是 节点6 和 节点7),为了就是让大家清楚, minDist里的每一个值 对应的是哪条边。
|
||||
|
||||
那么我们要求最小生成树里边的权值总和 就是 把 最后的 minDist 数组 累加一起。
|
||||
|
||||
以下代码,我对 prim三部曲,做了重点注释,大家根据这三步,就可以 透彻理解prim。
|
||||
|
||||
```CPP
|
||||
#include<iostream>
|
||||
#include<vector>
|
||||
#include <climits>
|
||||
|
||||
using namespace std;
|
||||
int main() {
|
||||
int v, e;
|
||||
int x, y, k;
|
||||
cin >> v >> e;
|
||||
// 填一个默认最大值,题目描述val最大为10000
|
||||
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
|
||||
while (e--) {
|
||||
cin >> x >> y >> k;
|
||||
// 因为是双向图,所以两个方向都要填上
|
||||
grid[x][y] = k;
|
||||
grid[y][x] = k;
|
||||
|
||||
}
|
||||
// 所有节点到最小生成树的最小距离
|
||||
vector<int> minDist(v + 1, 10001);
|
||||
|
||||
// 这个节点是否在树里
|
||||
vector<bool> isInTree(v + 1, false);
|
||||
|
||||
// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起
|
||||
for (int i = 1; i < v; i++) {
|
||||
|
||||
// 1、prim三部曲,第一步:选距离生成树最近节点
|
||||
int cur = -1; // 选中哪个节点 加入最小生成树
|
||||
int minVal = INT_MAX;
|
||||
for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始
|
||||
// 选取最小生成树节点的条件:
|
||||
// (1)不在最小生成树里
|
||||
// (2)距离最小生成树最近的节点
|
||||
if (!isInTree[j] && minDist[j] < minVal) {
|
||||
minVal = minDist[j];
|
||||
cur = j;
|
||||
}
|
||||
}
|
||||
// 2、prim三部曲,第二步:最近节点(cur)加入生成树
|
||||
isInTree[cur] = true;
|
||||
|
||||
// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下
|
||||
// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢
|
||||
for (int j = 1; j <= v; j++) {
|
||||
// 更新的条件:
|
||||
// (1)节点是 非生成树里的节点
|
||||
// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
|
||||
// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了
|
||||
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
|
||||
minDist[j] = grid[cur][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
// 统计结果
|
||||
int result = 0;
|
||||
for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边
|
||||
result += minDist[i];
|
||||
}
|
||||
cout << result << endl;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
时间复杂度为 O(n^2),其中 n 为节点数量。
|
||||
|
||||
## 拓展
|
||||
|
||||
上面讲解的是记录了最小生成树 所有边的权值,如果让打印出来 最小生成树的每条边呢? 或者说 要把这个最小生成树画出来呢?
|
||||
|
||||
|
||||
此时我们就需要把 最小生成树里每一条边记录下来。
|
||||
|
||||
此时有两个问题:
|
||||
|
||||
* 1、用什么结构来记录
|
||||
* 2、如何记录
|
||||
|
||||
如果记录边,其实就是记录两个节点就可以,两个节点连成一条边。
|
||||
|
||||
如何记录两个节点呢?
|
||||
|
||||
我们使用一维数组就可以记录。 parent[节点编号] = 节点编号, 这样就把一条边记录下来了。(当然如果节点编号非常大,可以考虑使用map)
|
||||
|
||||
使用一维数组记录是有向边,不过我们这里不需要记录方向,所以只关注两条边是连接的就行。
|
||||
|
||||
parent数组初始化代码:
|
||||
|
||||
```CPP
|
||||
vector<int> parent(v + 1, -1);
|
||||
```
|
||||
|
||||
接下来就是第二个问题,如何记录?
|
||||
|
||||
我们再来回顾一下 prim三部曲,
|
||||
|
||||
1. 第一步,选距离生成树最近节点
|
||||
2. 第二步,最近节点加入生成树
|
||||
3. 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
大家先思考一下,我们是在第几步,可以记录 最小生成树的边呢?
|
||||
|
||||
在本面上半篇 我们讲解过:“我们根据 minDist数组,选组距离 生成树 最近的节点 加入生成树,那么 **minDist数组里记录的其实也是 最小生成树的边的权值**。”
|
||||
|
||||
既然 minDist数组 记录了 最小生成树的边,是不是就是在更新 minDist数组 的时候,去更新parent数组来记录一下对应的边呢。
|
||||
|
||||
|
||||
所以 在 prim三部曲中的第三步,更新 parent数组,代码如下:
|
||||
|
||||
```CPP
|
||||
for (int j = 1; j <= v; j++) {
|
||||
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
|
||||
minDist[j] = grid[cur][j];
|
||||
parent[j] = cur; // 记录最小生成树的边 (注意数组指向的顺序很重要)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
代码中注释中,我强调了 数组指向的顺序很重要。 因为不少录友在这里会写成这样: `parent[cur] = j` 。
|
||||
|
||||
这里估计大家会疑惑了,parent[节点编号A] = 节点编号B, 就表示A 和 B 相连,我们这里就不用在意方向,代码中 为什么 只能 `parent[j] = cur` 而不能 `parent[cur] = j` 这么写呢?
|
||||
|
||||
如果写成 `parent[cur] = j`,在 for 循环中,有多个 j 满足要求, 那么 parent[cur] 就会被反复覆盖,因为 cur 是一个固定值。
|
||||
|
||||
举个例子,cur = 1, 在 for循环中,可能 就 j = 2, j = 3,j =4 都符合条件,那么本来应该记录 节点1 与 节点 2、节点3、节点4相连的。
|
||||
|
||||
如果 `parent[cur] = j` 这么写,最后更新的逻辑是 parent[1] = 2, parent[1] = 3, parent[1] = 4, 最后只能记录 节点1 与节点 4 相连,其他相连情况都被覆盖了。
|
||||
|
||||
如果这么写 `parent[j] = cur`, 那就是 parent[2] = 1, parent[3] = 1, parent[4] = 1 ,这样 才能完整表示出 节点1 与 其他节点都是链接的,才没有被覆盖。
|
||||
|
||||
主要问题也是我们使用了一维数组来记录。
|
||||
|
||||
如果是二维数组,来记录两个点链接,例如 parent[节点编号A][节点编号B] = 1 ,parent[节点编号B][节点编号A] = 1,来表示 节点A 与 节点B 相连,那就没有上面说的这个注意事项了,当然这么做的话,就是多开辟的内存空间。
|
||||
|
||||
以下是输出最小生成树边的代码,不算最后输出, 就额外添加了两行代码,我都注释标记了:
|
||||
|
||||
```CPP
|
||||
#include<iostream>
|
||||
#include<vector>
|
||||
#include <climits>
|
||||
|
||||
using namespace std;
|
||||
int main() {
|
||||
int v, e;
|
||||
int x, y, k;
|
||||
cin >> v >> e;
|
||||
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
|
||||
while (e--) {
|
||||
cin >> x >> y >> k;
|
||||
grid[x][y] = k;
|
||||
grid[y][x] = k;
|
||||
}
|
||||
|
||||
vector<int> minDist(v + 1, 10001);
|
||||
vector<bool> isInTree(v + 1, false);
|
||||
|
||||
//加上初始化
|
||||
vector<int> parent(v + 1, -1);
|
||||
|
||||
for (int i = 1; i < v; i++) {
|
||||
int cur = -1;
|
||||
int minVal = INT_MAX;
|
||||
for (int j = 1; j <= v; j++) {
|
||||
if (!isInTree[j] && minDist[j] < minVal) {
|
||||
minVal = minDist[j];
|
||||
cur = j;
|
||||
}
|
||||
}
|
||||
|
||||
isInTree[cur] = true;
|
||||
for (int j = 1; j <= v; j++) {
|
||||
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
|
||||
minDist[j] = grid[cur][j];
|
||||
|
||||
parent[j] = cur; // 记录边
|
||||
}
|
||||
}
|
||||
}
|
||||
// 输出 最小生成树边的链接情况
|
||||
for (int i = 1; i <= v; i++) {
|
||||
cout << i << "->" << parent[i] << endl;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
按照本题示例,代码输入如下:
|
||||
|
||||
```
|
||||
1->-1
|
||||
2->1
|
||||
3->1
|
||||
4->3
|
||||
5->4
|
||||
6->2
|
||||
7->5
|
||||
```
|
||||
|
||||
注意,这里是无向图,我在输出上添加了箭头仅仅是为了方便大家看出是边的意思。
|
||||
|
||||
大家可以和我们本题最后生成的最小生成树的图 去对比一下 边的链接情况:
|
||||
|
||||
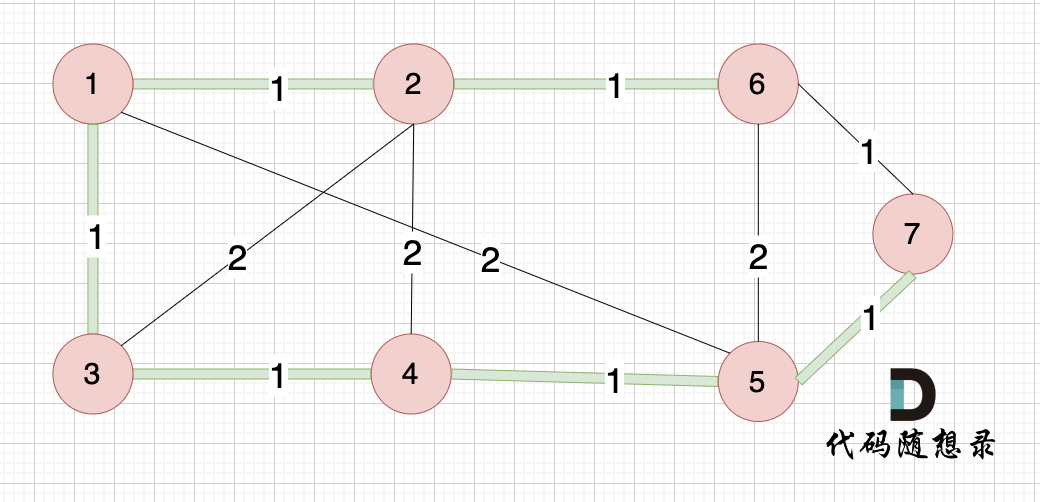
|
||||
|
||||
绿色的边 是最小生成树,和我们的 输出完全一致。
|
||||
|
||||
## 总结
|
||||
|
||||
此时我就把prim算法讲解完毕了,我们再来回顾一下。
|
||||
|
||||
关于 prim算法,我自创了三部曲,来帮助大家理解:
|
||||
|
||||
1. 第一步,选距离生成树最近节点
|
||||
2. 第二步,最近节点加入生成树
|
||||
3. 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
|
||||
|
||||
大家只要理解这三部曲, prim算法 至少是可以写出一个框架出来,然后在慢慢补充细节,这样不至于 自己在写prim的时候 两眼一抹黑 完全凭感觉去写。
|
||||
这也为什么很多录友感觉 prim算法比较难,而且每次学会来,隔一段时间 又不会写了,主要是 没有一个纲领。
|
||||
|
||||
理解这三部曲之后,更重要的 就是理解 minDist数组。
|
||||
|
||||
**minDist数组 是prim算法的灵魂,它帮助 prim算法完成最重要的一步,就是如何找到 距离最小生成树最近的点**。
|
||||
|
||||
再来帮大家回顾 minDist数组 的含义:记录 每一个节点距离最小生成树的最近距离。
|
||||
|
||||
理解 minDist数组 ,至少大家看prim算法的代码不会懵。
|
||||
|
||||
也正是 因为 minDist数组 的作用,我们根据 minDist数组,选取距离 生成树 最近的节点 加入生成树,那么 **minDist数组里记录的其实也是 最小生成树的边的权值**。
|
||||
|
||||
所以我们求 最小生成树的权值和 就是 计算后的 minDist数组 数值总和。
|
||||
|
||||
最后我们拓展了如何求职 最小生成树 的每一条边,其实 添加的代码很简单,主要是理解 为什么使用 parent数组 来记录边 以及 在哪里 更新parent数组。
|
||||
|
||||
同时,因为使用一维数组,数组的下标和数组 如何赋值很重要,不要搞反,导师结果被覆盖。
|
||||
|
||||
好了,以上为总结,录友们学习愉快。
|
||||
|
||||
|
||||
|
||||
|
||||
384
problems/kamacoder/0054.替换数字.md
Normal file
384
problems/kamacoder/0054.替换数字.md
Normal file
@@ -0,0 +1,384 @@
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/xunlianying.html" target="_blank">
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
# 替换数字
|
||||
|
||||
[卡码网题目链接](https://kamacoder.com/problempage.php?pid=1064)
|
||||
|
||||
给定一个字符串 s,它包含小写字母和数字字符,请编写一个函数,将字符串中的字母字符保持不变,而将每个数字字符替换为number。
|
||||
|
||||
例如,对于输入字符串 "a1b2c3",函数应该将其转换为 "anumberbnumbercnumber"。
|
||||
|
||||
对于输入字符串 "a5b",函数应该将其转换为 "anumberb"
|
||||
|
||||
输入:一个字符串 s,s 仅包含小写字母和数字字符。
|
||||
|
||||
输出:打印一个新的字符串,其中每个数字字符都被替换为了number
|
||||
|
||||
样例输入:a1b2c3
|
||||
|
||||
样例输出:anumberbnumbercnumber
|
||||
|
||||
数据范围:1 <= s.length < 10000。
|
||||
|
||||
## 思路
|
||||
|
||||
如果想把这道题目做到极致,就不要只用额外的辅助空间了! (不过使用Java刷题的录友,一定要使用辅助空间,因为Java里的string不能修改)
|
||||
|
||||
首先扩充数组到每个数字字符替换成 "number" 之后的大小。
|
||||
|
||||
例如 字符串 "a5b" 的长度为3,那么 将 数字字符变成字符串 "number" 之后的字符串为 "anumberb" 长度为 8。
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
然后从后向前替换数字字符,也就是双指针法,过程如下:i指向新长度的末尾,j指向旧长度的末尾。
|
||||
|
||||
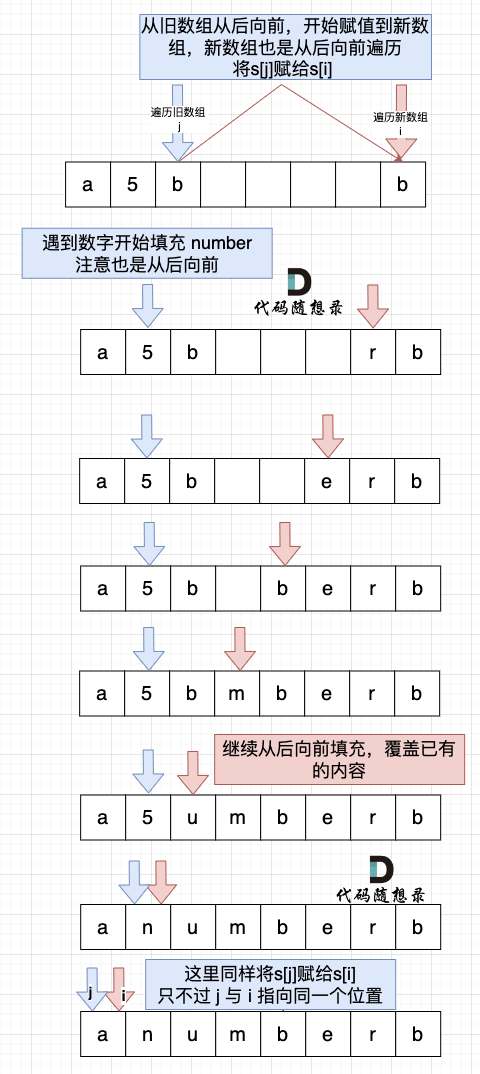
|
||||
|
||||
有同学问了,为什么要从后向前填充,从前向后填充不行么?
|
||||
|
||||
从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素整体向后移动。
|
||||
|
||||
**其实很多数组填充类的问题,其做法都是先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
|
||||
|
||||
这么做有两个好处:
|
||||
|
||||
1. 不用申请新数组。
|
||||
2. 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
using namespace std;
|
||||
int main() {
|
||||
string s;
|
||||
while (cin >> s) {
|
||||
int sOldIndex = s.size() - 1;
|
||||
int count = 0; // 统计数字的个数
|
||||
for (int i = 0; i < s.size(); i++) {
|
||||
if (s[i] >= '0' && s[i] <= '9') {
|
||||
count++;
|
||||
}
|
||||
}
|
||||
// 扩充字符串s的大小,也就是将每个数字替换成"number"之后的大小
|
||||
s.resize(s.size() + count * 5);
|
||||
int sNewIndex = s.size() - 1;
|
||||
// 从后往前将数字替换为"number"
|
||||
while (sOldIndex >= 0) {
|
||||
if (s[sOldIndex] >= '0' && s[sOldIndex] <= '9') {
|
||||
s[sNewIndex--] = 'r';
|
||||
s[sNewIndex--] = 'e';
|
||||
s[sNewIndex--] = 'b';
|
||||
s[sNewIndex--] = 'm';
|
||||
s[sNewIndex--] = 'u';
|
||||
s[sNewIndex--] = 'n';
|
||||
} else {
|
||||
s[sNewIndex--] = s[sOldIndex];
|
||||
}
|
||||
sOldIndex--;
|
||||
}
|
||||
cout << s << endl;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
此时算上本题,我们已经做了七道双指针相关的题目了分别是:
|
||||
|
||||
* [27.移除元素](https://programmercarl.com/0027.移除元素.html)
|
||||
* [15.三数之和](https://programmercarl.com/0015.三数之和.html)
|
||||
* [18.四数之和](https://programmercarl.com/0018.四数之和.html)
|
||||
* [206.翻转链表](https://programmercarl.com/0206.翻转链表.html)
|
||||
* [142.环形链表II](https://programmercarl.com/0142.环形链表II.html)
|
||||
* [344.反转字符串](https://programmercarl.com/0344.反转字符串.html)
|
||||
|
||||
## 拓展
|
||||
|
||||
这里也给大家拓展一下字符串和数组有什么差别,
|
||||
|
||||
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,接下来我来说一说C/C++中的字符串。
|
||||
|
||||
在C语言中,把一个字符串存入一个数组时,也把结束符 '\0'存入数组,并以此作为该字符串是否结束的标志。
|
||||
|
||||
例如这段代码:
|
||||
|
||||
```
|
||||
char a[5] = "asd";
|
||||
for (int i = 0; a[i] != '\0'; i++) {
|
||||
}
|
||||
```
|
||||
|
||||
在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用'\0'来判断是否结束。
|
||||
|
||||
例如这段代码:
|
||||
|
||||
```
|
||||
string a = "asd";
|
||||
for (int i = 0; i < a.size(); i++) {
|
||||
}
|
||||
```
|
||||
|
||||
那么vector< char > 和 string 又有什么区别呢?
|
||||
|
||||
其实在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
|
||||
|
||||
所以想处理字符串,我们还是会定义一个string类型。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### C:
|
||||
|
||||
### Java:
|
||||
解法一
|
||||
```java
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
|
||||
public static String replaceNumber(String s) {
|
||||
int count = 0; // 统计数字的个数
|
||||
int sOldSize = s.length();
|
||||
for (int i = 0; i < s.length(); i++) {
|
||||
if(Character.isDigit(s.charAt(i))){
|
||||
count++;
|
||||
}
|
||||
}
|
||||
// 扩充字符串s的大小,也就是每个空格替换成"number"之后的大小
|
||||
char[] newS = new char[s.length() + count * 5];
|
||||
int sNewSize = newS.length;
|
||||
// 将旧字符串的内容填入新数组
|
||||
System.arraycopy(s.toCharArray(), 0, newS, 0, sOldSize);
|
||||
// 从后先前将空格替换为"number"
|
||||
for (int i = sNewSize - 1, j = sOldSize - 1; j < i; j--, i--) {
|
||||
if (!Character.isDigit(newS[j])) {
|
||||
newS[i] = newS[j];
|
||||
} else {
|
||||
newS[i] = 'r';
|
||||
newS[i - 1] = 'e';
|
||||
newS[i - 2] = 'b';
|
||||
newS[i - 3] = 'm';
|
||||
newS[i - 4] = 'u';
|
||||
newS[i - 5] = 'n';
|
||||
i -= 5;
|
||||
}
|
||||
}
|
||||
return new String(newS);
|
||||
};
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
String s = scanner.next();
|
||||
System.out.println(replaceNumber(s));
|
||||
scanner.close();
|
||||
}
|
||||
}
|
||||
```
|
||||
解法二
|
||||
```java
|
||||
// 为了还原题目本意,先把原数组复制到扩展长度后的新数组,然后不再使用原数组、原地对新数组进行操作。
|
||||
import java.util.*;
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Scanner sc = new Scanner(System.in);
|
||||
String s = sc.next();
|
||||
int len = s.length();
|
||||
for (int i = 0; i < s.length(); i++) {
|
||||
if (s.charAt(i) >= 0 && s.charAt(i) <= '9') {
|
||||
len += 5;
|
||||
}
|
||||
}
|
||||
|
||||
char[] ret = new char[len];
|
||||
for (int i = 0; i < s.length(); i++) {
|
||||
ret[i] = s.charAt(i);
|
||||
}
|
||||
for (int i = s.length() - 1, j = len - 1; i >= 0; i--) {
|
||||
if ('0' <= ret[i] && ret[i] <= '9') {
|
||||
ret[j--] = 'r';
|
||||
ret[j--] = 'e';
|
||||
ret[j--] = 'b';
|
||||
ret[j--] = 'm';
|
||||
ret[j--] = 'u';
|
||||
ret[j--] = 'n';
|
||||
} else {
|
||||
ret[j--] = ret[i];
|
||||
}
|
||||
}
|
||||
System.out.println(ret);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Go:
|
||||
````go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main(){
|
||||
var strByte []byte
|
||||
|
||||
fmt.Scanln(&strByte)
|
||||
|
||||
for i := 0; i < len(strByte); i++{
|
||||
if strByte[i] <= '9' && strByte[i] >= '0' {
|
||||
inserElement := []byte{'n','u','m','b','e','r'}
|
||||
strByte = append(strByte[:i], append(inserElement, strByte[i+1:]...)...)
|
||||
i = i + len(inserElement) -1
|
||||
}
|
||||
}
|
||||
|
||||
fmt.Printf(string(strByte))
|
||||
}
|
||||
````
|
||||
Go使用双指针解法
|
||||
````go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func replaceNumber(strByte []byte) string {
|
||||
// 查看有多少字符
|
||||
numCount, oldSize := 0, len(strByte)
|
||||
for i := 0; i < len(strByte); i++ {
|
||||
if (strByte[i] <= '9') && (strByte[i] >= '0') {
|
||||
numCount ++
|
||||
}
|
||||
}
|
||||
// 增加长度
|
||||
for i := 0; i < numCount; i++ {
|
||||
strByte = append(strByte, []byte(" ")...)
|
||||
}
|
||||
tmpBytes := []byte("number")
|
||||
// 双指针从后遍历
|
||||
leftP, rightP := oldSize-1, len(strByte)-1
|
||||
for leftP < rightP {
|
||||
rightShift := 1
|
||||
// 如果是数字则加入number
|
||||
if (strByte[leftP] <= '9') && (strByte[leftP] >= '0') {
|
||||
for i, tmpByte := range tmpBytes {
|
||||
strByte[rightP-len(tmpBytes)+i+1] = tmpByte
|
||||
}
|
||||
rightShift = len(tmpBytes)
|
||||
} else {
|
||||
strByte[rightP] = strByte[leftP]
|
||||
}
|
||||
// 更新指针
|
||||
rightP -= rightShift
|
||||
leftP -= 1
|
||||
}
|
||||
return string(strByte)
|
||||
}
|
||||
|
||||
func main(){
|
||||
var strByte []byte
|
||||
fmt.Scanln(&strByte)
|
||||
|
||||
newString := replaceNumber(strByte)
|
||||
|
||||
fmt.Println(newString)
|
||||
}
|
||||
````
|
||||
|
||||
|
||||
|
||||
### python:
|
||||
```Python
|
||||
class Solution:
|
||||
def change(self, s):
|
||||
lst = list(s) # Python里面的string也是不可改的,所以也是需要额外空间的。空间复杂度:O(n)。
|
||||
for i in range(len(lst)):
|
||||
if lst[i].isdigit():
|
||||
lst[i] = "number"
|
||||
return ''.join(lst)
|
||||
```
|
||||
### JavaScript:
|
||||
```js
|
||||
const readline = require("readline");
|
||||
|
||||
const rl = readline.createInterface({
|
||||
input: process.stdin,
|
||||
output: process.stdout
|
||||
})
|
||||
|
||||
function main() {
|
||||
const num0 = "0".charCodeAt();
|
||||
const num9 = "9".charCodeAt();
|
||||
const a = "a".charCodeAt();
|
||||
const z = "z".charCodeAt();
|
||||
function isAZ(str) {
|
||||
return str >= a && str <= z;
|
||||
}
|
||||
function isNumber(str) {
|
||||
return str >= num0 && str <= num9;
|
||||
}
|
||||
rl.on("line", (input) => {
|
||||
let n = 0;
|
||||
for (let i = 0; i < input.length; i++) {
|
||||
const val = input[i].charCodeAt();
|
||||
if (isNumber(val)) {
|
||||
n+= 6;
|
||||
}
|
||||
if (isAZ(val)) {
|
||||
n++;
|
||||
}
|
||||
}
|
||||
const ans = new Array(n).fill(0);
|
||||
let index = input.length - 1;
|
||||
for (let i = n - 1; i >= 0; i--) {
|
||||
const val = input[index].charCodeAt();
|
||||
if (isAZ(val)) {
|
||||
ans[i] = input[index];
|
||||
}
|
||||
if (isNumber(val)) {
|
||||
ans[i] = "r";
|
||||
ans[i - 1] = "e";
|
||||
ans[i - 2] = "b";
|
||||
ans[i - 3] = "m";
|
||||
ans[i - 4] = "u";
|
||||
ans[i - 5] = "n";
|
||||
i -= 5;
|
||||
}
|
||||
index--;
|
||||
}
|
||||
console.log(ans.join(""));
|
||||
})
|
||||
}
|
||||
|
||||
main();
|
||||
```
|
||||
|
||||
### TypeScript:
|
||||
|
||||
|
||||
### Swift:
|
||||
|
||||
|
||||
### Scala:
|
||||
|
||||
|
||||
### PHP:
|
||||
|
||||
|
||||
### Rust:
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
280
problems/kamacoder/0055.右旋字符串.md
Normal file
280
problems/kamacoder/0055.右旋字符串.md
Normal file
@@ -0,0 +1,280 @@
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/xunlianying.html" target="_blank">
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
|
||||
# 右旋字符串
|
||||
|
||||
[卡码网题目链接](https://kamacoder.com/problempage.php?pid=1065)
|
||||
|
||||
字符串的右旋转操作是把字符串尾部的若干个字符转移到字符串的前面。给定一个字符串 s 和一个正整数 k,请编写一个函数,将字符串中的后面 k 个字符移到字符串的前面,实现字符串的右旋转操作。
|
||||
|
||||
例如,对于输入字符串 "abcdefg" 和整数 2,函数应该将其转换为 "fgabcde"。
|
||||
|
||||
输入:输入共包含两行,第一行为一个正整数 k,代表右旋转的位数。第二行为字符串 s,代表需要旋转的字符串。
|
||||
|
||||
输出:输出共一行,为进行了右旋转操作后的字符串。
|
||||
|
||||
样例输入:
|
||||
|
||||
```
|
||||
2
|
||||
abcdefg
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
fgabcde
|
||||
```
|
||||
|
||||
数据范围:1 <= k < 10000, 1 <= s.length < 10000;
|
||||
|
||||
|
||||
## 思路
|
||||
|
||||
为了让本题更有意义,提升一下本题难度:**不能申请额外空间,只能在本串上操作**。 (Java不能在字符串上修改,所以使用java一定要开辟新空间)
|
||||
|
||||
不能使用额外空间的话,模拟在本串操作要实现右旋转字符串的功能还是有点困难的。
|
||||
|
||||
那么我们可以想一下上一题目[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中讲过,使用整体反转+局部反转就可以实现反转单词顺序的目的。
|
||||
|
||||
|
||||
本题中,我们需要将字符串右移n位,字符串相当于分成了两个部分,如果n为2,符串相当于分成了两个部分,如图: (length为字符串长度)
|
||||
|
||||
|
||||
|
||||
|
||||
右移n位, 就是将第二段放在前面,第一段放在后面,先不考虑里面字符的顺序,是不是整体倒叙不就行了。如图:
|
||||
|
||||
|
||||
|
||||
此时第一段和第二段的顺序是我们想要的,但里面的字符位置被我们倒叙,那么此时我们在把 第一段和第二段里面的字符再倒叙一把,这样字符顺序不就正确了。 如果:
|
||||
|
||||
|
||||
|
||||
其实,思路就是 通过 整体倒叙,把两段子串顺序颠倒,两个段子串里的的字符在倒叙一把,**负负得正**,这样就不影响子串里面字符的顺序了。
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```CPP
|
||||
// 版本一
|
||||
#include<iostream>
|
||||
#include<algorithm>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n;
|
||||
string s;
|
||||
cin >> n;
|
||||
cin >> s;
|
||||
int len = s.size(); //获取长度
|
||||
|
||||
reverse(s.begin(), s.end()); // 整体反转
|
||||
reverse(s.begin(), s.begin() + n); // 先反转前一段,长度n
|
||||
reverse(s.begin() + n, s.end()); // 再反转后一段
|
||||
|
||||
cout << s << endl;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
那么整体反正的操作放在下面,先局部反转行不行?
|
||||
|
||||
可以的,不过,要记得 控制好 局部反转的长度,如果先局部反转,那么先反转的子串长度就是 len - n,如图:
|
||||
|
||||
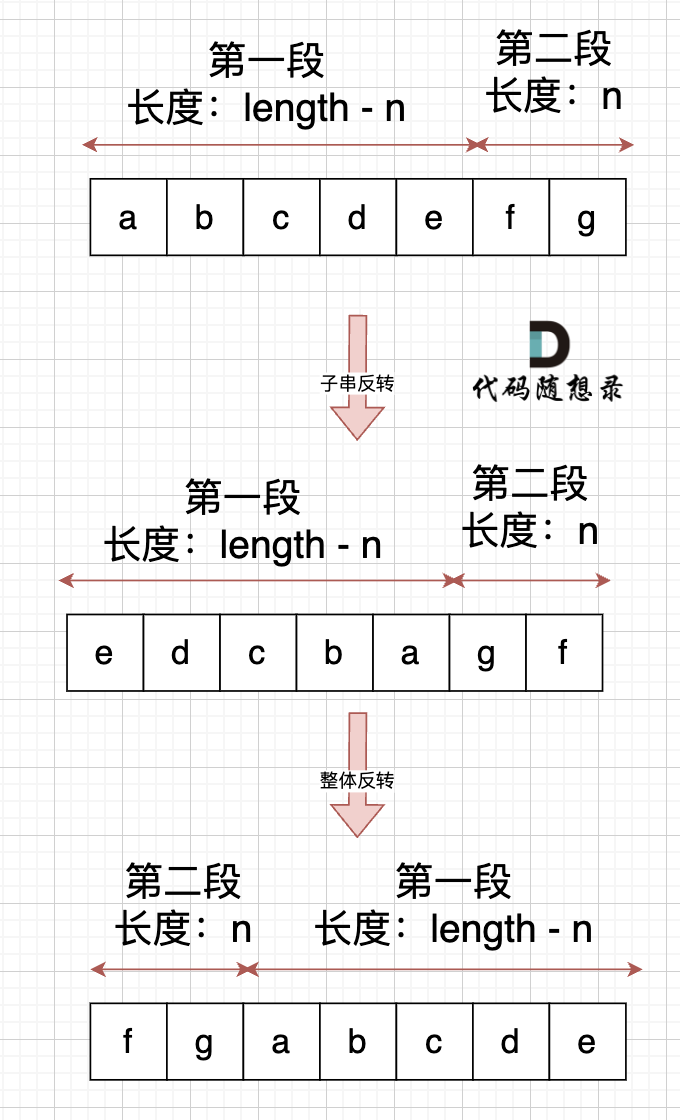
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
// 版本二
|
||||
#include<iostream>
|
||||
#include<algorithm>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n;
|
||||
string s;
|
||||
cin >> n;
|
||||
cin >> s;
|
||||
int len = s.size(); //获取长度
|
||||
reverse(s.begin(), s.begin() + len - n); // 先反转前一段,长度len-n ,注意这里是和版本一的区别
|
||||
reverse(s.begin() + len - n, s.end()); // 再反转后一段
|
||||
reverse(s.begin(), s.end()); // 整体反转
|
||||
cout << s << endl;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 拓展
|
||||
|
||||
大家在做剑指offer的时候,会发现 剑指offer的题目是左反转,那么左反转和右反转 有什么区别呢?
|
||||
|
||||
其实思路是一样一样的,就是反转的区间不同而已。如果本题是左旋转n,那么实现代码如下:
|
||||
|
||||
```CPP
|
||||
#include<iostream>
|
||||
#include<algorithm>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n;
|
||||
string s;
|
||||
cin >> n;
|
||||
cin >> s;
|
||||
int len = s.size(); //获取长度
|
||||
reverse(s.begin(), s.begin() + n); // 反转第一段长度为n
|
||||
reverse(s.begin() + n, s.end()); // 反转第二段长度为len-n
|
||||
reverse(s.begin(), s.end()); // 整体反转
|
||||
cout << s << endl;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
大家可以感受一下 这份代码和 版本二的区别, 其实就是反转的区间不同而已。
|
||||
|
||||
那么左旋转的话,可以不可以先整体反转,例如想版本一的那样呢?
|
||||
|
||||
当然可以。
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Java:
|
||||
```Java
|
||||
// 版本一
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Scanner in = new Scanner(System.in);
|
||||
int n = Integer.parseInt(in.nextLine());
|
||||
String s = in.nextLine();
|
||||
|
||||
int len = s.length(); //获取字符串长度
|
||||
char[] chars = s.toCharArray();
|
||||
reverseString(chars, 0, len - 1); //反转整个字符串
|
||||
reverseString(chars, 0, n - 1); //反转前一段字符串,此时的字符串首尾尾是0,n - 1
|
||||
reverseString(chars, n, len - 1); //反转后一段字符串,此时的字符串首尾尾是n,len - 1
|
||||
|
||||
System.out.println(chars);
|
||||
|
||||
}
|
||||
|
||||
public static void reverseString(char[] ch, int start, int end) {
|
||||
//异或法反转字符串,参照题目 344.反转字符串的解释
|
||||
while (start < end) {
|
||||
ch[start] ^= ch[end];
|
||||
ch[end] ^= ch[start];
|
||||
ch[start] ^= ch[end];
|
||||
start++;
|
||||
end--;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
// 版本二
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Scanner in = new Scanner(System.in);
|
||||
int n = Integer.parseInt(in.nextLine());
|
||||
String s = in.nextLine();
|
||||
|
||||
int len = s.length(); //获取字符串长度
|
||||
char[] chars = s.toCharArray();
|
||||
reverseString(chars, 0, len - n - 1); //反转前一段字符串,此时的字符串首尾是0,len - n - 1
|
||||
reverseString(chars, len - n, len - 1); //反转后一段字符串,此时的字符串首尾是len - n,len - 1
|
||||
reverseString(chars, 0, len - 1); //反转整个字符串
|
||||
|
||||
System.out.println(chars);
|
||||
|
||||
}
|
||||
|
||||
public static void reverseString(char[] ch, int start, int end) {
|
||||
//异或法反转字符串,参照题目 344.反转字符串的解释
|
||||
while (start < end) {
|
||||
ch[start] ^= ch[end];
|
||||
ch[end] ^= ch[start];
|
||||
ch[start] ^= ch[end];
|
||||
start++;
|
||||
end--;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Python:
|
||||
```Python
|
||||
#获取输入的数字k和字符串
|
||||
k = int(input())
|
||||
s = input()
|
||||
|
||||
#通过切片反转第一段和第二段字符串
|
||||
#注意:python中字符串是不可变的,所以也需要额外空间
|
||||
s = s[len(s)-k:] + s[:len(s)-k]
|
||||
print(s)
|
||||
```
|
||||
|
||||
### Go:
|
||||
```go
|
||||
package main
|
||||
import "fmt"
|
||||
|
||||
func reverse (strByte []byte, l, r int){
|
||||
for l < r {
|
||||
strByte[l], strByte[r] = strByte[r], strByte[l]
|
||||
l++
|
||||
r--
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
func main(){
|
||||
var str string
|
||||
var target int
|
||||
|
||||
fmt.Scanln(&target)
|
||||
fmt.Scanln(&str)
|
||||
strByte := []byte(str)
|
||||
|
||||
reverse(strByte, 0, len(strByte) - 1)
|
||||
reverse(strByte, 0, target - 1)
|
||||
reverse(strByte, target, len(strByte) - 1)
|
||||
|
||||
fmt.Printf(string(strByte))
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### JavaScript:
|
||||
|
||||
|
||||
### TypeScript:
|
||||
|
||||
|
||||
### Swift:
|
||||
|
||||
|
||||
|
||||
### PHP:
|
||||
|
||||
|
||||
### Scala:
|
||||
|
||||
|
||||
### Rust:
|
||||
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
348
problems/kamacoder/0094.城市间货物运输I-SPFA.md
Normal file
348
problems/kamacoder/0094.城市间货物运输I-SPFA.md
Normal file
@@ -0,0 +1,348 @@
|
||||
|
||||
# Bellman_ford 队列优化算法(又名SPFA)
|
||||
|
||||
[卡码网:94. 城市间货物运输 I](https://kamacoder.com/problempage.php?pid=1152)
|
||||
|
||||
题目描述
|
||||
|
||||
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
|
||||
|
||||
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
|
||||
|
||||
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
|
||||
|
||||
|
||||
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
|
||||
|
||||
> 负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
|
||||
|
||||
输入描述
|
||||
|
||||
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
|
||||
|
||||
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v(单向图)。
|
||||
|
||||
输出描述
|
||||
|
||||
如果能够从城市 1 到连通到城市 n, 请输出一个整数,表示运输成本。如果该整数是负数,则表示实现了盈利。如果从城市 1 没有路径可达城市 n,请输出 "unconnected"。
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
6 7
|
||||
5 6 -2
|
||||
1 2 1
|
||||
5 3 1
|
||||
2 5 2
|
||||
2 4 -3
|
||||
4 6 4
|
||||
1 3 5
|
||||
```
|
||||
|
||||
## 思路
|
||||
|
||||
本题我们来系统讲解 Bellman_ford 队列优化算法 ,也叫SPFA算法(Shortest Path Faster Algorithm)。
|
||||
|
||||
> SPFA的称呼来自 1994年西南交通大学段凡丁的论文,其实Bellman_ford 提出后不久 (20世纪50年代末期) 就有队列优化的版本,国际上不承认这个算法是是国内提出的。 所以国际上一般称呼 算法为 Bellman_ford 队列优化算法(Queue improved Bellman-Ford)
|
||||
|
||||
大家知道以上来历,知道 SPFA 和 Bellman_ford 队列优化算法 指的都是一个算法就好。
|
||||
|
||||
如果大家还不够了解 Bellman_ford 算法,强烈建议按照《代码随想录》的顺序学习,否则可能看不懂下面的讲解。
|
||||
|
||||
大家可以发现 Bellman_ford 算法每次松弛 都是对所有边进行松弛。
|
||||
|
||||
但真正有效的松弛,是基于已经计算过的节点在做的松弛。
|
||||
|
||||
给大家举一个例子:
|
||||
|
||||
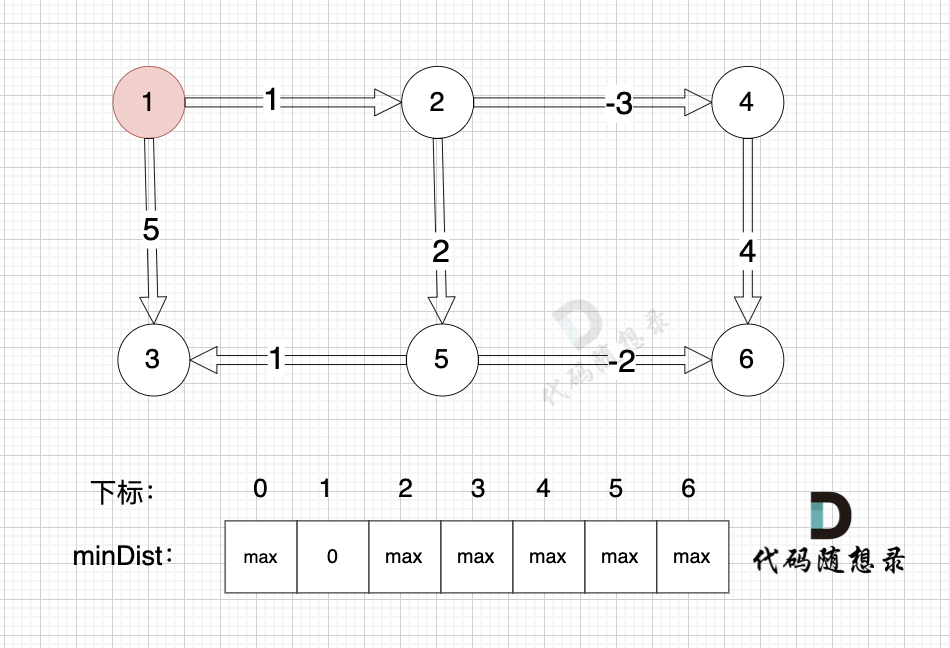
|
||||
|
||||
本图中,对所有边进行松弛,真正有效的松弛,只有松弛 边(节点1->节点2) 和 边(节点1->节点5) 。
|
||||
|
||||
而松弛 边(节点4->节点6) ,边(节点5->节点3)等等 都是无效的操作,因为 节点4 和 节点 5 都是没有被计算过的节点。
|
||||
|
||||
|
||||
所以 Bellman_ford 算法 每次都是对所有边进行松弛,其实是多做了一些无用功。
|
||||
|
||||
**只需要对 上一次松弛的时候更新过的节点作为出发节点所连接的边 进行松弛就够了**。
|
||||
|
||||
基于以上思路,如何记录 上次松弛的时候更新过的节点呢?
|
||||
|
||||
用队列来记录。(其实用栈也行,对元素顺序没有要求)
|
||||
|
||||
接下来来举例这个队列是如何工作的。
|
||||
|
||||
以示例给出的所有边为例:
|
||||
|
||||
```
|
||||
5 6 -2
|
||||
1 2 1
|
||||
5 3 1
|
||||
2 5 2
|
||||
2 4 -3
|
||||
4 6 4
|
||||
1 3 5
|
||||
```
|
||||
|
||||
我们依然使用**minDist数组来表达 起点到各个节点的最短距离**,例如minDist[3] = 5 表示起点到达节点3 的最小距离为5
|
||||
|
||||
初始化,起点为节点1, 起点到起点的最短距离为0,所以minDist[1] 为 0。 将节点1 加入队列 (下次松弛送节点1开始)
|
||||
|
||||
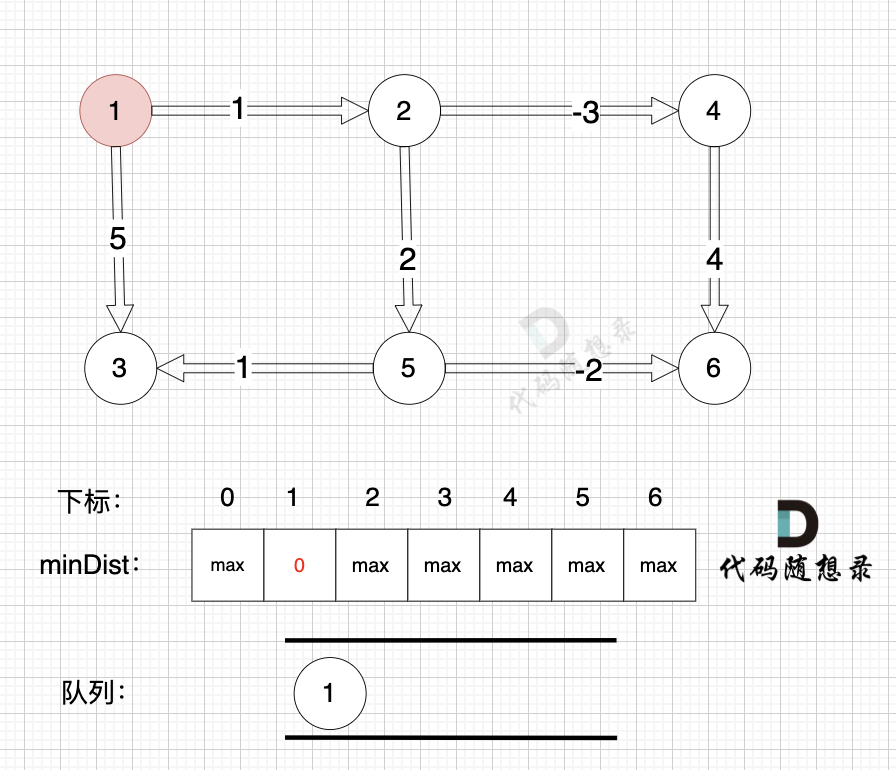
|
||||
|
||||
------------
|
||||
|
||||
从队列里取出节点1,松弛节点1 作为出发点链接的边(节点1 -> 节点2)和边(节点1 -> 节点3)
|
||||
|
||||
边:节点1 -> 节点2,权值为1 ,minDist[2] > minDist[1] + 1 ,更新 minDist[2] = minDist[1] + 1 = 0 + 1 = 1 。
|
||||
|
||||
边:节点1 -> 节点3,权值为5 ,minDist[3] > minDist[1] + 5,更新 minDist[3] = minDist[1] + 5 = 0 + 5 = 5。
|
||||
|
||||
将节点2,节点3 加入队列,如图:
|
||||
|
||||
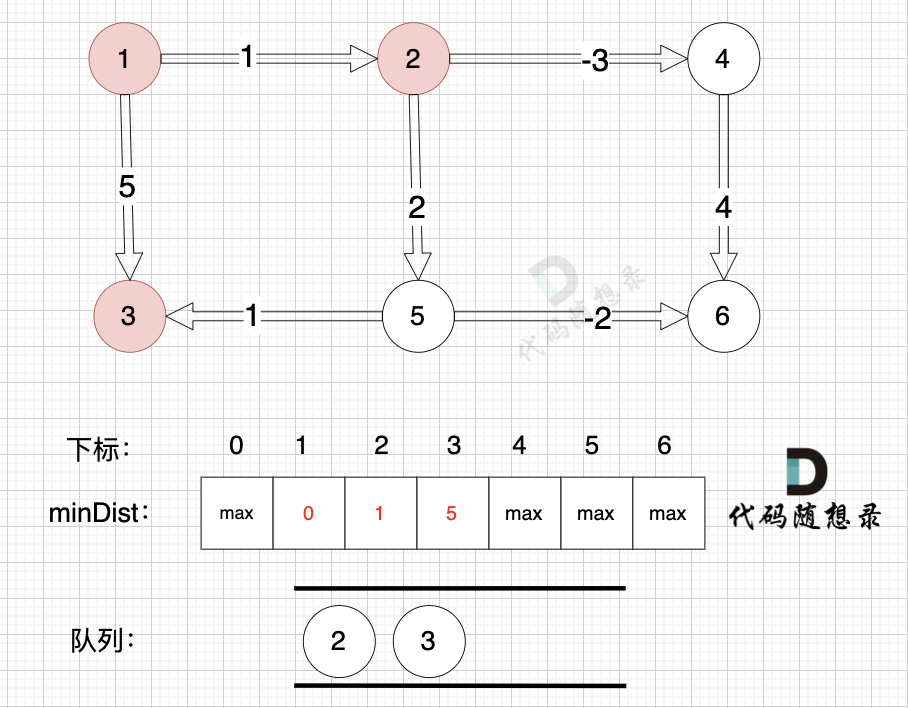
|
||||
|
||||
|
||||
-----------------
|
||||
|
||||
|
||||
从队列里取出节点2,松弛节点2 作为出发点链接的边(节点2 -> 节点4)和边(节点2 -> 节点5)
|
||||
|
||||
边:节点2 -> 节点4,权值为1 ,minDist[4] > minDist[2] + (-3) ,更新 minDist[4] = minDist[2] + (-3) = 1 + (-3) = -2 。
|
||||
|
||||
边:节点2 -> 节点5,权值为2 ,minDist[5] > minDist[2] + 2 ,更新 minDist[5] = minDist[2] + 2 = 1 + 2 = 3 。
|
||||
|
||||
|
||||
将节点4,节点5 加入队列,如图:
|
||||
|
||||
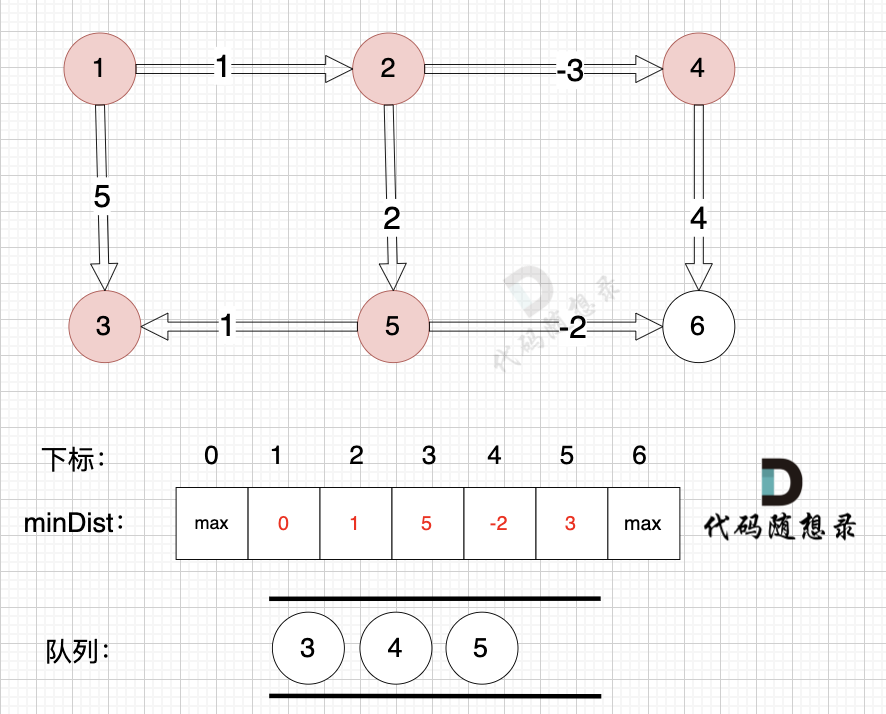
|
||||
|
||||
|
||||
--------------------
|
||||
|
||||
|
||||
从队列里出去节点3,松弛节点3 作为出发点链接的边。
|
||||
|
||||
因为没有从节点3作为出发点的边,所以这里就从队列里取出节点3就好,不用做其他操作,如图:
|
||||
|
||||
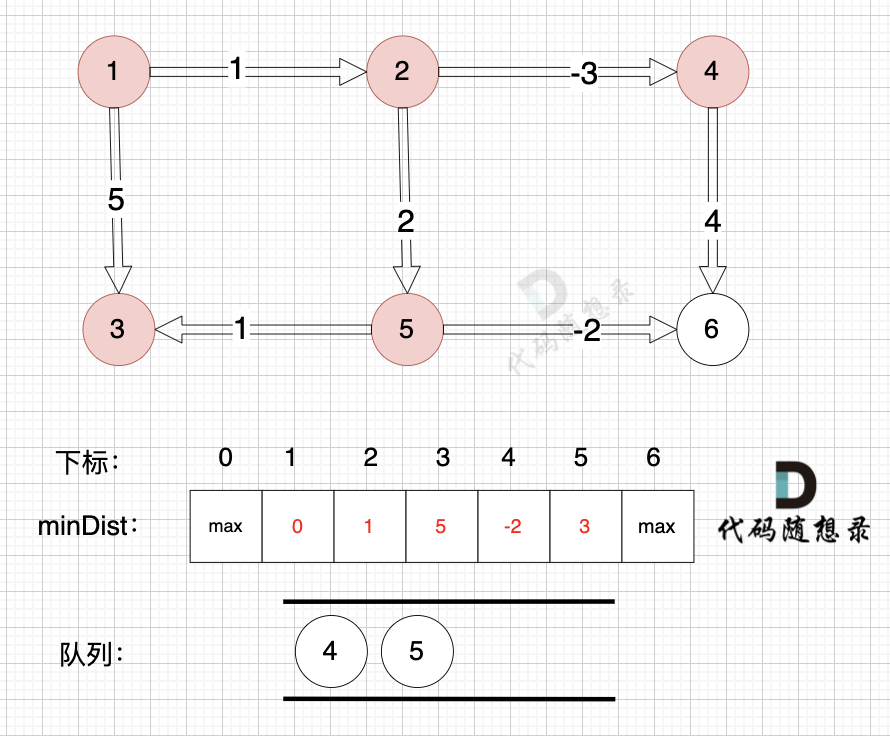
|
||||
|
||||
|
||||
------------
|
||||
|
||||
从队列中取出节点4,松弛节点4作为出发点链接的边(节点4 -> 节点6)
|
||||
|
||||
边:节点4 -> 节点6,权值为4 ,minDist[6] > minDist[4] + 4,更新 minDist[6] = minDist[4] + 4 = -2 + 4 = 2 。
|
||||
|
||||
讲节点6加入队列
|
||||
|
||||
如图:
|
||||
|
||||
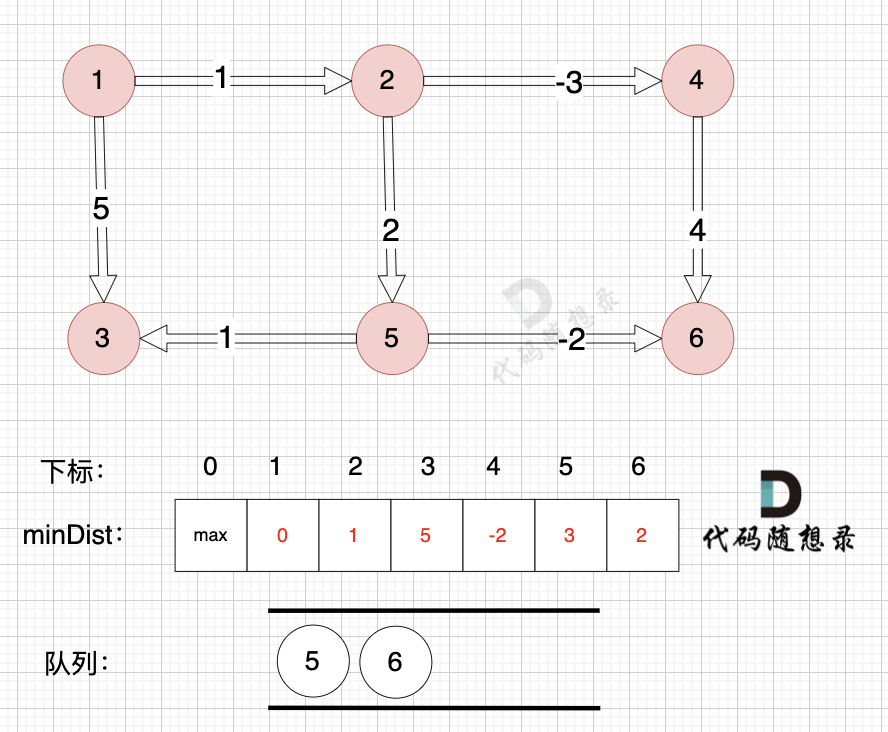
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
从队列中取出节点5,松弛节点5作为出发点链接的边(节点5 -> 节点3),边(节点5 -> 节点6)
|
||||
|
||||
边:节点5 -> 节点3,权值为1 ,minDist[3] > minDist[5] + 1 ,更新 minDist[3] = minDist[5] + 1 = 3 + 1 = 4
|
||||
|
||||
边:节点5 -> 节点6,权值为-2 ,minDist[6] > minDist[5] + (-2) ,更新 minDist[6] = minDist[5] + (-2) = 3 - 2 = 1
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
因为节点3,和 节点6 都曾经加入过队列,不用重复加入,避免重复计算。
|
||||
|
||||
在代码中我们可以用一个数组 visited 来记录入过队列的元素,加入过队列的元素,不再重复入队列。
|
||||
|
||||
|
||||
--------------
|
||||
|
||||
从队列中取出节点6,松弛节点6 作为出发点链接的边。
|
||||
|
||||
节点6作为终点,没有可以出发的边。
|
||||
|
||||
所以直接从队列中取出,如图:
|
||||
|
||||
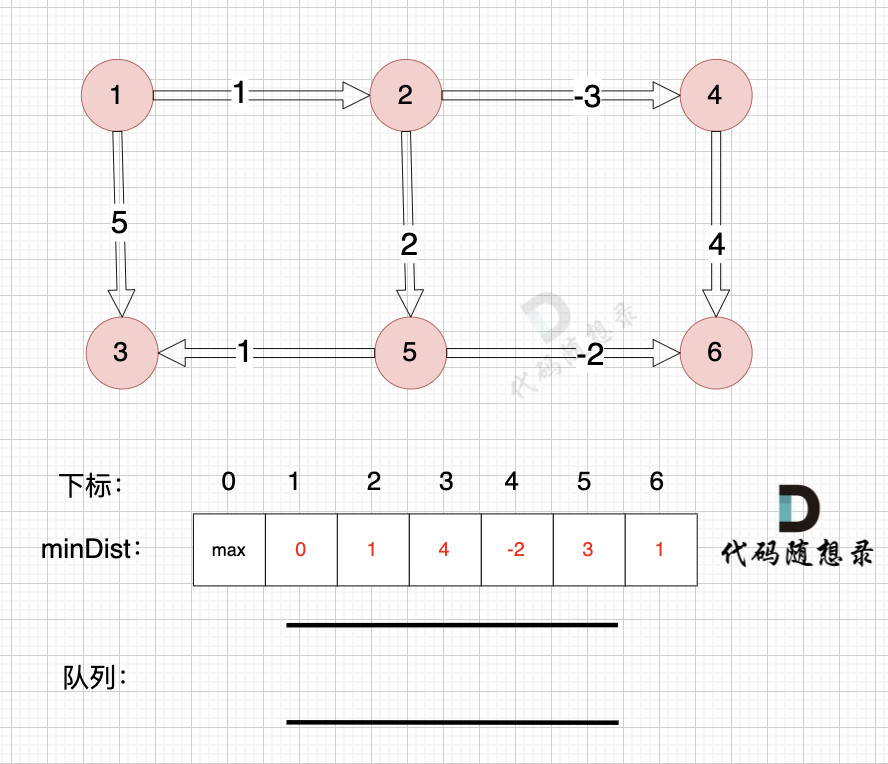
|
||||
|
||||
|
||||
----------
|
||||
|
||||
这样我们就完成了基于队列优化的bellman_ford的算法模拟过程。
|
||||
|
||||
大家可以发现 基于队列优化的算法,要比bellman_ford 算法 减少很多无用的松弛情况,特别是对于边数众多的大图 优化效果明显。
|
||||
|
||||
了解了大体流程,我们再看代码应该怎么写。
|
||||
|
||||
在上面模拟过程中,我们每次都要知道 一个节点作为出发点 链接了哪些节点。
|
||||
|
||||
如果想方便知道这些数据,就需要使用邻接表来存储这个图,如果对于邻接表不了解的话,可以看 [kama0047.参会dijkstra堆](./kama0047.参会dijkstra堆.md) 中 图的存储 部分。
|
||||
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
struct Edge { //邻接表
|
||||
int to; // 链接的节点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<list<Edge>> grid(n + 1); // 邻接表
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1].push_back(Edge(p2, val));
|
||||
}
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[start] = 0;
|
||||
|
||||
queue<int> que;
|
||||
que.push(start); // 队列里放入起点
|
||||
|
||||
while (!que.empty()) {
|
||||
|
||||
int node = que.front(); que.pop();
|
||||
|
||||
for (Edge edge : grid[node]) {
|
||||
int from = node;
|
||||
int to = edge.to;
|
||||
int value = edge.val;
|
||||
if (minDist[to] > minDist[from] + value) { // 开始松弛
|
||||
minDist[to] = minDist[from] + value;
|
||||
que.push(to);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
## 效率分析
|
||||
|
||||
队列优化版Bellman_ford 的时间复杂度 并不稳定,效率高低依赖于图的结构。
|
||||
|
||||
例如 如果是一个双向图,且每一个节点和所有其他节点都相连的话,那么该算法的时间复杂度就接近于 Bellman_ford 的 O(N * E) N 为节点数量,E为边的数量。
|
||||
|
||||
在这种图中,每一个节点都会重复加入队列 n - 1次,因为 这种图中 每个节点 都有 n-1 条指向该节点的边,每条边指向该节点,就需要加入一次队列。(如果这里看不懂,可以在重温一下代码逻辑)
|
||||
|
||||
至于为什么 双向图且每一个节点和所有其他节点都相连的话,每个节点 都有 n-1 条指向该节点的边, 我再来举个例子,如图:
|
||||
|
||||
[](https://code-thinking-1253855093.file.myqcloud.com/pics/20240416104138.png)
|
||||
|
||||
图中 每个节点都与其他所有节点相连,节点数n 为 4,每个节点都有3条指向该节点的边,即入度为3。
|
||||
|
||||
n为其他数值的时候,也是一样的。
|
||||
|
||||
当然这种图是比较极端的情况,也是最稠密的图。
|
||||
|
||||
所以如果图越稠密,则 SPFA的效率越接近与 Bellman_ford。
|
||||
|
||||
反之,图越稀疏,SPFA的效率就越高。
|
||||
|
||||
一般来说,SPFA 的时间复杂度为 O(K * N) K 为不定值,因为 节点需要计入几次队列取决于 图的稠密度。
|
||||
|
||||
如果图是一条线形图且单向的话,每个节点的入度为1,那么只需要加入一次队列,这样时间复杂度就是 O(N)。
|
||||
|
||||
所以 SPFA 在最坏的情况下是 O(N * E),但 一般情况下 时间复杂度为 O(K * N)。
|
||||
|
||||
尽管如此,**以上分析都是 理论上的时间复杂度分析**。
|
||||
|
||||
并没有计算 出队列 和 入队列的时间消耗。 因为这个在不同语言上 时间消耗也是不一定的。
|
||||
|
||||
以C++为例,以下两端代码理论上,时间复杂度都是 O(n) :
|
||||
|
||||
```CPP
|
||||
for (long long i = 0; i < n; i++) {
|
||||
k++;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
```CPP
|
||||
for (long long i = 0; i < n; i++) {
|
||||
que.push(i);
|
||||
que.front();
|
||||
que.pop();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
在 MacBook Pro (13-inch, M1, 2020) 机器上分别测试这两段代码的时间消耗情况:
|
||||
|
||||
* n = 10^4,第一段代码的时间消耗:1ms,第二段代码的时间消耗: 4 ms
|
||||
* n = 10^5,第一段代码的时间消耗:1ms,第二段代码的时间消耗: 13 ms
|
||||
* n = 10^6,第一段代码的时间消耗:4ms,第二段代码的时间消耗: 59 ms
|
||||
* n = 10^7,第一段代码的时间消耗: 24ms,第二段代码的时间消耗: 463 ms
|
||||
* n = 10^8,第一段代码的时间消耗: 135ms,第二段代码的时间消耗: 4268 ms
|
||||
|
||||
在这里就可以看出 出队列和入队列 其实也是十分耗时的。
|
||||
|
||||
SPFA(队列优化版Bellman_ford) 在理论上 时间复杂度更胜一筹,但实际上,也要看图的稠密程度,如果 图很大且非常稠密的情况下,虽然 SPFA的时间复杂度接近Bellman_ford,但实际时间消耗 可能是 SPFA耗时更多。
|
||||
|
||||
针对这种情况,我在后面题目讲解中,会特别加入稠密图的测试用例来给大家讲解。
|
||||
|
||||
|
||||
## 拓展
|
||||
|
||||
这里可能有录友疑惑,`while (!que.empty())` 队里里 会不会造成死循环? 例如 图中有环,这样一直有元素加入到队列里?
|
||||
|
||||
其实有环的情况,要看它是 正权回路 还是 负全回路。
|
||||
|
||||
题目描述中,已经说了,本题没有 负权回路 。
|
||||
|
||||
如图:
|
||||
|
||||
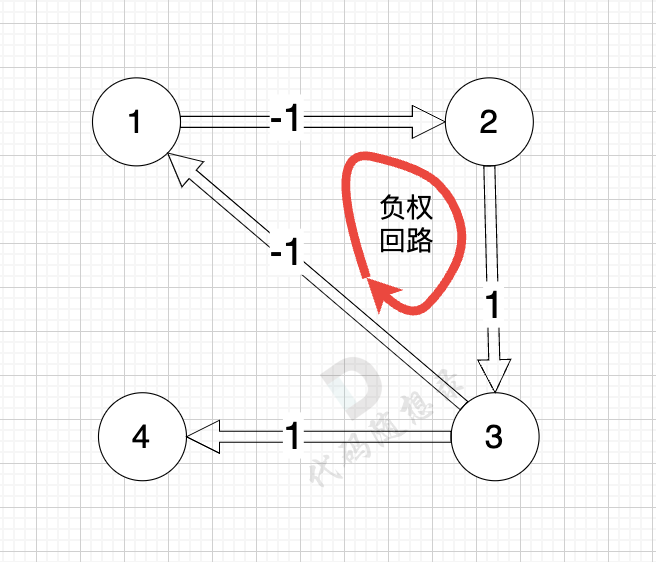
|
||||
|
||||
正权回路 就是有环,但环的总权值为正数。
|
||||
|
||||
在有环且只有正权回路的情况下,即使元素重复加入队列,最后,也会因为 所有边都松弛后,节点数值(minDist数组)不在发生变化了 而终止。
|
||||
|
||||
(而且有重复元素加入队列是正常的,多条路径到达同一个节点,节点必要要选择一个最短的路径,而这个节点就会重复加入队列进行判断,选一个最短的)
|
||||
|
||||
在[0094.城市间货物运输I](./0094.城市间货物运输I.md) 中我们讲过对所有边 最多松弛 n -1 次,就一定可以求出所有起点到所有节点的最小距离即 minDist数组。
|
||||
|
||||
即使再松弛n次以上, 所有起点到所有节点的最小距离(minDist数组) 不会再变了。 (这里如果不理解,建议认真看[0094.城市间货物运输I](./0094.城市间货物运输I.md)讲解)
|
||||
|
||||
所以本题我们使用队列优化,有元素重复加入队列,也会因为最后 minDist数组 不会在发生变化而终止。
|
||||
|
||||
节点再加入队列,需要有松弛的行为, 而 每个节点已经都计算出来 起点到该节点的最短路径,那么就不会有 执行这个判断条件`if (minDist[to] > minDist[from] + value)`,从而不会有新的节点加入到队列。
|
||||
|
||||
但如果本题有 负权回路,那情况就不一样了,我在下一题目讲解中,会重点讲解 负权回路 带来的变化。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
384
problems/kamacoder/0094.城市间货物运输I.md
Normal file
384
problems/kamacoder/0094.城市间货物运输I.md
Normal file
@@ -0,0 +1,384 @@
|
||||
|
||||
# 94. 城市间货物运输 I
|
||||
|
||||
[卡码网: 94. 城市间货物运输 I](https://kamacoder.com/problempage.php?pid=1152)
|
||||
|
||||
题目描述
|
||||
|
||||
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
|
||||
|
||||
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
|
||||
|
||||
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
|
||||
|
||||
|
||||
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
|
||||
|
||||
> 负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
|
||||
|
||||
输入描述
|
||||
|
||||
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
|
||||
|
||||
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v(单向图)。
|
||||
|
||||
输出描述
|
||||
|
||||
如果能够从城市 1 到连通到城市 n, 请输出一个整数,表示运输成本。如果该整数是负数,则表示实现了盈利。如果从城市 1 没有路径可达城市 n,请输出 "unconnected"。
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
6 7
|
||||
5 6 -2
|
||||
1 2 1
|
||||
5 3 1
|
||||
2 5 2
|
||||
2 4 -3
|
||||
4 6 4
|
||||
1 3 5
|
||||
```
|
||||
|
||||
## 思路
|
||||
|
||||
本题依然是最短路问题,求 从 节点1 到节点n 的最小费用。 但本题不同之处在于 边的权值是有负数的。
|
||||
|
||||
从 节点1 到节点n 的最小费用也可以是负数,费用如果是负数 则表示 运输的过程中 政府补贴大于运输成本。
|
||||
|
||||
在求单源最短路的方法中,使用dijkstra 的话,则要求图中边的权值都为正数。
|
||||
|
||||
我们在 [kama47.参会dijkstra朴素](./kama47.参会dijkstra朴素.md) 中专门有讲解,为什么有边为负数 使用dijkstra就不行了。
|
||||
|
||||
本题是经典的带负权值的单源最短路问题,此时就轮到Bellman_ford登场了,接下来我们来详细介绍Bellman_ford 算法 如何解决这类问题。
|
||||
|
||||
> 该算法是由 R.Bellman 和L.Ford 在20世纪50年代末期发明的算法,故称为Bellman_ford算法。
|
||||
|
||||
**Bellman_ford算法的核心思想是 对所有边进行松弛n-1次操作(n为节点数量),从而求得目标最短路**。
|
||||
|
||||
## 什么叫做松弛
|
||||
|
||||
看到这里,估计大家都比较晕了,为什么是 n-1 次,那“松弛”这两个字究竟是个啥意思?
|
||||
|
||||
我们先来说什么是 “松弛”。
|
||||
|
||||
《算法四》里面把这个操作叫做 “放松”, 英文版里叫做 “relax the edge”
|
||||
|
||||
所以大家翻译过来,就是 “放松” 或者 “松弛” 。
|
||||
|
||||
但《算法四》没有具体去讲这个 “放松” 究竟是个啥? 网上的题解也没有讲题解里的 “松弛这条边,松弛所有边”等等 里面的 “松弛” 究竟是什么意思?
|
||||
|
||||
这里我给大家举一个例子,每条边有起点、终点和边的权值。例如一条边,节点A 到 节点B 权值为value,如图:
|
||||
|
||||
|
||||
|
||||
minDist[B] 表示 到达B节点 最小权值,minDist[B] 有哪些状态可以推出来?
|
||||
|
||||
状态一: minDist[A] + value 可以推出 minDist[B]
|
||||
状态二: minDist[B]本身就有权值 (可能是其他边链接的节点B 例如节点C,以至于 dp[B]记录了其他边到dp[B]的权值)
|
||||
|
||||
那么minDist[B] 应为如何取舍。
|
||||
|
||||
本题我们要求最小权值,那么 这两个状态我们就取最小的
|
||||
|
||||
```
|
||||
if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
```
|
||||
|
||||
也就是说,如果 通过 A 到 B 这条边可以获得更短的到达B节点的路径,即如果 `minDist[B] > minDist[A] + value`,那么我们就更新 `minDist[B] = minDist[A] + value` ,**这个过程就叫做 “松弛**” 。
|
||||
|
||||
以上讲了这么多,其实都是围绕以下这句代码展开:
|
||||
|
||||
```
|
||||
if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
```
|
||||
|
||||
**这句代码就是 Bellman_ford算法的核心操作**。
|
||||
|
||||
以上代码也可以这么写:`minDist[B] = min(minDist[A] + value, minDist[B]) `
|
||||
|
||||
如果大家看过代码随想录的动态规划章节,会发现 无论是背包问题还是子序列问题,这段代码(递推公式)出现频率非常高的。
|
||||
|
||||
其实 Bellman_ford算法 也是采用了动态规划的思想,即:将一个问题分解成多个决策阶段,通过状态之间的递归关系最后计算出全局最优解。
|
||||
|
||||
(如果理解不了动态规划的思想也无所谓,理解我上面讲的松弛操作就好)
|
||||
|
||||
**那么为什么是 n - 1次 松弛呢**?
|
||||
|
||||
这里要给大家模拟一遍 Bellman_ford 的算法才行,接下来我们来看看对所有边松弛 n -1 次的操作是什么样的。
|
||||
|
||||
我们依然使用**minDist数组来表达 起点到各个节点的最短距离**,例如minDist[3] = 5 表示起点到达节点3 的最小距离为5
|
||||
|
||||
### 模拟过程
|
||||
|
||||
初始化过程。
|
||||
|
||||
起点为节点1, 起点到起点的距离为0,所以 minDist[1] 初始化为0
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
其他节点对应的minDist初始化为max,因为我们要求最小距离,那么还没有计算过的节点 默认是一个最大数,这样才能更新最小距离。
|
||||
|
||||
|
||||
对所有边 进行第一次松弛: (什么是松弛,在上面我已经详细讲过)
|
||||
|
||||
以示例给出的所有边为例:
|
||||
|
||||
```
|
||||
5 6 -2
|
||||
1 2 1
|
||||
5 3 1
|
||||
2 5 2
|
||||
2 4 -3
|
||||
4 6 4
|
||||
1 3 5
|
||||
```
|
||||
|
||||
接下来我们来松弛一遍所有的边。
|
||||
|
||||
边:节点5 -> 节点6,权值为-2 ,minDist[5] 还是默认数值max,所以不能基于 节点5 去更新节点6,如图:
|
||||
|
||||
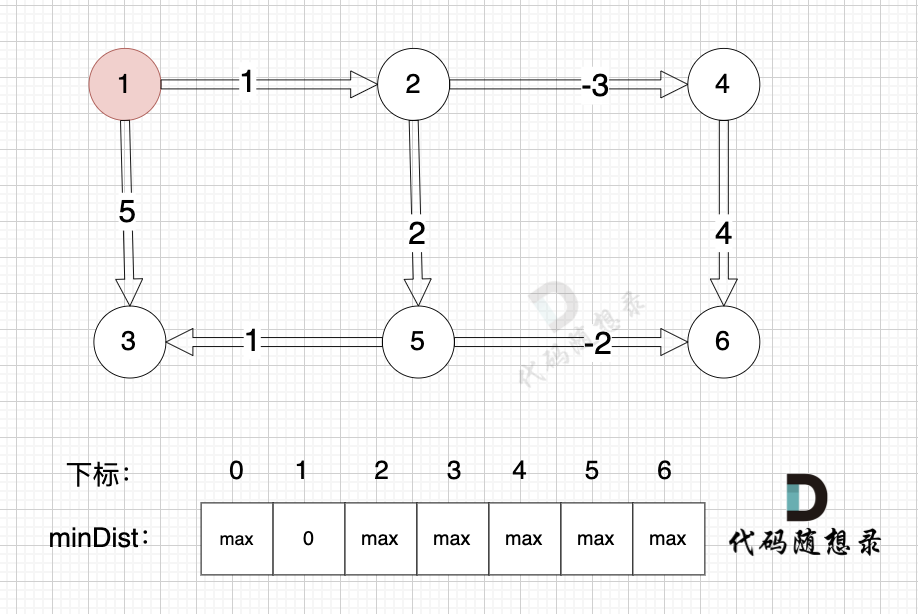
|
||||
|
||||
(在复习一下,minDist[5] 表示起点到节点5的最短距离)
|
||||
|
||||
|
||||
边:节点1 -> 节点2,权值为1 ,minDist[2] > minDist[1] + 1 ,更新 minDist[2] = minDist[1] + 1 = 0 + 1 = 1 ,如图:
|
||||
|
||||
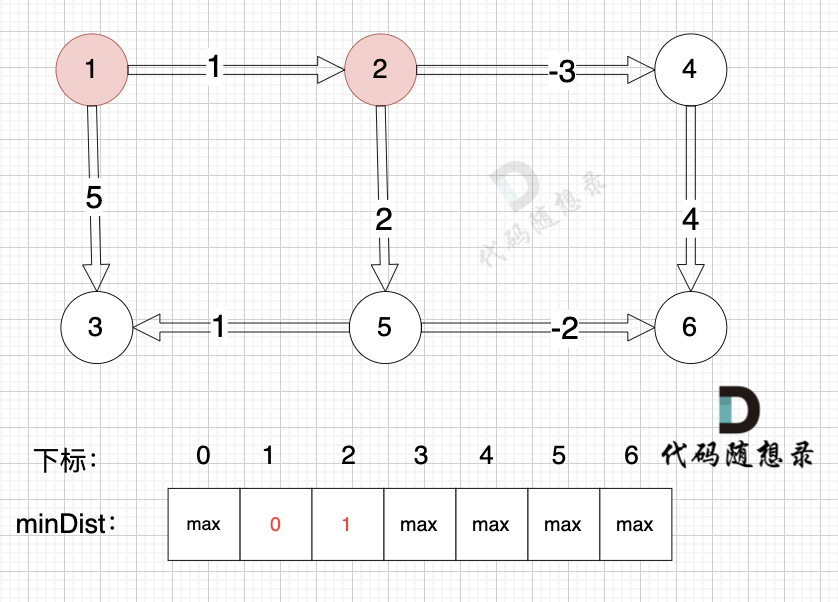
|
||||
|
||||
边:节点5 -> 节点3,权值为1 ,minDist[5] 还是默认数值max,所以不能基于节点5去更新节点3 如图:
|
||||
|
||||
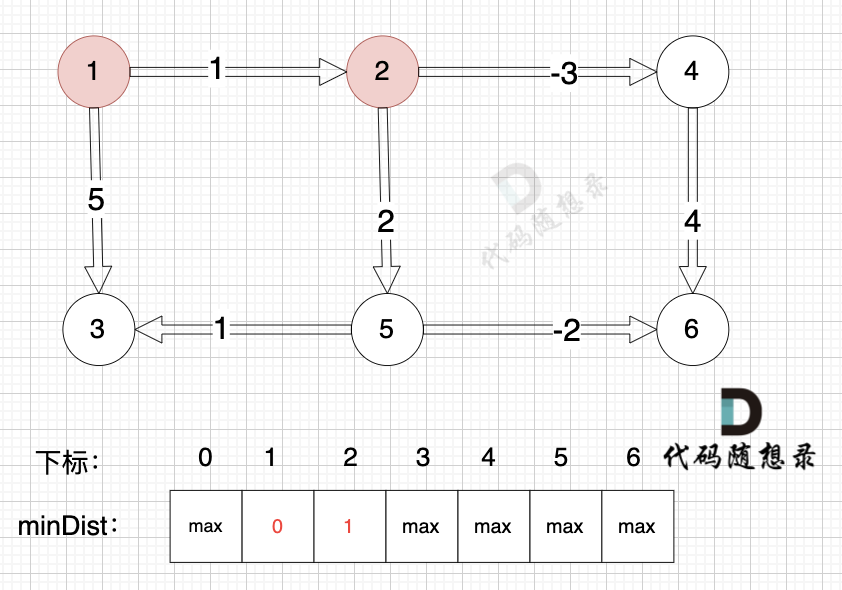
|
||||
|
||||
|
||||
边:节点2 -> 节点5,权值为2 ,minDist[5] > minDist[2] + 2 (经过上面的计算minDist[2]已经不是默认值,而是 1),更新 minDist[5] = minDist[2] + 2 = 1 + 2 = 3 ,如图:
|
||||
|
||||
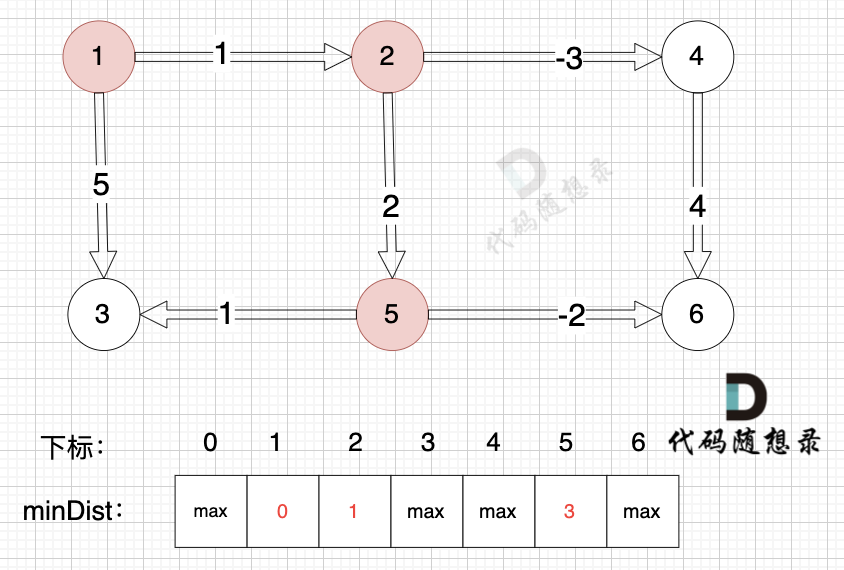
|
||||
|
||||
|
||||
边:节点2 -> 节点4,权值为-3 ,minDist[4] > minDist[2] + (-3),更新 minDist[4] = minDist[2] + (-3) = 1 + (-3) = -2 ,如图:
|
||||
|
||||
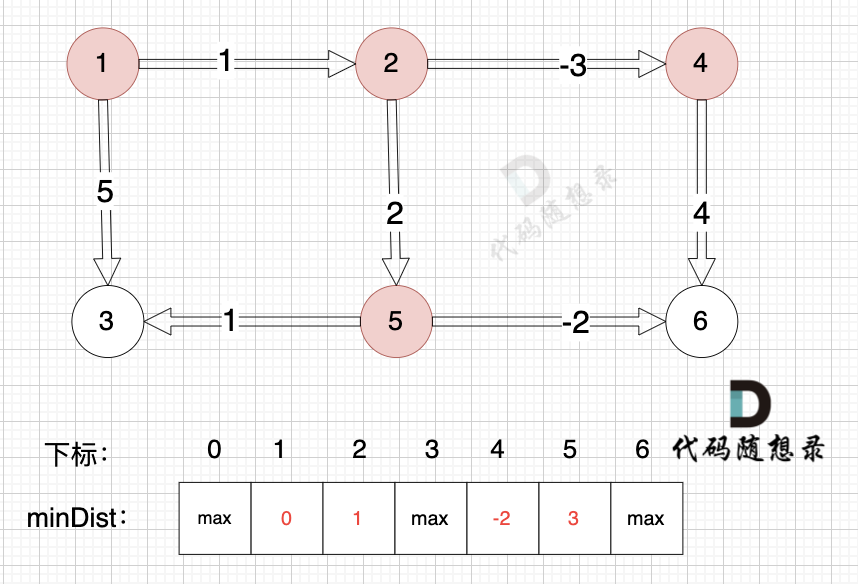
|
||||
|
||||
边:节点4 -> 节点6,权值为4 ,minDist[6] > minDist[4] + 4,更新 minDist[6] = minDist[4] + 4 = -2 + 4 = 2
|
||||
|
||||
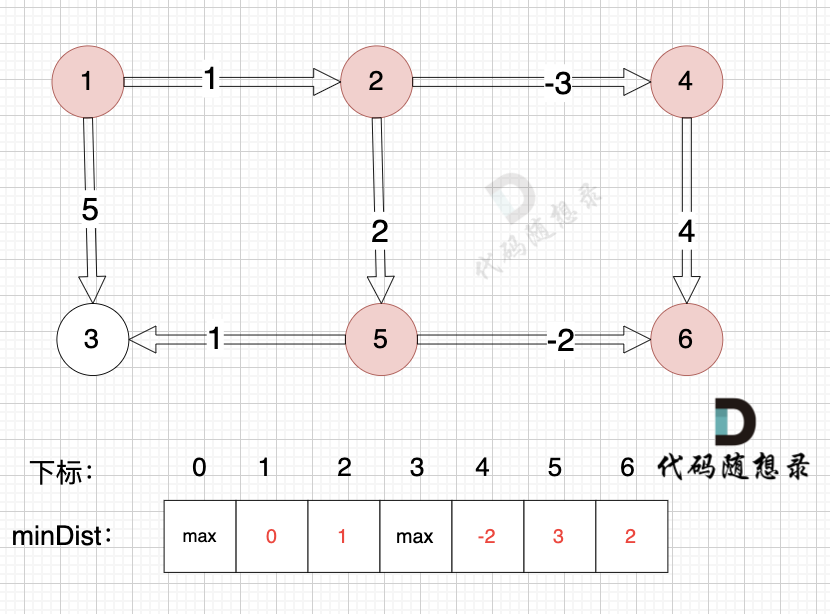
|
||||
|
||||
边:节点1 -> 节点3,权值为5 ,minDist[3] > minDist[1] + 5,更新 minDist[3] = minDist[1] + 5 = 0 + 5 = 5 ,如图:
|
||||
|
||||
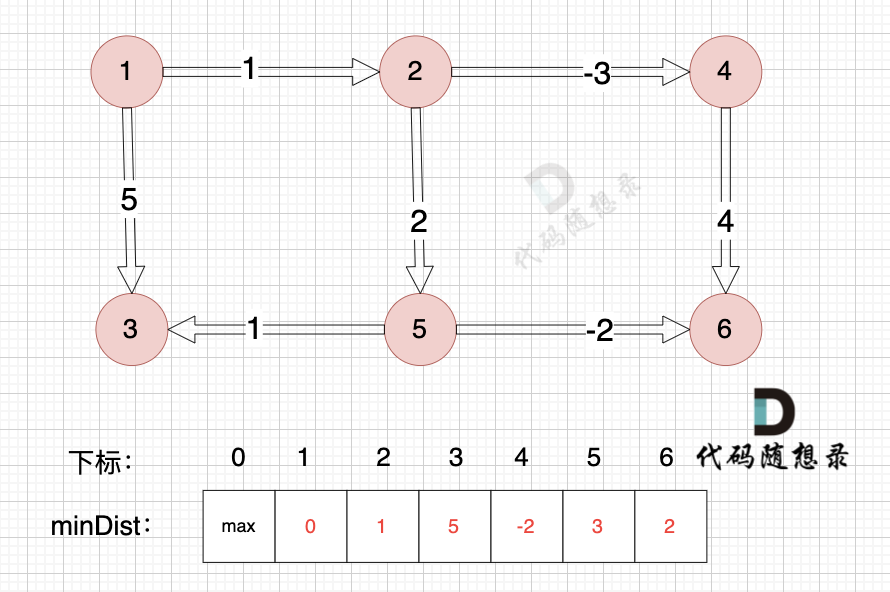
|
||||
|
||||
--------
|
||||
|
||||
以上是对所有边进行一次松弛之后的结果。
|
||||
|
||||
那么需要对所有边松弛几次才能得到 起点(节点1) 到终点(节点6)的最短距离呢?
|
||||
|
||||
**对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**。
|
||||
|
||||
上面的距离中,我们得到里 起点达到 与起点一条边相邻的节点2 和 节点3 的最短距离,分别是 minDist[2] 和 minDist[3]
|
||||
|
||||
这里有录友疑惑了 minDist[3] = 5,分明不是 起点到达 节点3 的最短距离,节点1 -> 节点2 -> 节点5 -> 节点3 这条路线 距离才是4。
|
||||
|
||||
注意我上面讲的是 **对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**,这里 说的是 一条边相连的节点。
|
||||
|
||||
与起点(节点1)一条边相邻的节点,到达节点2 最短距离是 1,到达节点3 最短距离是5。
|
||||
|
||||
而 节点1 -> 节点2 -> 节点5 -> 节点3 这条路线 是 与起点 三条边相连的路线了。
|
||||
|
||||
所以对所有边松弛一次 能得到 与起点 一条边相连的节点最短距离。
|
||||
|
||||
那对所有边松弛两次 可以得到与起点 两条边相连的节点的最短距离。
|
||||
|
||||
那对所有边松弛三次 可以得到与起点 三条边相连的节点的最短距离,这个时候,我们就能得到到达节点3真正的最短距离,也就是 节点1 -> 节点2 -> 节点5 -> 节点3 这条路线。
|
||||
|
||||
那么再回归刚刚的问题,**需要对所有边松弛几次才能得到 起点(节点1) 到终点(节点6)的最短距离呢**?
|
||||
|
||||
节点数量为n,那么起点到终点,最多是 n-1 条边相连。
|
||||
|
||||
那么无论图是什么样的,边是什么样的顺序,我们对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
|
||||
|
||||
其实也同时计算出了,起点 到达 所有节点的最短距离,因为所有节点与起点连接的变数最多也就是 n-1条边。
|
||||
|
||||
截止到这里,Bellman_ford 的核心算法思路,大家就了解的差不多了。
|
||||
|
||||
共有两个关键点。
|
||||
|
||||
* “松弛”究竟是个啥
|
||||
* 为什么要对所有边松弛 n - 1 次 (n为节点个数)
|
||||
|
||||
那么Bellman_ford的解题解题过程其实就是对所有边松弛 n-1 次,然后得出得到终点的最短路径。
|
||||
|
||||
|
||||
|
||||
### 代码
|
||||
|
||||
理解上面讲解的内容,代码就更容易写了,本题代码如下:(详细注释)
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid.push_back({p1, p2, val});
|
||||
|
||||
}
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[start] = 0;
|
||||
for (int i = 1; i < n; i++) { // 对所有边 松弛 n-1 次
|
||||
for (vector<int> &side : grid) { // 每一次松弛,都是对所有边进行松弛
|
||||
int from = side[0]; // 边的出发点
|
||||
int to = side[1]; // 边的到达点
|
||||
int price = side[2]; // 边的权值
|
||||
// 松弛操作
|
||||
// minDist[from] != INT_MAX 防止从未计算过的节点出发
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) {
|
||||
minDist[to] = minDist[from] + price;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
* 时间复杂度: O(N * E) , N为节点数量,E为图中边的数量
|
||||
* 空间复杂度: O(N) ,即 minDist 数组所开辟的空间
|
||||
|
||||
关于空间复杂度,可能有录友疑惑,代码中数组grid不也开辟空间了吗? 为什么只算minDist数组的空间呢?
|
||||
|
||||
grid数组是用来存图的,这是题目描述中必须要使用的空间,而不是我们算法所使用的空间。
|
||||
|
||||
我们在讲空间复杂度的时候,一般都是说,我们这个算法的空间复杂度。
|
||||
|
||||
|
||||
### 拓展
|
||||
|
||||
有录友可能会想,那我 松弛 n 次,松弛 n + 1次,松弛 2 * n 次会怎么样?
|
||||
|
||||
其实没啥影响,结果不会变的,因为 题目中说了 “同时保证道路网络中不存在任何负权回路” 也就是图中没有 负权回路(在有向图中出现有向环 且环的总权值为负数)。
|
||||
|
||||
那么我们只要松弛 n - 1次 就一定能得到结果,没必要在松弛更多次了。
|
||||
|
||||
这里有疑惑的录友,可以加上打印 minDist数组 的日志,尝试一下,看看松弛 n 次会怎么样。
|
||||
你会发现 松弛 大于 n - 1次,minDist数组 就不会变化了。
|
||||
|
||||
这里我给出打印日志的代码:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid.push_back({p1, p2, val});
|
||||
|
||||
}
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[start] = 0;
|
||||
for (int i = 1; i < n; i++) { // 对所有边 松弛 n-1 次
|
||||
for (vector<int> &side : grid) { // 每一次松弛,都是对所有边进行松弛
|
||||
int from = side[0]; // 边的出发点
|
||||
int to = side[1]; // 边的到达点
|
||||
int price = side[2]; // 边的权值
|
||||
// 松弛操作
|
||||
// minDist[from] != INT_MAX 防止从未计算过的节点出发
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) {
|
||||
minDist[to] = minDist[from] + price;
|
||||
}
|
||||
}
|
||||
cout << "对所有边松弛 " << i << "次" << endl;
|
||||
for (int k = 1; k <= n; k++) {
|
||||
cout << minDist[k] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
}
|
||||
if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点
|
||||
else cout << minDist[end] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
通过打日志,大家发现,怎么对所有边进行第二次松弛以后结果就 不再变化了,那根本就不用松弛 n - 1啊?
|
||||
|
||||
这是本题的样例的特殊性, 松弛 n-1次 是保证对任何图 都能最后求得到终点的最小距离。
|
||||
|
||||
如果还想不明白 我再举一个例子,用以下测试用例再跑一下。
|
||||
|
||||
|
||||
```
|
||||
6 5
|
||||
5 6 1
|
||||
4 5 1
|
||||
3 4 1
|
||||
2 3 1
|
||||
1 2 1
|
||||
```
|
||||
|
||||
打印结果:
|
||||
|
||||
```
|
||||
对所有边松弛 1次
|
||||
0 1 2147483647 2147483647 2147483647 2147483647
|
||||
对所有边松弛 2次
|
||||
0 1 2 2147483647 2147483647 2147483647
|
||||
对所有边松弛 3次
|
||||
0 1 2 3 2147483647 2147483647
|
||||
对所有边松弛 4次
|
||||
0 1 2 3 4 2147483647
|
||||
对所有边松弛 5次
|
||||
0 1 2 3 4 5
|
||||
```
|
||||
|
||||
你会发现到 n-1 次 打印出最后的最短路结果。
|
||||
|
||||
关于上面的讲解,大家已经要多写代码去实验,验证自己的想法。
|
||||
|
||||
至于 负权回路 ,我在下一篇会专门讲解这种情况,大家有个印象就好。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
Bellman_ford 是可以计算 负权值的单源最短路算法。
|
||||
|
||||
其算法核心思路是对 所有边进行 n-1 次 松弛。
|
||||
|
||||
弄清楚 什么是 松弛? 为什么要 n-1 次? 对理解Bellman_ford 非常重要。
|
||||
|
||||
240
problems/kamacoder/0095.城市间货物运输II.md
Normal file
240
problems/kamacoder/0095.城市间货物运输II.md
Normal file
@@ -0,0 +1,240 @@
|
||||
|
||||
# 95. 城市间货物运输 II
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1153)
|
||||
|
||||
【题目描述】
|
||||
|
||||
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
|
||||
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;
|
||||
|
||||
权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
|
||||
然而,在评估从城市 1 到城市 n 的所有可能路径中综合政府补贴后的最低运输成本时,存在一种情况:**图中可能出现负权回路**。
|
||||
|
||||
负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
|
||||
|
||||
为了避免货物运输商采用负权回路这种情况无限的赚取政府补贴,算法还需检测这种特殊情况。
|
||||
|
||||
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。同时能够检测并适当处理负权回路的存在。
|
||||
|
||||
城市 1 到城市 n 之间可能会出现没有路径的情况
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
|
||||
|
||||
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v。
|
||||
|
||||
【输出描述】
|
||||
|
||||
如果没有发现负权回路,则输出一个整数,表示从城市 1 到城市 n 的最低运输成本(包括政府补贴)。
|
||||
|
||||
如果该整数是负数,则表示实现了盈利。如果发现了负权回路的存在,则输出 "circle"。如果从城市 1 无法到达城市 n,则输出 "unconnected"。
|
||||
|
||||
|
||||
输入示例
|
||||
|
||||
```
|
||||
4 4
|
||||
1 2 -1
|
||||
2 3 1
|
||||
3 1 -1
|
||||
3 4 1
|
||||
```
|
||||
|
||||
输出示例
|
||||
|
||||
```
|
||||
circle
|
||||
```
|
||||
|
||||
## 思路
|
||||
|
||||
本题是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 延伸题目。
|
||||
|
||||
本题是要我们判断 负权回路,也就是图中出现环且环上的边总权值为负数。
|
||||
|
||||
如果在这样的图中求最短路的话, 就会在这个环里无限循环 (也是负数+负数 只会越来越小),无法求出最短路径。
|
||||
|
||||
所以对于 在有负权值的图中求最短路,都需要先看看这个图里有没有负权回路。
|
||||
|
||||
接下来我们来看 如何使用 bellman_ford 算法来判断 负权回路。
|
||||
|
||||
在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 中 我们讲了 bellman_ford 算法的核心就是一句话:对 所有边 进行 n-1 次松弛。 同时文中的 【拓展】部分, 我们也讲了 松弛n次以上 会怎么样?
|
||||
|
||||
在没有负权回路的图中,松弛 n 次以上 ,结果不会有变化。
|
||||
|
||||
但本题有 负权回路,如果松弛 n 次,结果就会有变化了,因为 有负权回路 就是可以无限最短路径(一直绕圈,就可以一直得到无限小的最短距离)。
|
||||
|
||||
那么每松弛一次,都会更新最短路径,所以结果会一直有变化。
|
||||
|
||||
(如果对于 bellman_ford 不了解的录友,建议详细看这里:[kama94.城市间货物运输I](./kama94.城市间货物运输I.md))
|
||||
|
||||
以上为理论分析,接下来我们再画图举例。
|
||||
|
||||
我们拿题目中示例来画一个图:
|
||||
|
||||

|
||||
|
||||
图中 节点1 到 节点4 的最短路径是多少(题目中的最低运输成本) (注意边可以为负数的)
|
||||
|
||||
节点1 -> 节点2 -> 节点3 -> 节点4,这样的路径总成本为 -1 + 1 + 1 = 1
|
||||
|
||||
而图中有负权回路:
|
||||
|
||||
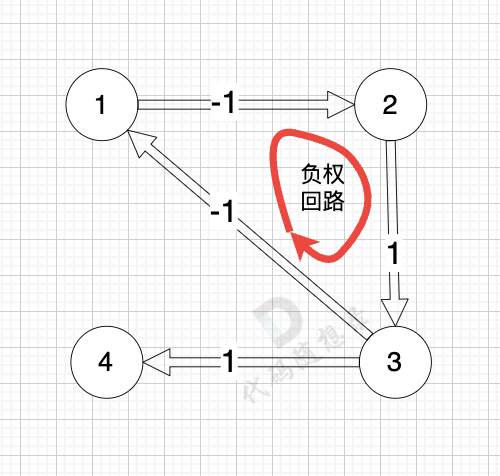
|
||||
|
||||
那么我们在负权回路中多绕一圈,我们的最短路径 是不是就更小了 (也就是更低的运输成本)
|
||||
|
||||
节点1 -> 节点2 -> 节点3 -> 节点1 -> 节点2 -> 节点3 -> 节点4,这样的路径总成本 (-1) + 1 + (-1) + (-1) + 1 + (-1) + 1 = -1
|
||||
|
||||
如果在负权回路多绕两圈,三圈,无穷圈,那么我们的总成本就会无限小, 如果要求最小成本的话,你会发现本题就无解了。
|
||||
|
||||
在 bellman_ford 算法中,松弛 n-1 次所有的边 就可以求得 起点到任何节点的最短路径,松弛 n 次以上,minDist数组(记录起到到其他节点的最短距离)中的结果也不会有改变 (如果对 bellman_ford 算法 不了解,也不知道 minDist 是什么,建议详看上篇讲解[kama94.城市间货物运输I](./kama94.城市间货物运输I.md))
|
||||
|
||||
而本题有负权回路的情况下,一直都会有更短的最短路,所以 松弛 第n次,minDist数组 也会发生改变。
|
||||
|
||||
那么解决本题的 核心思路,就是在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 的基础上,再多松弛一次,看minDist数组 是否发生变化。
|
||||
|
||||
代码和 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 基本是一样的,如下:(关键地方已注释)
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid.push_back({p1, p2, val});
|
||||
|
||||
}
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[start] = 0;
|
||||
bool flag = false;
|
||||
for (int i = 1; i <= n; i++) { // 这里我们松弛n次,最后一次判断负权回路
|
||||
for (vector<int> &side : grid) {
|
||||
int from = side[0];
|
||||
int to = side[1];
|
||||
int price = side[2];
|
||||
if (i < n) {
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) minDist[to] = minDist[from] + price;
|
||||
} else { // 多加一次松弛判断负权回路
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) flag = true;
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (flag) cout << "circle" << endl;
|
||||
else if (minDist[end] == INT_MAX) {
|
||||
cout << "unconnected" << endl;
|
||||
} else {
|
||||
cout << minDist[end] << endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* 时间复杂度: O(N * E) , N为节点数量,E为图中边的数量
|
||||
* 空间复杂度: O(N) ,即 minDist 数组所开辟的空间
|
||||
|
||||
## 拓展
|
||||
|
||||
本题可不可 使用 队列优化版的bellman_ford(SPFA)呢?
|
||||
|
||||
上面的解法中,我们对所有边松弛了n-1次后,在松弛一次,如果出现minDist出现变化就判断有负权回路。
|
||||
|
||||
如果使用 SPFA 那么节点都是进队列的,那么节点进入队列几次后 足够判断该图是否有负权回路呢?
|
||||
|
||||
在 [0094.城市间货物运输I-SPFA](./0094.城市间货物运输I-SPFA) 中,我们讲过 在极端情况下,即:所有节点都与其他节点相连,每个节点的入度为 n-1 (n为节点数量),所以每个节点最多加入 n-1 次队列。
|
||||
|
||||
那么如果节点加入队列的次数 超过了 n-1次 ,那么该图就一定有负权回路。
|
||||
|
||||
所以本题也是可以使用 SPFA 来做的。 代码如下:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
struct Edge { //邻接表
|
||||
int to; // 链接的节点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<list<Edge>> grid(n + 1); // 邻接表
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1].push_back(Edge(p2, val));
|
||||
}
|
||||
int start = 1; // 起点
|
||||
int end = n; // 终点
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[start] = 0;
|
||||
|
||||
queue<int> que;
|
||||
que.push(start); // 队列里放入起点
|
||||
|
||||
vector<int> count(n+1, 0); // 记录节点加入队列几次
|
||||
count[start]++;
|
||||
|
||||
bool flag = false;
|
||||
while (!que.empty()) {
|
||||
|
||||
int node = que.front(); que.pop();
|
||||
|
||||
for (Edge edge : grid[node]) {
|
||||
int from = node;
|
||||
int to = edge.to;
|
||||
int value = edge.val;
|
||||
if (minDist[to] > minDist[from] + value) { // 开始松弛
|
||||
minDist[to] = minDist[from] + value;
|
||||
que.push(to);
|
||||
count[to]++;
|
||||
if (count[to] == n) {// 如果加入队列次数超过 n-1次 就说明该图与负权回路
|
||||
flag = true;
|
||||
while (!que.empty()) que.pop();
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (flag) cout << "circle" << endl;
|
||||
else if (minDist[end] == INT_MAX) {
|
||||
cout << "unconnected" << endl;
|
||||
} else {
|
||||
cout << minDist[end] << endl;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
585
problems/kamacoder/0096.城市间货物运输III.md
Normal file
585
problems/kamacoder/0096.城市间货物运输III.md
Normal file
@@ -0,0 +1,585 @@
|
||||
|
||||
# 96. 城市间货物运输 III
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1154)
|
||||
|
||||
【题目描述】
|
||||
|
||||
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
|
||||
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。
|
||||
|
||||
权值为正表示扣除了政府补贴后运输货物仍需支付的费用;
|
||||
|
||||
权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
|
||||
请计算在最多经过 k 个城市的条件下,从城市 src 到城市 dst 的最低运输成本。
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
|
||||
|
||||
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v。
|
||||
|
||||
最后一行包含三个正整数,src、dst、和 k,src 和 dst 为城市编号,从 src 到 dst 经过的城市数量限制。
|
||||
|
||||
【输出描述】
|
||||
|
||||
输出一个整数,表示从城市 src 到城市 dst 的最低运输成本,如果无法在给定经过城市数量限制下找到从 src 到 dst 的路径,则输出 "unreachable",表示不存在符合条件的运输方案。
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
6 7
|
||||
1 2 1
|
||||
2 4 -3
|
||||
2 5 2
|
||||
1 3 5
|
||||
3 5 1
|
||||
4 6 4
|
||||
5 6 -2
|
||||
2 6 1
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
0
|
||||
```
|
||||
|
||||
## 思路
|
||||
|
||||
本题为单源有限最短路问题,同样是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 延伸题目。
|
||||
|
||||
注意题目中描述是 **最多经过 k 个城市的条件下,而不是一定经过k个城市,也可以经过的城市数量比k小,但要最短的路径**。
|
||||
|
||||
在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 中我们讲了:**对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**。
|
||||
|
||||
节点数量为n,起点到终点,最多是 n-1 条边相连。 那么对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
|
||||
|
||||
(如果对以上讲解看不懂,建议详看 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) )
|
||||
|
||||
本题是最多经过 k 个城市, 那么是 k + 1条边相连的节点。 这里可能有录友想不懂为什么是k + 1,来看这个图:
|
||||
|
||||
|
||||
|
||||
图中,节点2 最多已经经过2个节点 到达节点4,那么中间是有多少条边呢,是 3 条边对吧。
|
||||
|
||||
所以本题就是求:起点最多经过k + 1 条边到达终点的最短距离。
|
||||
|
||||
对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离,那么对所有边松弛 k + 1次,就是求 起点到达 与起点k + 1条边相连的节点的 最短距离。
|
||||
|
||||
**注意**: 本题是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 的拓展题,如果对 bellman_ford 没有深入了解,强烈建议先看 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 再做本题。
|
||||
|
||||
理解以上内容,其实本题代码就很容易了,bellman_ford 标准写法是松弛 n-1 次,本题就松弛 k + 1次就好。
|
||||
|
||||
此时我们可以写出如下代码:
|
||||
|
||||
```CPP
|
||||
// 版本一
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int src, dst,k ,p1, p2, val ,m , n;
|
||||
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid.push_back({p1, p2, val});
|
||||
}
|
||||
|
||||
cin >> src >> dst >> k;
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[src] = 0;
|
||||
for (int i = 1; i <= k + 1; i++) { // 对所有边松弛 k + 1次
|
||||
for (vector<int> &side : grid) {
|
||||
int from = side[0];
|
||||
int to = side[1];
|
||||
int price = side[2];
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) minDist[to] = minDist[from] + price;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
if (minDist[dst] == INT_MAX) cout << "unreachable" << endl; // 不能到达终点
|
||||
else cout << minDist[dst] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
以上代码 标准 bellman_ford 写法,松弛 k + 1次,看上去没什么问题。
|
||||
|
||||
但大家提交后,居然没通过!
|
||||
|
||||
这是为什么呢?
|
||||
|
||||
接下来我们拿这组数据来举例:
|
||||
|
||||
```
|
||||
4 4
|
||||
1 2 -1
|
||||
2 3 1
|
||||
3 1 -1
|
||||
3 4 1
|
||||
1 4 3
|
||||
```
|
||||
|
||||
(**注意上面的示例是有负权回路的,只有带负权回路的图才能说明问题**)
|
||||
|
||||
> 负权回路是指一条道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
|
||||
|
||||
正常来说,这组数据输出应该是 1,但以上代码输出的是 -2。
|
||||
|
||||
|
||||
在讲解原因的时候,强烈建议大家,先把 minDist数组打印出来,看看minDist数组是不是按照自己的想法变化的,这样更容易理解我接下来的讲解内容。 (**一定要动手,实践出真实,脑洞模拟不靠谱**)
|
||||
|
||||
打印的代码可以是这样:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int src, dst,k ,p1, p2, val ,m , n;
|
||||
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid.push_back({p1, p2, val});
|
||||
}
|
||||
|
||||
cin >> src >> dst >> k;
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[src] = 0;
|
||||
for (int i = 1; i <= k + 1; i++) { // 对所有边松弛 k + 1次
|
||||
for (vector<int> &side : grid) {
|
||||
int from = side[0];
|
||||
int to = side[1];
|
||||
int price = side[2];
|
||||
if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) minDist[to] = minDist[from] + price;
|
||||
}
|
||||
// 打印 minDist 数组
|
||||
for (int j = 1; j <= n; j++) cout << minDist[j] << " ";
|
||||
cout << endl;
|
||||
|
||||
}
|
||||
|
||||
if (minDist[dst] == INT_MAX) cout << "unreachable" << endl; // 不能到达终点
|
||||
else cout << minDist[dst] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
接下来,我按照上面的示例带大家 画图举例 对所有边松弛一次 的效果图。
|
||||
|
||||
起点为节点1, 起点到起点的距离为0,所以 minDist[1] 初始化为0 ,如图:
|
||||
|
||||
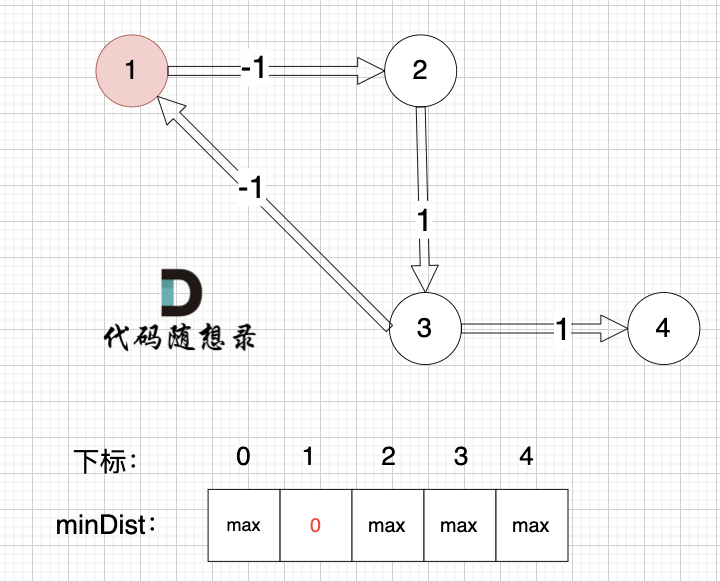
|
||||
|
||||
其他节点对应的minDist初始化为max,因为我们要求最小距离,那么还没有计算过的节点 默认是一个最大数,这样才能更新最小距离。
|
||||
|
||||
当我们开始对所有边开始第一次松弛:
|
||||
|
||||
边:节点1 -> 节点2,权值为-1 ,minDist[2] > minDist[1] + (-1),更新 minDist[2] = minDist[1] + (-1) = 0 - 1 = -1 ,如图:
|
||||
|
||||
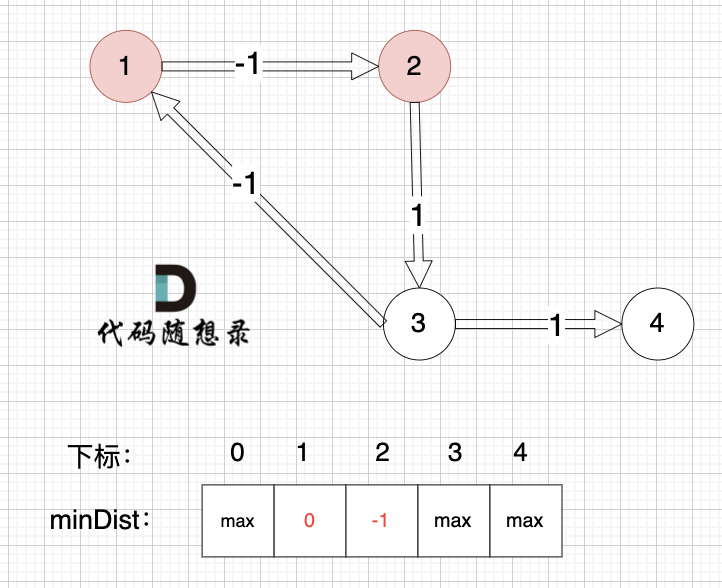
|
||||
|
||||
|
||||
边:节点2 -> 节点3,权值为1 ,minDist[3] > minDist[2] + 1 ,更新 minDist[3] = minDist[2] + 1 = -1 + 1 = 0 ,如图:
|
||||
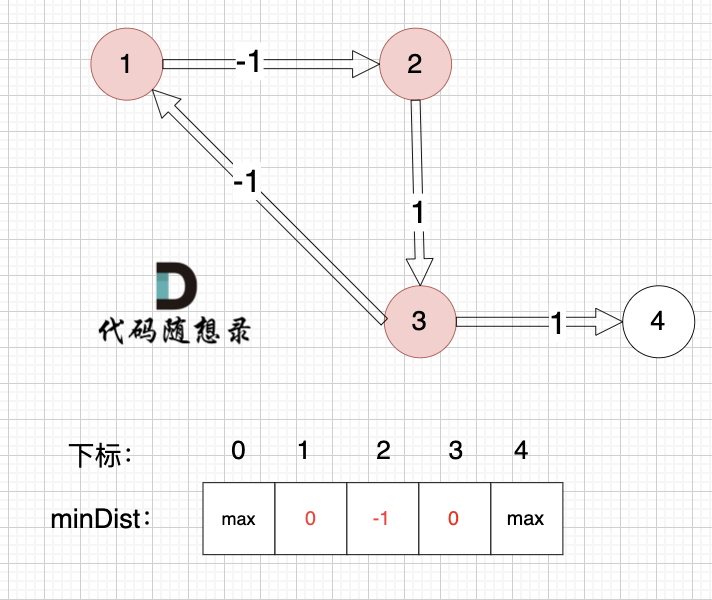
|
||||
|
||||
|
||||
边:节点3 -> 节点1,权值为-1 ,minDist[1] > minDist[3] + (-1),更新 minDist[1] = 0 + (-1) = -1 ,如图:
|
||||
|
||||

|
||||
|
||||
|
||||
边:节点3 -> 节点4,权值为1 ,minDist[4] > minDist[3] + 1,更新 minDist[4] = 0 + (-1) = -1 ,如图:
|
||||
|
||||
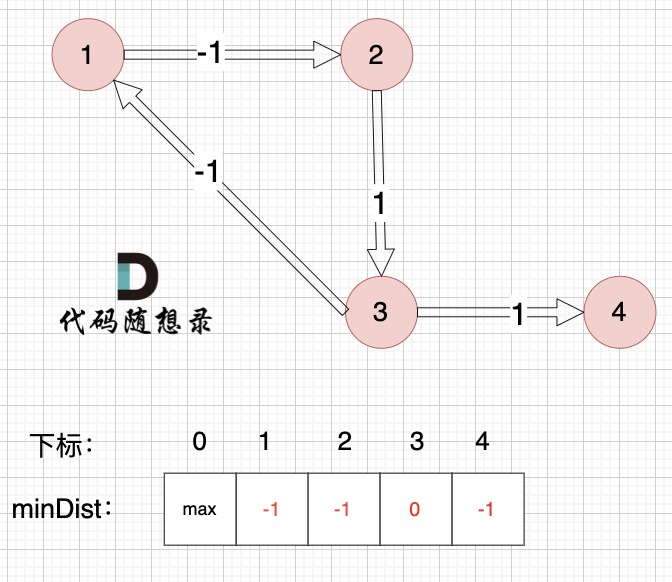
|
||||
|
||||
|
||||
以上是对所有边进行的第一次松弛,最后 minDist数组为 :-1 -1 0 1 ,(从下标1算起)
|
||||
|
||||
后面几次松弛我就不挨个画图了,过程大同小异,我直接给出minDist数组的变化:
|
||||
|
||||
所有边进行的第二次松弛,minDist数组为 : -2 -2 -1 0
|
||||
所有边进行的第三次松弛,minDist数组为 : -3 -3 -2 -1
|
||||
所有边进行的第四次松弛,minDist数组为 : -4 -4 -3 -2 (本示例中k为3,所以松弛4次)
|
||||
|
||||
最后计算的结果minDist[4] = -2,即 起点到 节点4,最多经过 3 个节点的最短距离是 -2,但 正确的结果应该是 1,即路径:节点1 -> 节点2 -> 节点3 -> 节点4。
|
||||
|
||||
理论上来说,**对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**。
|
||||
|
||||
对所有边松弛两次,相当于计算 起点到达 与起点两条边相连的节点的最短距离。
|
||||
|
||||
对所有边松弛三次,以此类推。
|
||||
|
||||
但在对所有边松弛第一次的过程中,大家会发现,不仅仅 与起点一条边相连的节点更新了,所有节点都更新了。
|
||||
|
||||
而且对所有边的后面几次松弛,同样是更新了所有的节点,说明 至多经过k 个节点 这个限制 根本没有限制住,每个节点的数值都被更新了。
|
||||
|
||||
这是为什么?
|
||||
|
||||
在上面画图距离中,对所有边进行第一次松弛,在计算 边(节点2 -> 节点3) 的时候,更新了 节点3。
|
||||
|
||||

|
||||
|
||||
理论上来说节点3 应该在对所有边第二次松弛的时候才更新。 这因为当时是基于已经计算好的 节点2(minDist[2])来做计算了。
|
||||
|
||||
minDist[2]在计算边:(节点1 -> 节点2)的时候刚刚被赋值为 -1。
|
||||
|
||||
这样就造成了一个情况,即:计算minDist数组的时候,基于了本次松弛的 minDist数值,而不是上一次 松弛时候minDist的数值。
|
||||
所以在每次计算 minDist 时候,要基于 对所有边上一次松弛的 minDist 数值才行,所以我们要记录上一次松弛的minDist。
|
||||
|
||||
代码修改如下: (关键地方已经注释)
|
||||
|
||||
```CPP
|
||||
// 版本二
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int src, dst,k ,p1, p2, val ,m , n;
|
||||
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid;
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid.push_back({p1, p2, val});
|
||||
}
|
||||
|
||||
cin >> src >> dst >> k;
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
minDist[src] = 0;
|
||||
vector<int> minDist_copy(n + 1); // 用来记录上一次遍历的结果
|
||||
for (int i = 1; i <= k + 1; i++) {
|
||||
minDist_copy = minDist; // 获取上一次计算的结果
|
||||
for (vector<int> &side : grid) {
|
||||
int from = side[0];
|
||||
int to = side[1];
|
||||
int price = side[2];
|
||||
// 注意使用 minDist_copy 来计算 minDist
|
||||
if (minDist_copy[from] != INT_MAX && minDist[to] > minDist_copy[from] + price) {
|
||||
minDist[to] = minDist_copy[from] + price;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (minDist[dst] == INT_MAX) cout << "unreachable" << endl; // 不能到达终点
|
||||
else cout << minDist[dst] << endl; // 到达终点最短路径
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度: O(K * E) , K为至多经过K个节点,E为图中边的数量
|
||||
* 空间复杂度: O(N) ,即 minDist 数组所开辟的空间
|
||||
|
||||
## 拓展一(边的顺序的影响)
|
||||
|
||||
其实边的顺序会影响我们每一次拓展的结果。
|
||||
|
||||
我来给大家举个例子。
|
||||
|
||||
我上面讲解中,给出的示例是这样的:
|
||||
```
|
||||
4 4
|
||||
1 2 -1
|
||||
2 3 1
|
||||
3 1 -1
|
||||
3 4 1
|
||||
1 4 3
|
||||
```
|
||||
|
||||
我将示例中边的顺序改一下,给成:
|
||||
|
||||
```
|
||||
4 4
|
||||
3 1 -1
|
||||
3 4 1
|
||||
2 3 1
|
||||
1 2 -1
|
||||
1 4 3
|
||||
```
|
||||
|
||||
所构成是图是一样的,都是如下的这个图,但给出的边的顺序是不一样的。
|
||||
|
||||
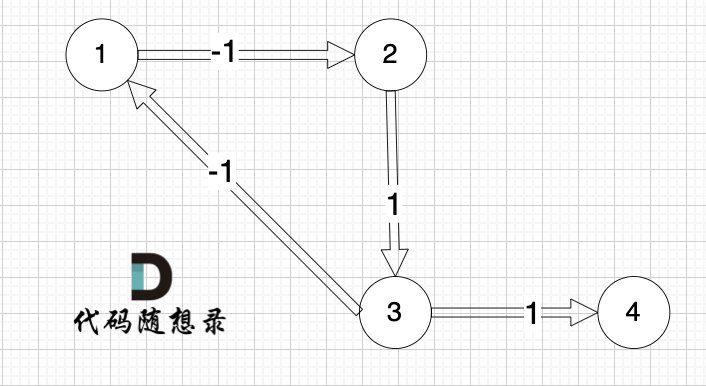
|
||||
|
||||
再用版本一的代码是运行一下,发现结果输出是 1, 是对的。
|
||||
|
||||

|
||||
|
||||
分明刚刚输出的结果是 -2,是错误的,怎么 一样的图,这次输出的结果就对了呢?
|
||||
|
||||
其实这是和示例中给出的边的顺序是有关的,
|
||||
|
||||
我们按照修改后的示例再来模拟 对所有边的第一次拓展情况。
|
||||
|
||||
初始化:
|
||||
|
||||
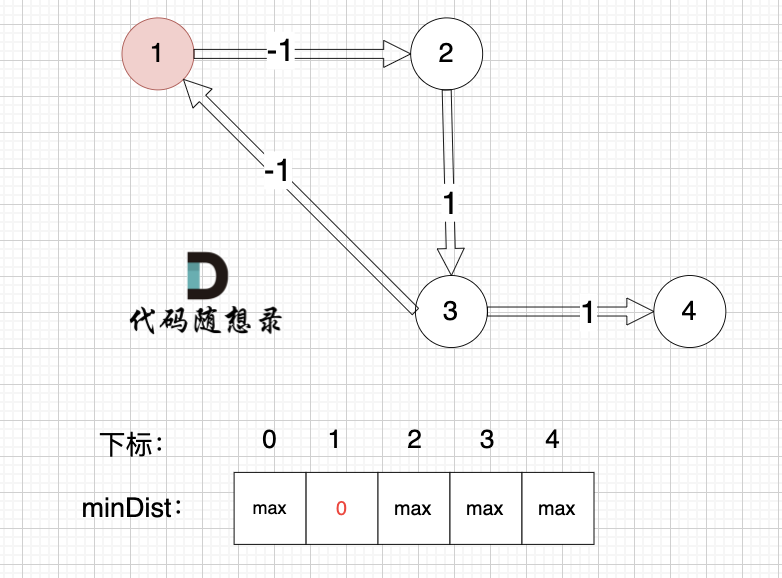
|
||||
|
||||
边:节点3 -> 节点1,权值为-1 ,节点3还没有被计算过,节点1 不更新。
|
||||
|
||||
边:节点3 -> 节点4,权值为1 ,节点3还没有被计算过,节点4 不更新。
|
||||
|
||||
边:节点2 -> 节点3,权值为 1 ,节点2还没有被计算过,节点3 不更新。
|
||||
|
||||
边:节点1 -> 节点2,权值为 -1 ,minDist[2] > minDist[1] + (-1),更新 minDist[2] = 0 + (-1) = -1 ,如图:
|
||||
|
||||
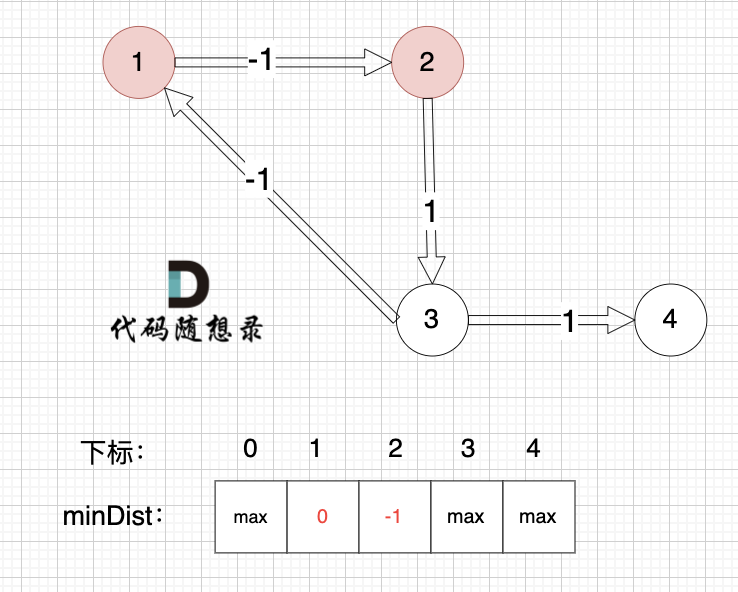
|
||||
|
||||
以上是对所有边 松弛一次的状态。
|
||||
|
||||
可以发现 同样的图,边的顺序不一样,使用版本一的代码 每次松弛更新的节点也是不一样的。
|
||||
|
||||
而边的顺序是随机的,是题目给我们的,所以本题我们才需要 记录上一次松弛的minDist,来保障 每一次对所有边松弛的结果。
|
||||
|
||||
|
||||
## 拓展二(本题本质)
|
||||
|
||||
那么前面讲解过的 [94.城市间货物运输I](./kama94.城市间货物运输I.md) 和 [95.城市间货物运输II](./kama95.城市间货物运输II.md) 也是bellman_ford经典算法,也没使用 minDist_copy,怎么就没问题呢?
|
||||
|
||||
> 如果没看过我上面这两篇讲解的话,建议详细学习上面两篇,再看我下面讲的区别,否则容易看不懂。
|
||||
|
||||
[94.城市间货物运输I](./kama94.城市间货物运输I.md), 是没有 负权回路的,那么 多松弛多少次,对结果都没有影响。
|
||||
|
||||
求 节点1 到 节点n 的最短路径,松弛n-1 次就够了,松弛 大于 n-1次,结果也不会变。
|
||||
|
||||
那么在对所有边进行第一次松弛的时候,如果基于 本次计算的 minDist 来计算 minDist (相当于多做松弛了),也是对最终结果没影响。
|
||||
|
||||
[95.城市间货物运输II](./kama95.城市间货物运输II.md) 是判断是否有 负权回路,一旦有负权回路, 对所有边松弛 n-1 次以后,在做松弛 minDist 数值一定会变,根据这一点来判断是否有负权回路。
|
||||
|
||||
所以,[95.城市间货物运输II](./kama95.城市间货物运输II.md) 只需要判断minDist数值变化了就行,而 minDist 的数值对不对,并不是我们关心的。
|
||||
|
||||
那么本题 为什么计算minDist 一定要基于上次 的 minDist 数值。
|
||||
|
||||
其关键在于本题的两个因素:
|
||||
|
||||
* 本题可以有负权回路,说明只要多做松弛,结果是会变的。
|
||||
* 本题要求最多经过k个节点,对松弛次数是有限制的。
|
||||
|
||||
如果本题中 没有负权回路的测试用例, 那版本一的代码就可以过了,也就不用我费这么大口舌去讲解的这个坑了。
|
||||
|
||||
## 拓展三(SPFA)
|
||||
|
||||
本题也可以用 SPFA来做,关于 SPFA ,已经在这里 [0094.城市间货物运输I-SPFA](./0094.城市间货物运输I-SPFA.md) 有详细讲解。
|
||||
|
||||
使用SPFA算法解决本题的时候,关键在于 如何控制松弛k次。
|
||||
|
||||
其实实现不难,但有点技巧,可以用一个变量 que_size 记录每一轮松弛入队列的所有节点数量。
|
||||
|
||||
下一轮松弛的时候,就把队列里 que_size 个节点都弹出来,就是上一轮松弛入队列的节点。
|
||||
|
||||
代码如下(详细注释)
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
struct Edge { //邻接表
|
||||
int to; // 链接的节点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<list<Edge>> grid(n + 1); // 邻接表
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1].push_back(Edge(p2, val));
|
||||
}
|
||||
int start, end, k;
|
||||
cin >> start >> end >> k;
|
||||
|
||||
k++;
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
vector<int> minDist_copy(n + 1); // 用来记录每一次遍历的结果
|
||||
|
||||
minDist[start] = 0;
|
||||
|
||||
queue<int> que;
|
||||
que.push(start); // 队列里放入起点
|
||||
|
||||
int que_size;
|
||||
while (k-- && !que.empty()) {
|
||||
|
||||
minDist_copy = minDist; // 获取上一次计算的结果
|
||||
que_size = que.size(); // 记录上次入队列的节点个数
|
||||
while (que_size--) { // 上一轮松弛入队列的节点,这次对应的边都要做松弛
|
||||
int node = que.front(); que.pop();
|
||||
for (Edge edge : grid[node]) {
|
||||
int from = node;
|
||||
int to = edge.to;
|
||||
int price = edge.val;
|
||||
if (minDist[to] > minDist_copy[from] + price) {
|
||||
minDist[to] = minDist_copy[from] + price;
|
||||
que.push(to);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
if (minDist[end] == INT_MAX) cout << "unreachable" << endl;
|
||||
else cout << minDist[end] << endl;
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
时间复杂度: O(K * H) H 为不确定数,取决于 图的稠密度,但H 一定是小于等于 E 的
|
||||
|
||||
关于 SPFA的是时间复杂度分析,我在[0094.城市间货物运输I-SPFA](./0094.城市间货物运输I-SPFA.md) 有详细讲解
|
||||
|
||||
但大家会发现,以上代码大家提交后,怎么耗时这么多?
|
||||
|
||||
|
||||
|
||||
理论上,SPFA的时间复杂度不是要比 bellman_ford 更优吗?
|
||||
|
||||
怎么耗时多了这么多呢?
|
||||
|
||||
以上代码有一个可以改进的点,每一轮松弛中,重复节点可以不用入队列。
|
||||
|
||||
因为重复节点入队列,下次从队列里取节点的时候,该节点要取很多次,而且都是重复计算。
|
||||
|
||||
所以代码可以优化成这样:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <list>
|
||||
#include <climits>
|
||||
using namespace std;
|
||||
|
||||
struct Edge { //邻接表
|
||||
int to; // 链接的节点
|
||||
int val; // 边的权重
|
||||
|
||||
Edge(int t, int w): to(t), val(w) {} // 构造函数
|
||||
};
|
||||
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<list<Edge>> grid(n + 1); // 邻接表
|
||||
|
||||
// 将所有边保存起来
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
// p1 指向 p2,权值为 val
|
||||
grid[p1].push_back(Edge(p2, val));
|
||||
}
|
||||
int start, end, k;
|
||||
cin >> start >> end >> k;
|
||||
|
||||
k++;
|
||||
|
||||
vector<int> minDist(n + 1 , INT_MAX);
|
||||
vector<int> minDist_copy(n + 1); // 用来记录每一次遍历的结果
|
||||
|
||||
minDist[start] = 0;
|
||||
|
||||
queue<int> que;
|
||||
que.push(start); // 队列里放入起点
|
||||
|
||||
int que_size;
|
||||
while (k-- && !que.empty()) {
|
||||
|
||||
vector<bool> visited(n + 1, false); // 每一轮松弛中,控制节点不用重复入队列
|
||||
minDist_copy = minDist;
|
||||
que_size = que.size();
|
||||
while (que_size--) {
|
||||
int node = que.front(); que.pop();
|
||||
for (Edge edge : grid[node]) {
|
||||
int from = node;
|
||||
int to = edge.to;
|
||||
int price = edge.val;
|
||||
if (minDist[to] > minDist_copy[from] + price) {
|
||||
minDist[to] = minDist_copy[from] + price;
|
||||
if(visited[to]) continue; // 不用重复放入队列,但需要重复松弛,所以放在这里位置
|
||||
visited[to] = true;
|
||||
que.push(to);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
if (minDist[end] == INT_MAX) cout << "unreachable" << endl;
|
||||
else cout << minDist[end] << endl;
|
||||
}
|
||||
```
|
||||
|
||||
以上代码提交后,耗时情况:
|
||||
|
||||
|
||||
|
||||
大家发现 依然远比 bellman_ford 的代码版本 耗时高。
|
||||
|
||||
这又是为什么呢?
|
||||
|
||||
可以发现耗时主要是在 第8组数据上:
|
||||
|
||||

|
||||
|
||||
其实第八组数据是我特别制作的一个 稠密大图,该图有250个节点和10000条边, 在这种情况下, SPFA 的时间复杂度 是接近与 bellman_ford的。
|
||||
|
||||
但因为 SPFA 节点的进出队列操作,耗时很大,所以相同的时间复杂度的情况下,SPFA 实际上更耗时了。
|
||||
|
||||
这一点我在 [0094.城市间货物运输I-SPFA](./0094.城市间货物运输I-SPFA.md) 有分析,感兴趣的录友再回头去看看。
|
||||
|
||||
## 总结
|
||||
|
||||
本题是单源有限最短路问题,也是 bellman_ford的一个拓展问题,如果理解bellman_ford 其实思路比较容易理解,但有很多细节。
|
||||
|
||||
例如 为什么要用 minDist_copy 来记录上一轮 松弛的结果。 这也是本篇我为什么花了这么大篇幅讲解的关键所在。
|
||||
|
||||
接下来,还给大家多了三个拓展:
|
||||
|
||||
* 边的顺序的影响
|
||||
* 本题的本质
|
||||
* SPFA的解法
|
||||
|
||||
学透了以上三个拓展,相信大家会对bellman_ford有更深入的理解。
|
||||
367
problems/kamacoder/0097.小明逛公园.md
Normal file
367
problems/kamacoder/0097.小明逛公园.md
Normal file
@@ -0,0 +1,367 @@
|
||||
|
||||
# Floyd 算法精讲
|
||||
|
||||
[卡码网:97. 小明逛公园](https://kamacoder.com/problempage.php?pid=1155)
|
||||
|
||||
【题目描述】
|
||||
|
||||
小明喜欢去公园散步,公园内布置了许多的景点,相互之间通过小路连接,小明希望在观看景点的同时,能够节省体力,走最短的路径。
|
||||
|
||||
|
||||
给定一个公园景点图,图中有 N 个景点(编号为 1 到 N),以及 M 条双向道路连接着这些景点。每条道路上行走的距离都是已知的。
|
||||
|
||||
|
||||
小明有 Q 个观景计划,每个计划都有一个起点 start 和一个终点 end,表示他想从景点 start 前往景点 end。由于小明希望节省体力,他想知道每个观景计划中从起点到终点的最短路径长度。 请你帮助小明计算出每个观景计划的最短路径长度。
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个整数 N, M, 分别表示景点的数量和道路的数量。
|
||||
|
||||
接下来的 M 行,每行包含三个整数 u, v, w,表示景点 u 和景点 v 之间有一条长度为 w 的双向道路。
|
||||
|
||||
接下里的一行包含一个整数 Q,表示观景计划的数量。
|
||||
|
||||
接下来的 Q 行,每行包含两个整数 start, end,表示一个观景计划的起点和终点。
|
||||
|
||||
【输出描述】
|
||||
|
||||
对于每个观景计划,输出一行表示从起点到终点的最短路径长度。如果两个景点之间不存在路径,则输出 -1。
|
||||
|
||||
【输入示例】
|
||||
|
||||
7 3
|
||||
1 2 4
|
||||
2 5 6
|
||||
3 6 8
|
||||
2
|
||||
1 2
|
||||
2 3
|
||||
|
||||
【输出示例】
|
||||
|
||||
4
|
||||
-1
|
||||
|
||||
【提示信息】
|
||||
|
||||
从 1 到 2 的路径长度为 4,2 到 3 之间并没有道路。
|
||||
|
||||
1 <= N, M, Q <= 1000.
|
||||
|
||||
## 思路
|
||||
|
||||
本题是经典的多源最短路问题。
|
||||
|
||||
在这之前我们讲解过,dijkstra朴素版、dijkstra堆优化、Bellman算法、Bellman队列优化(SPFA) 都是单源最短路,即只能有一个起点。
|
||||
|
||||
而本题是多源最短路,即 求多个起点到多个终点的多条最短路径。
|
||||
|
||||
通过本题,我们来系统讲解一个新的最短路算法-Floyd 算法。
|
||||
|
||||
Floyd 算法对边的权值正负没有要求,都可以处理。
|
||||
|
||||
Floyd算法核心思想是动态规划。
|
||||
|
||||
例如我们再求节点1 到 节点9 的最短距离,用二维数组来表示即:grid[1][9],如果最短距离是10 ,那就是 grid[1][9] = 10。
|
||||
|
||||
那 节点1 到 节点9 的最短距离 是不是可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成呢?
|
||||
|
||||
即 grid[1][9] = grid[1][5] + grid[5][9]
|
||||
|
||||
节点1 到节点5的最短距离 是不是可以有 节点1 到 节点3的最短距离 + 节点3 到 节点5 的最短距离组成呢?
|
||||
|
||||
即 grid[1][5] = grid[1][3] + grid[3][5]
|
||||
|
||||
以此类推,节点1 到 节点3的最短距离 可以由更小的区间组成。
|
||||
|
||||
那么这样我们是不是就找到了,子问题推导求出整体最优方案的递归关系呢。
|
||||
|
||||
而节点1 到 节点9 的最短距离 可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成, 也可以有 节点1 到节点7的最短距离 + 节点7 到节点9的最短距离的距离组成。
|
||||
|
||||
那么选哪个呢?
|
||||
|
||||
是不是 要选一个最小的,毕竟是求最短路。
|
||||
|
||||
此时我们已经接近明确递归公式了。
|
||||
|
||||
之前在讲解动态规划的时候,给出过动规五部曲:
|
||||
|
||||
* 确定dp数组(dp table)以及下标的含义
|
||||
* 确定递推公式
|
||||
* dp数组如何初始化
|
||||
* 确定遍历顺序
|
||||
* 举例推导dp数组
|
||||
|
||||
那么接下来我们还是用这五部来给大家讲解 Floyd。
|
||||
|
||||
1、确定dp数组(dp table)以及下标的含义
|
||||
|
||||
这里我们用 grid数组来存图,那就把dp数组命名为 grid。
|
||||
|
||||
grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点的最短距离为m。
|
||||
|
||||
可能有录友会想: 节点i 到 节点j 的最短距离为m,这句话可以理解,但 以[1...k]集合为中间节点 理解不辽。
|
||||
|
||||
节点i 到 节点j 的最短路径中 一定是经过很多节点,那么这个集合用[1...k] 来表示。
|
||||
|
||||
k不能单独指某个节点,因为谁说 节点i 到节点j的最短路径中 一定只有一个节点呢,所以k 一定要表示一个集合,即[1...k] ,表示节点1 到 节点k 一共k个节点的集合。
|
||||
|
||||
|
||||
2、确定递推公式
|
||||
|
||||
在上面的分析中我们已经初步感受到了递推的关系。
|
||||
|
||||
我们分两种情况:
|
||||
|
||||
1. 节点i 到 节点j 的最短路径经过节点k
|
||||
2. 节点i 到 节点j 的最短路径不经过节点k
|
||||
|
||||
对于第一种情况,`grid[i][j][k] = grid[i][k][k - 1] + grid[k][j][k - 1]`
|
||||
|
||||
节点i 到 节点k 的最短距离 是不经过节点k,中间节点集合为[1...k-1],所以 表示为`grid[i][k][k - 1]`
|
||||
|
||||
节点k 到 节点j 的最短距离 也是不经过节点k,中间节点集合为[1...k-1],所以表示为 `grid[k][j][k - 1]`
|
||||
|
||||
第二种情况,`grid[i][j][k] = grid[i][j][k - 1]`
|
||||
|
||||
如果节点i 到 节点j的最短距离 不经过节点k,那么 中间节点集合[1...k-1],表示为 `grid[i][j][k - 1]`
|
||||
|
||||
因为我们是求最短路,对于这两种情况自然是取最小值。
|
||||
|
||||
即: `grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])`
|
||||
|
||||
|
||||
3、dp数组如何初始化
|
||||
|
||||
grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点的最短距离为m。
|
||||
|
||||
刚开始初始化k 是不确定的。
|
||||
|
||||
例如题目中只是输入边(节点2 -> 节点6,权值为3),那么grid[2][6][k] = 3,k需要填什么呢?
|
||||
|
||||
把k 填成1,那如何上来就知道 节点2 经过节点1 到达节点6的最短距离是3 呢。
|
||||
|
||||
所以 只能 把k 赋值为 0,本题 节点0 是无意义的,节点是从1 到 n。
|
||||
|
||||
这样我们在下一轮计算的时候,就可以根据 grid[i][j][0] 来计算 grid[i][j][1],此时的 grid[i][j][1] 就是 节点i 经过节点1 到达 节点j 的最小距离了。
|
||||
|
||||
|
||||
|
||||
|
||||
**初始化这里要画图,对后面的遍历顺序理解很重要**
|
||||
|
||||
所以初始化:
|
||||
|
||||
```CPP
|
||||
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // C++定义了一个三位数组,10005是因为边的最大距离是10^4
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2][0] = val;
|
||||
grid[p2][p1][0] = val; // 注意这里是双向图
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
grid数组中其他元素数值应该初始化多少呢?
|
||||
|
||||
本题求的是最小值,所以输入数据没有涉及到的节点的情况都应该初始为一个最大数。
|
||||
|
||||
这样才不会影响,每次计算去最小值的时候,初始值对计算结果的影响。
|
||||
|
||||
所以grid数组的定义可以是:
|
||||
|
||||
```CPP
|
||||
// C++写法,定义了一个三位数组,10005是因为边的最大距离是10^4
|
||||
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005)));
|
||||
|
||||
```
|
||||
|
||||
4、确定遍历顺序
|
||||
|
||||
从递推公式:`grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])` 可以看出,我们需要三个for循环,分别遍历i,j 和k
|
||||
|
||||
而 k 依赖于 k - 1, i 和j 的到 并不依赖与 i - 1 或者 j - 1 等等。
|
||||
|
||||
那么这三个for的嵌套顺序应该是什么样的呢?
|
||||
|
||||
我们来看初始化,我们是把 k =0 的 i 和j 对应的数值都初始化了,这样才能去计算 k = 1 的时候 i 和 j 对应的数值。
|
||||
|
||||
这就好比是一个三维坐标,i 和j 是平层,而k 是 垂直向上 的。
|
||||
|
||||
遍历的顺序是从底向上 一层一层去遍历。
|
||||
|
||||
所以遍历k 的for循环一定是在最外面,这样才能 水平方向一层一层去遍历。如图:
|
||||
|
||||
|
||||
|
||||
至于遍历 i 和 j 的话,for 循环的先后顺序无所谓。
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
for (int k = 1; k <= n; k++) {
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= n; j++) {
|
||||
grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
有录友可能想,难道 遍历k 放在最里层就不行吗?
|
||||
|
||||
k 放在最里层,代码是这样:
|
||||
|
||||
```CPP
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= n; j++) {
|
||||
for (int k = 1; k <= n; k++) {
|
||||
grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
此时就遍历了 j 与 k 形成一个平面,i 则是纵面,那遍历 就是这样的:
|
||||
|
||||
|
||||
|
||||
|
||||
而我们初始化,是 k 为0,然后 i 和 j 形成的平面做初始化,如果以 k 和 j 形成的平面去遍历,就造成了 递推公式 用不上上一轮计算的结果,从而导致结果不对(初始化的结果只能用上一部分,因为初始化是 i 与j 形成的平面)。
|
||||
|
||||
我再给大家举一个测试用例
|
||||
|
||||
```
|
||||
5 4
|
||||
1 2 10
|
||||
1 3 1
|
||||
3 4 1
|
||||
4 2 1
|
||||
1
|
||||
1 2
|
||||
```
|
||||
|
||||
就是图:
|
||||
|
||||
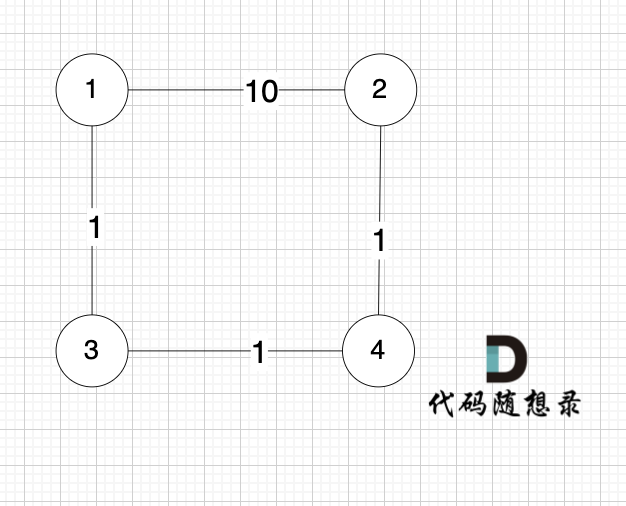
|
||||
|
||||
就节点1 到 节点 2 的最短距离,运行结果是 10 ,但正确的结果很明显是3。
|
||||
|
||||
为什么呢?
|
||||
|
||||
因为 k 放在最里面,先就把 节点1 和 节点 2 的最短距离就确定了,后面再也不会计算节点 1 和 节点 2的距离,同时也不会基于 初始化或者之前计算过的结果来计算,即不会考虑 节点1 到 节点3, 节点3 到节点 4,节点4到节点2 的距离。
|
||||
|
||||
|
||||
而遍历k 的for循环如果放在中间呢,同样是 j 与k 行程一个平面,i 是纵面,遍历的也是这样:
|
||||
|
||||

|
||||
|
||||
|
||||
同样不能完全用上初始化 和 上一层计算的结果。
|
||||
|
||||
很多录友对于 floyd算法的遍历顺序搞不懂,其实 是没有从三维的角度去思考,同时我把三维立体图给大家画出来,遍历顺序标出来,大家就很容易想明白,为什么 k 放在最外层 才能用上 初始化和上一轮计算的结果了。
|
||||
|
||||
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // 因为边的最大距离是10^4
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2][0] = val;
|
||||
grid[p2][p1][0] = val; // 注意这里是双向图
|
||||
|
||||
}
|
||||
// 开始 floyd
|
||||
for (int k = 1; k <= n; k++) {
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= n; j++) {
|
||||
grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);
|
||||
}
|
||||
}
|
||||
}
|
||||
// 输出结果
|
||||
int z, start, end;
|
||||
cin >> z;
|
||||
while (z--) {
|
||||
cin >> start >> end;
|
||||
if (grid[start][end][n] == 10005) cout << -1 << endl;
|
||||
else cout << grid[start][end][n] << endl;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
# 拓展 负权回路
|
||||
|
||||
本题可以有负数,但不能出现负权回路
|
||||
|
||||
---------
|
||||
|
||||
floyd n^3
|
||||
|
||||
同样多源汇最短路算法 Floyd 也是基于动态规划
|
||||
|
||||
Floyd 算法可以用来解决多源最短路径问题,它会计算图中每两个点之间的最短路径。
|
||||
|
||||
Floyd 算法对边权的正负没有限制要求(可处理正负权边的图),且能利用 Floyd 算法可能够对图中负环进行判定
|
||||
|
||||
LeetCode-1334. 阈值距离内邻居最少的城市
|
||||
|
||||
https://leetcode.cn/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/description/
|
||||
|
||||
-----------
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n, vector<int>(n, 10005)); // 因为边的最大距离是10^4
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
grid[p1][p2] = val;
|
||||
grid[p2][p1] = val; // 注意这里是双向图
|
||||
|
||||
}
|
||||
// 开始 floyd
|
||||
for (int p = 0; p < n; p++) {
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
grid[i][j] = min(grid[i][j], grid[i][p] + grid[p][j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
// 输出结果
|
||||
int z, start, end;
|
||||
cin >> z;
|
||||
while (z--) {
|
||||
cin >> start >> end;
|
||||
if (grid[start][end] == 10005) cout << -1 << endl;
|
||||
else cout << grid[start][end] << endl;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
Reference in New Issue
Block a user