替换图片链接
This commit is contained in:
@@ -5,15 +5,15 @@
|
||||
|
||||
平时大家在力扣上刷题,就是 核心代码模式,即给你一个函数,直接写函数实现,例如这样:
|
||||
|
||||
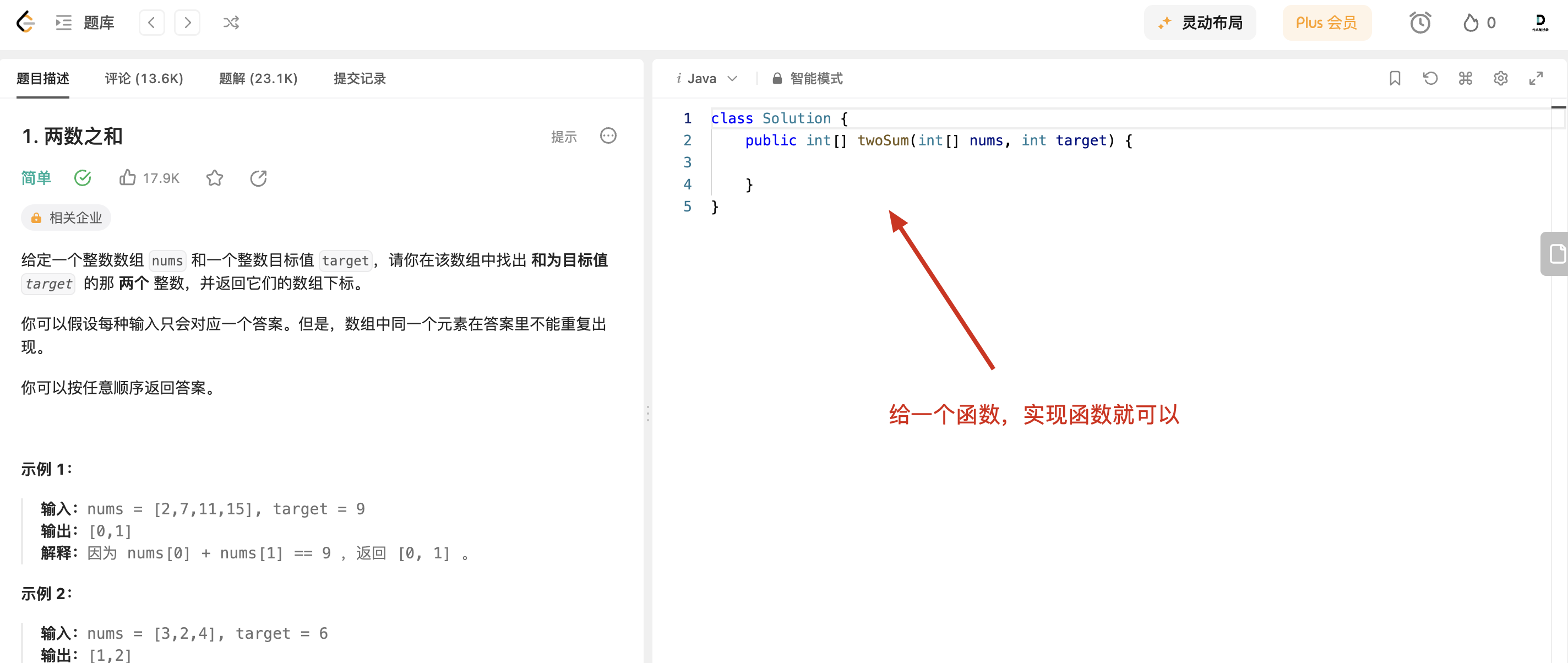
|
||||
|
||||
|
||||
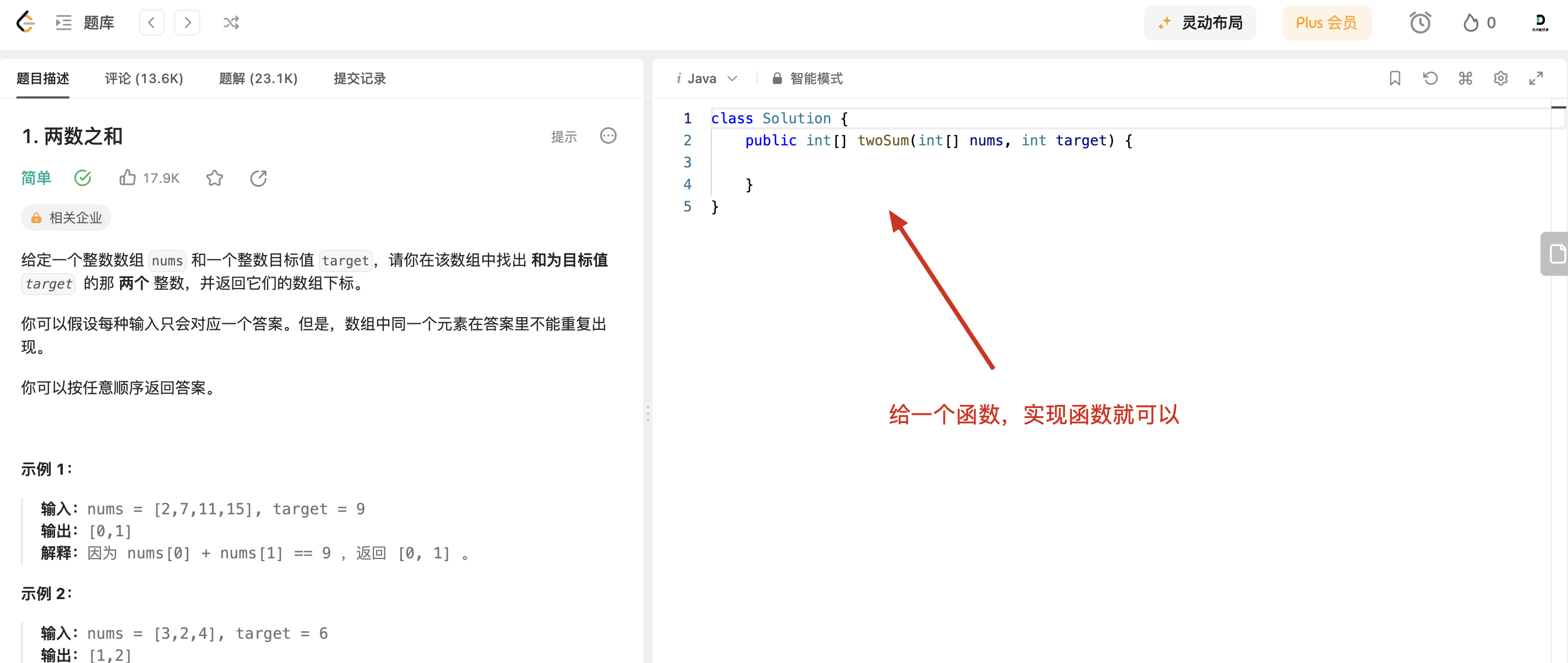
而ACM模式,是程序头文件,main函数,数据的输入输出都要自己处理,例如这样:
|
||||
|
||||
|
||||
|
||||
|
||||
大家可以发现 右边代码框什么都没有,程序从头到尾都需要自己实现,本题如果写完代码是这样的: (细心的录友可以发现和力扣上刷题是不一样的)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**如果大家从一开始学习算法就一直在力扣上的话,突然切到ACM模式会非常不适应**。
|
||||
@@ -21,15 +21,15 @@
|
||||
知识星球里也有很多录友,因为不熟悉ACM模式在面试的过程中吃了不少亏。
|
||||
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163624.png' width=500 alt=''></img></div>
|
||||
<div align="center"><img src='https://file.kamacoder.com/pics/20230727163624.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163938.png' width=500 alt=''></img></div>
|
||||
<div align="center"><img src='https://file.kamacoder.com/pics/20230727163938.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164042.png' width=500 alt=''></img></div>
|
||||
<div align="center"><img src='https://file.kamacoder.com/pics/20230727164042.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164151.png' width=500 alt=''></img></div>
|
||||
<div align="center"><img src='https://file.kamacoder.com/pics/20230727164151.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164459.png' width=500 alt=''></img></div>
|
||||
<div align="center"><img src='https://file.kamacoder.com/pics/20230727164459.png' width=500 alt=''></img></div>
|
||||
|
||||
## 面试究竟怎么考?
|
||||
|
||||
@@ -53,7 +53,7 @@
|
||||
|
||||
你只要能把卡码网首页的25道题目 都刷了 ,就把所有的ACM输入输出方式都练习到位了,不会有任何盲区。
|
||||
|
||||
|
||||
|
||||
|
||||
而且你不用担心,题目难度太大,直接给自己劝退,**卡码网的前25道题目都是我精心制作的,难度也是循序渐进的**,大家去刷一下就知道了。
|
||||
|
||||
|
||||
@@ -15,7 +15,7 @@
|
||||
|
||||
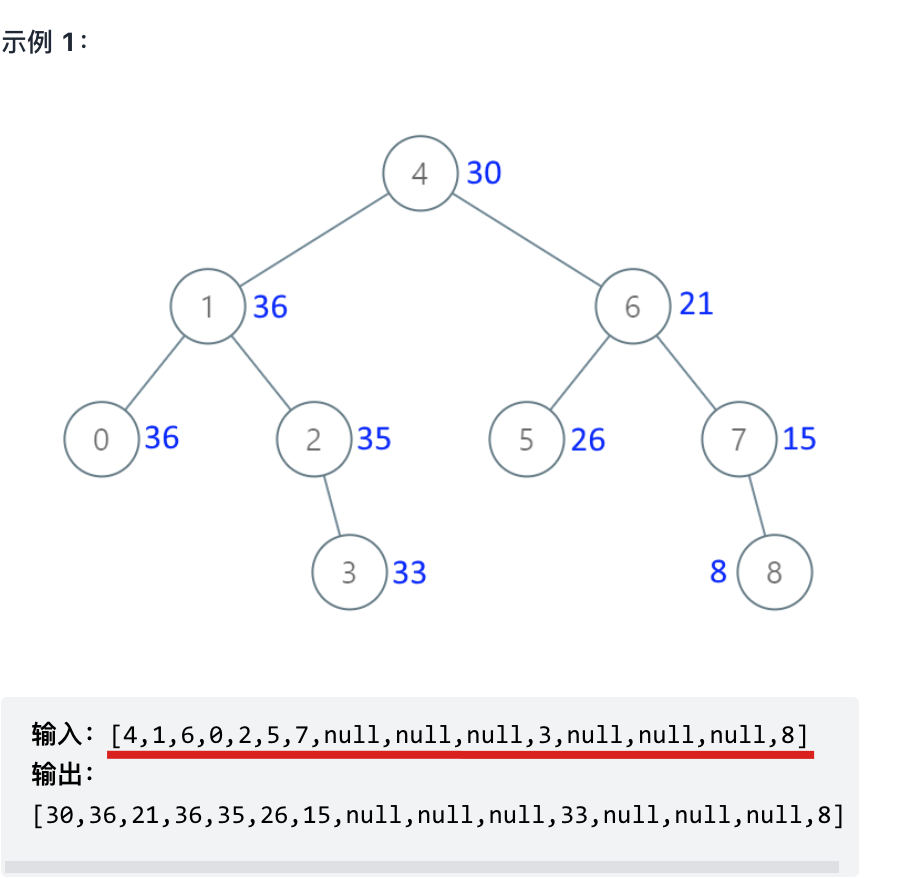
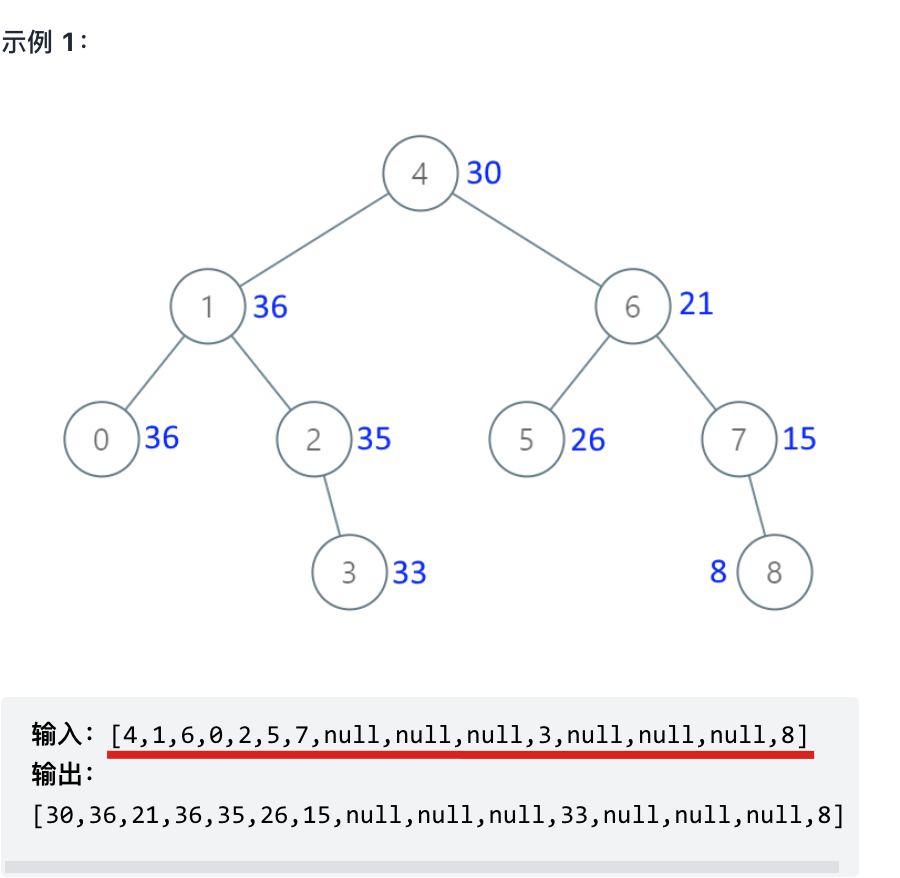
其输入用例,就是用一个数组来表述 二叉树,如下:
|
||||
|
||||
|
||||
|
||||
|
||||
一直跟着公众号学算法的录友 应该知道,我在[二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/Dza-fqjTyGrsRw4PWNKdxA),已经讲过,**只有 中序与后序 和 中序和前序 可以确定一棵唯一的二叉树。 前序和后序是不能确定唯一的二叉树的**。
|
||||
|
||||
@@ -24,7 +24,7 @@
|
||||
很明显,是后台直接明确了构造规则。
|
||||
|
||||
再看一下 这个 输入序列 和 对应的二叉树。
|
||||

|
||||

|
||||
|
||||
从二叉树 推导到 序列,大家可以发现这就是层序遍历。
|
||||
|
||||
@@ -36,7 +36,7 @@
|
||||
|
||||
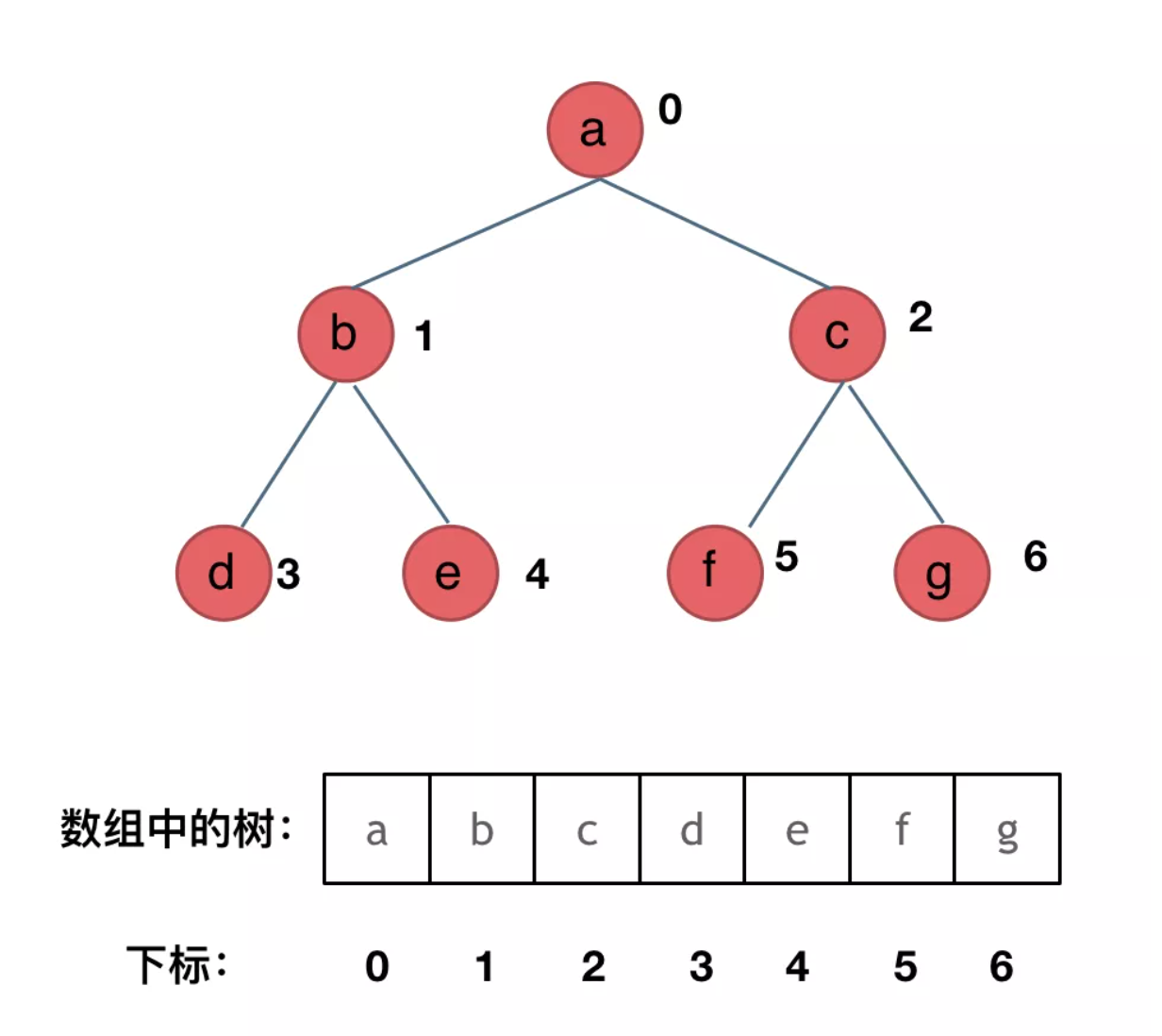
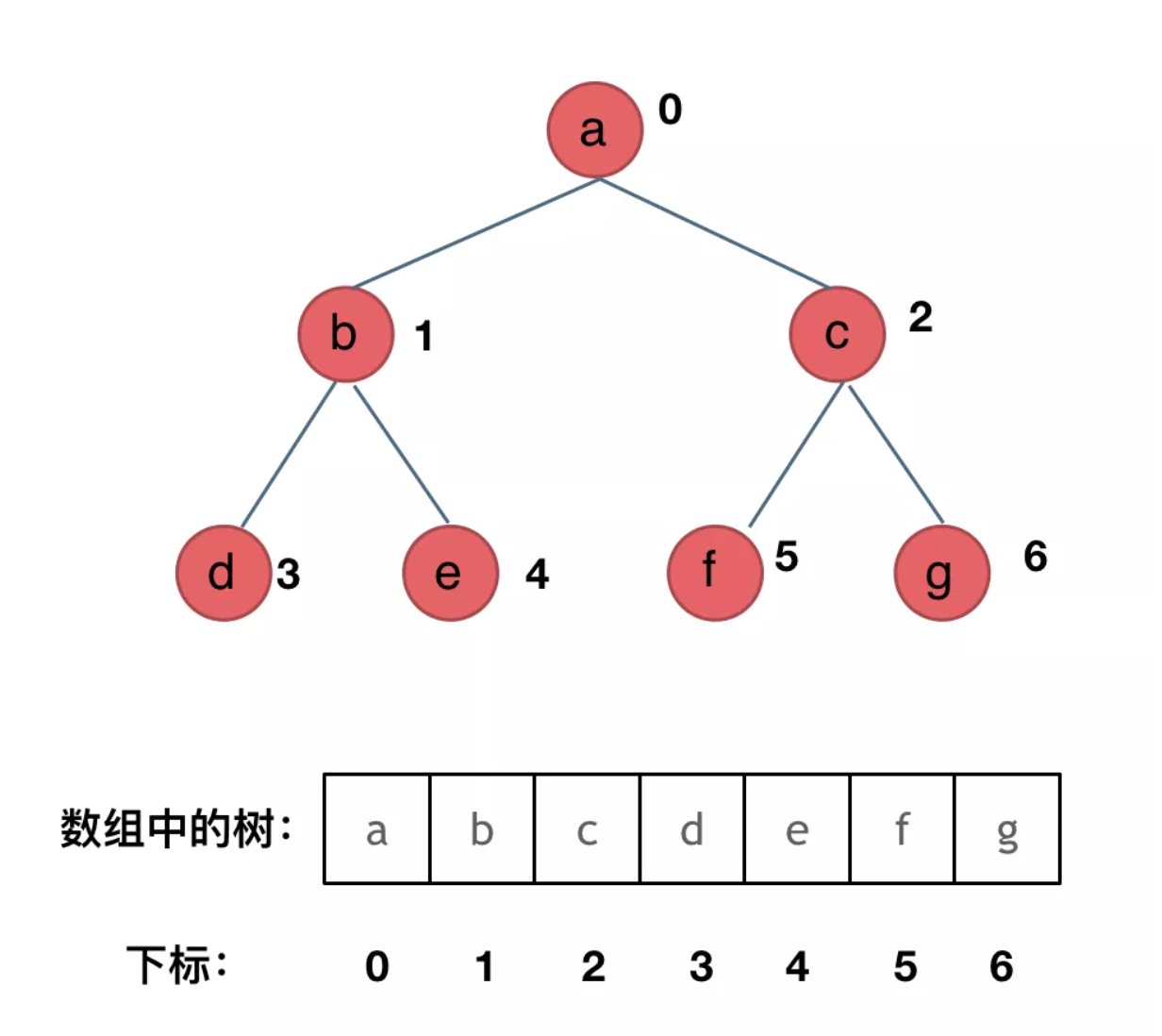
顺序存储,就是用一个数组来存二叉树,其方式如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
那么此时大家是不是应该知道了,数组如何转化成 二叉树了。**如果父节点的数组下标是i,那么它的左孩子下标就是i * 2 + 1,右孩子下标就是 i * 2 + 2**。
|
||||
|
||||
@@ -80,7 +80,7 @@ TreeNode* construct_binary_tree(const vector<int>& vec) {
|
||||
|
||||
这个函数最后返回的 指针就是 根节点的指针, 这就是 传入二叉树的格式了,也就是 力扣上的用例输入格式,如图:
|
||||
|
||||

|
||||

|
||||
|
||||
也有不少同学在做ACM模式的题目,就经常疑惑:
|
||||
|
||||
@@ -176,7 +176,7 @@ int main() {
|
||||
|
||||
和 [538.把二叉搜索树转换为累加树](https://mp.weixin.qq.com/s/rlJUFGCnXsIMX0Lg-fRpIw) 中的输入是一样的
|
||||
|
||||

|
||||

|
||||
|
||||
这里可能又有同学疑惑,你这不一样啊,题目是null,你为啥用-1。
|
||||
|
||||
@@ -184,11 +184,11 @@ int main() {
|
||||
|
||||
在来看,测试代码输出的效果:
|
||||
|
||||
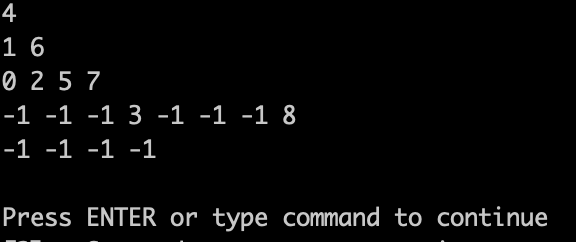
|
||||
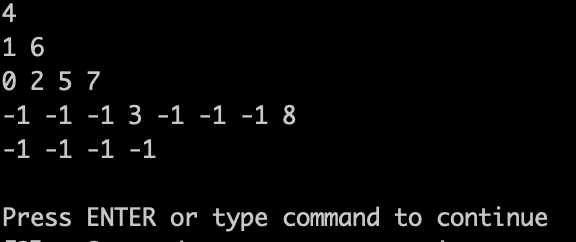
|
||||
|
||||
可以看出和 题目中输入用例 这个图 是一样一样的。 只不过题目中图没有把 空节点 画出来而已。
|
||||
|
||||
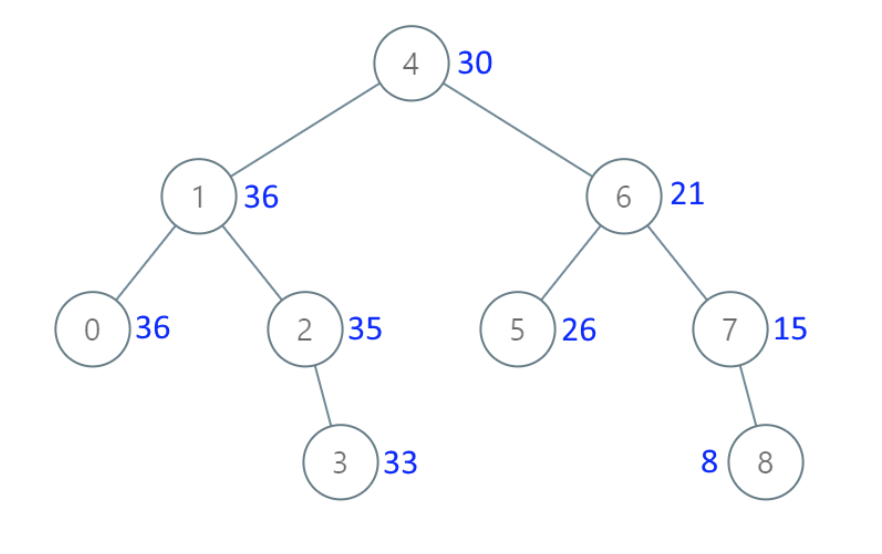
|
||||
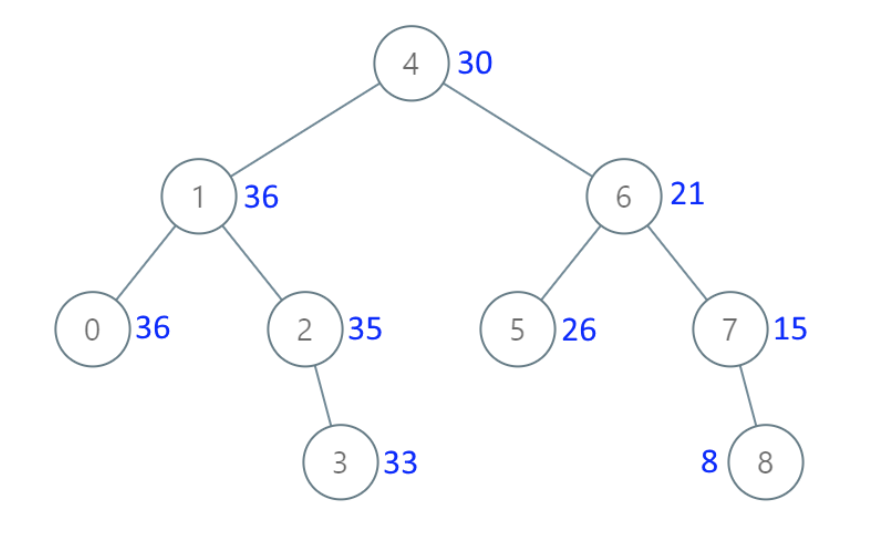
|
||||
|
||||
大家可以拿我的代码去测试一下,跑一跑。
|
||||
|
||||
@@ -205,7 +205,7 @@ int main() {
|
||||
|
||||
**[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)**里有的录友已经开始三刷:
|
||||
|
||||

|
||||

|
||||
|
||||
只做过一遍,真的就是懂了一点皮毛, 第二遍刷才有真的对各个题目有较为深入的理解,也会明白 我为什么要这样安排刷题的顺序了。
|
||||
|
||||
|
||||
@@ -93,7 +93,7 @@ sh install.sh
|
||||
|
||||
当然 还有很多,我还详细写了PowerVim的快捷键,使用方法,插件,配置,等等,都在Github主页的README上。当时我的Github上写的都是英文README,这次为了方便大家阅读,我又翻译成中文README。
|
||||
|
||||

|
||||

|
||||
|
||||
Github地址:[https://github.com/youngyangyang04/PowerVim](https://github.com/youngyangyang04/PowerVim)
|
||||
|
||||
|
||||
@@ -57,7 +57,7 @@
|
||||
|
||||
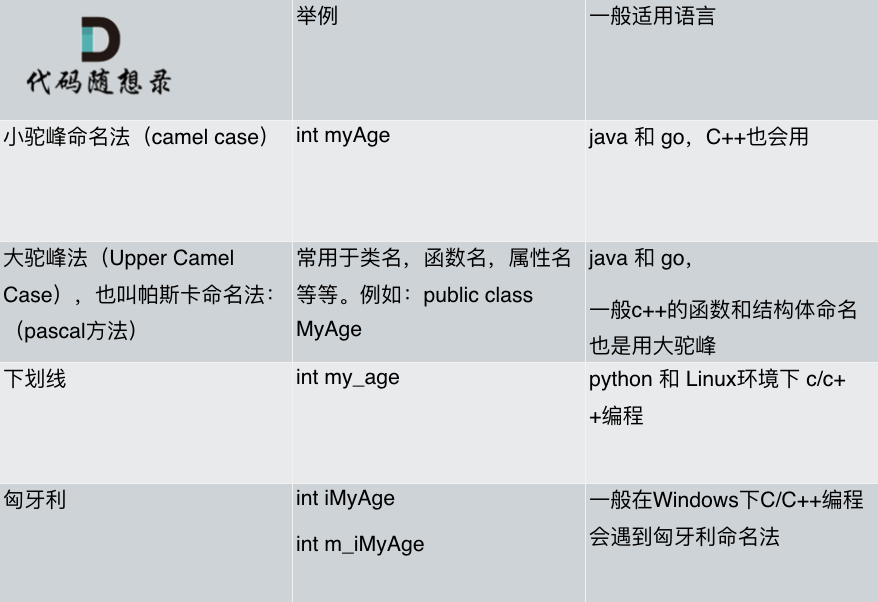
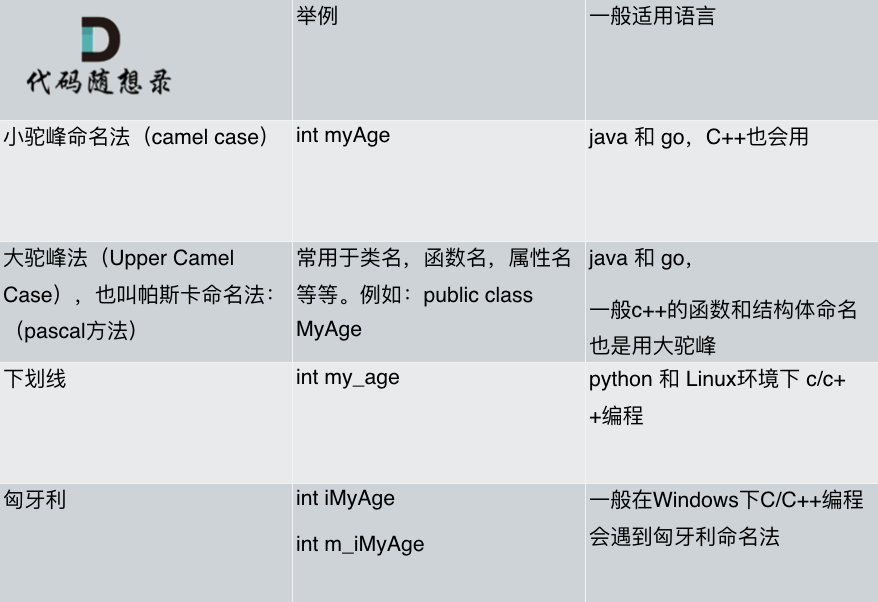
我做了一下总结如图:
|
||||
|
||||
|
||||
|
||||
|
||||
### 水平留白(代码空格)
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@
|
||||
|
||||
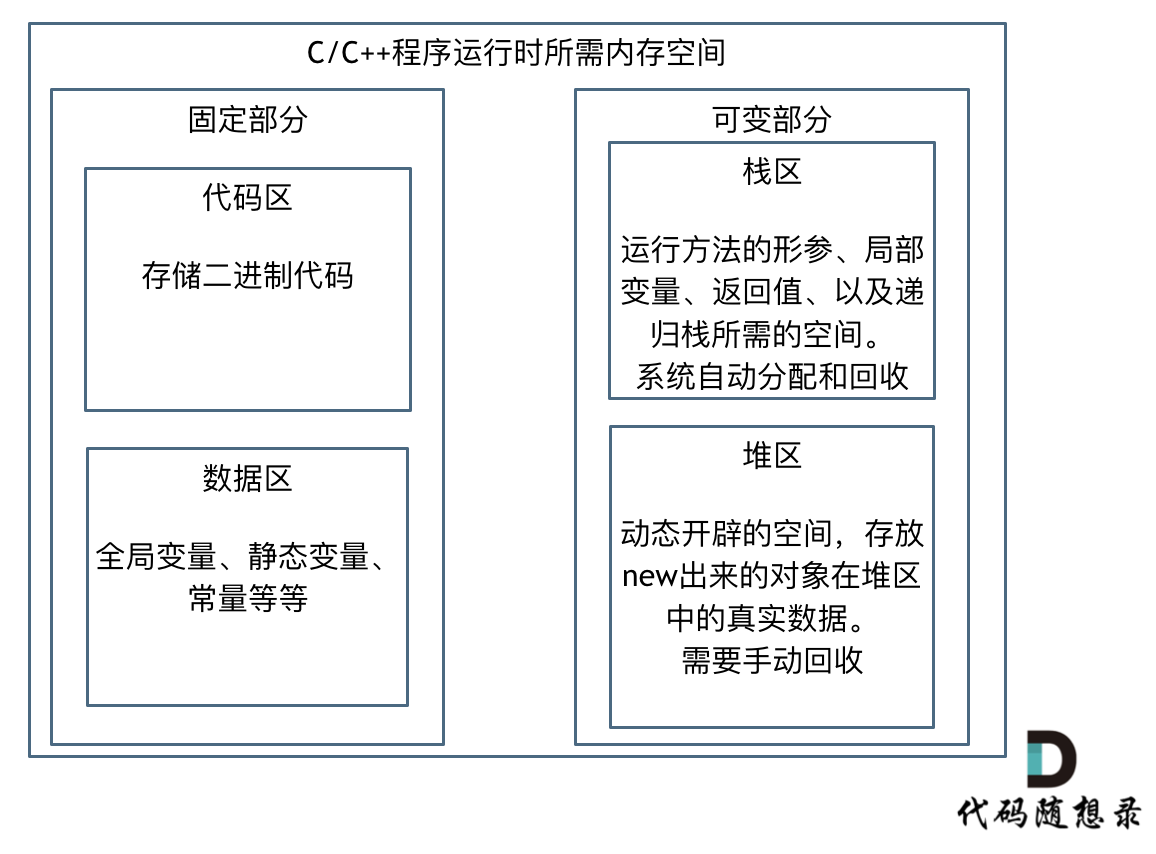
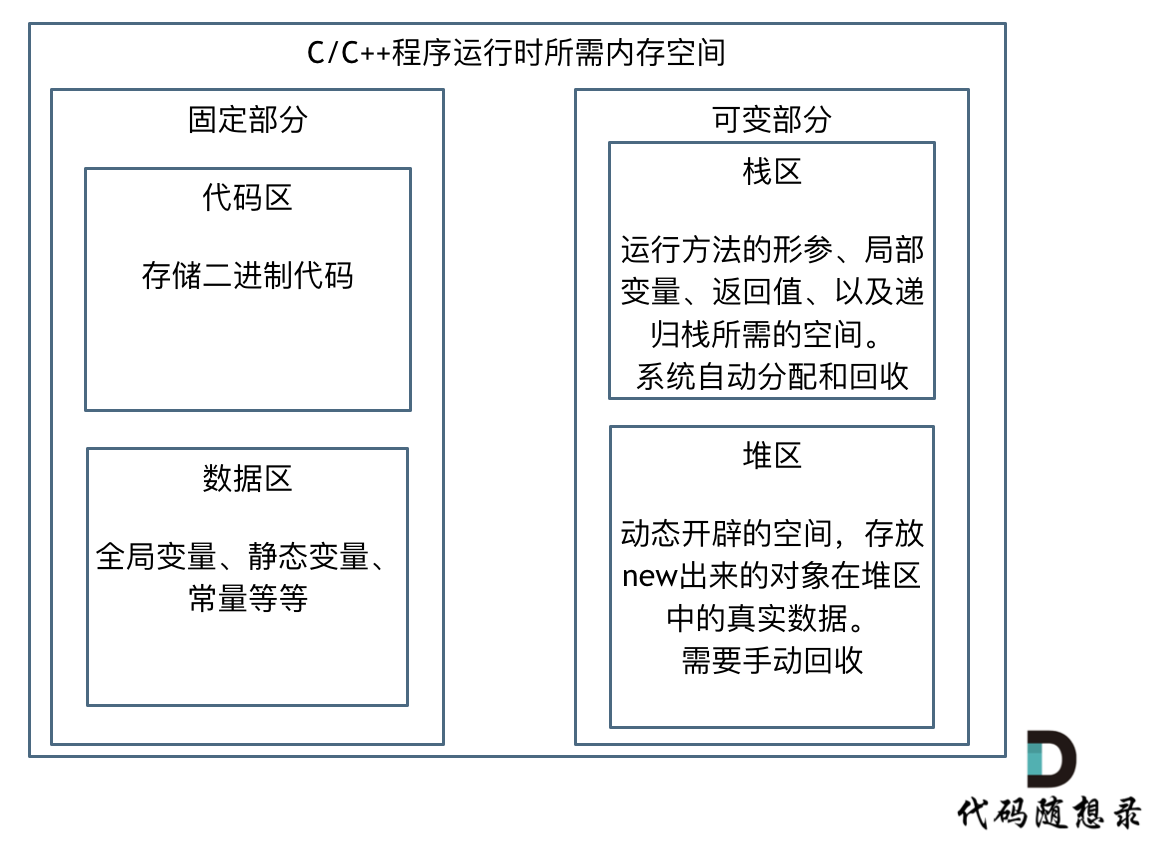
如果我们写C++的程序,就要知道栈和堆的概念,程序运行时所需的内存空间分为 固定部分,和可变部分,如下:
|
||||
|
||||
|
||||
|
||||
|
||||
固定部分的内存消耗 是不会随着代码运行产生变化的, 可变部分则是会产生变化的
|
||||
|
||||
@@ -41,7 +41,7 @@
|
||||
|
||||
想要算出自己程序会占用多少内存就一定要了解自己定义的数据类型的大小,如下:
|
||||
|
||||

|
||||

|
||||
|
||||
注意图中有两个不一样的地方,为什么64位的指针就占用了8个字节,而32位的指针占用4个字节呢?
|
||||
|
||||
@@ -109,7 +109,7 @@ CPU读取内存不是一次读取单个字节,而是一块一块的来读取
|
||||
|
||||
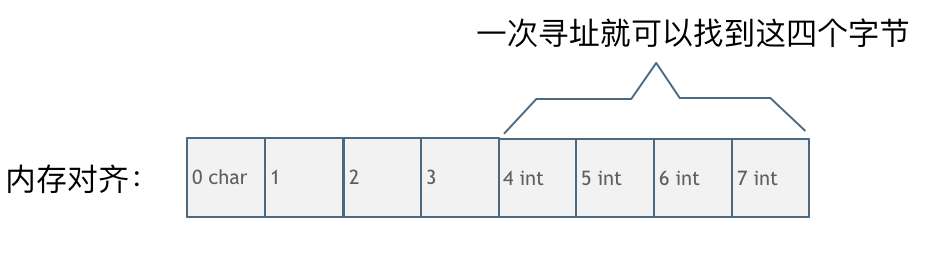
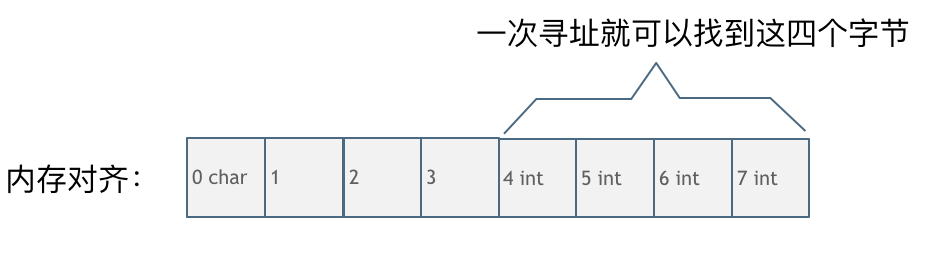
第一种就是内存对齐的情况,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
一字节的char占用了四个字节,空了三个字节的内存地址,int数据从地址4开始。
|
||||
|
||||
@@ -117,7 +117,7 @@ CPU读取内存不是一次读取单个字节,而是一块一块的来读取
|
||||
|
||||
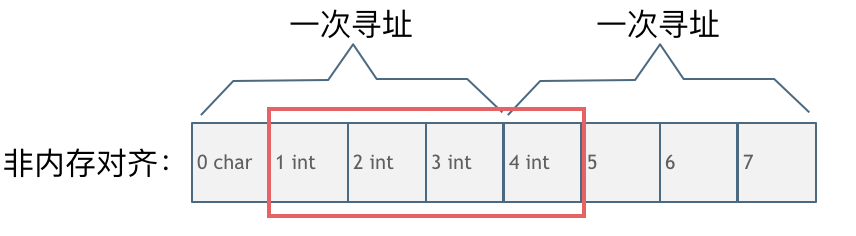
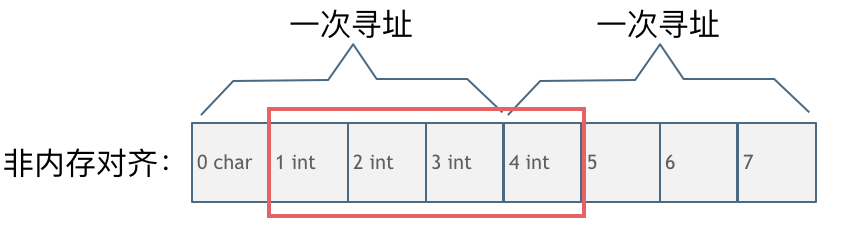
第二种是没有内存对齐的情况如图:
|
||||
|
||||
|
||||
|
||||
|
||||
char型的数据和int型的数据挨在一起,该int数据从地址1开始,那么CPU想要读这个数据的话来看看需要几步操作:
|
||||
|
||||
|
||||
@@ -38,7 +38,7 @@
|
||||
同样的同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)**。
|
||||
|
||||
**但是我们依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界**。如图所示:
|
||||

|
||||

|
||||
|
||||
我们主要关心的还是一般情况下的数据形式。
|
||||
|
||||
@@ -49,7 +49,7 @@
|
||||
|
||||
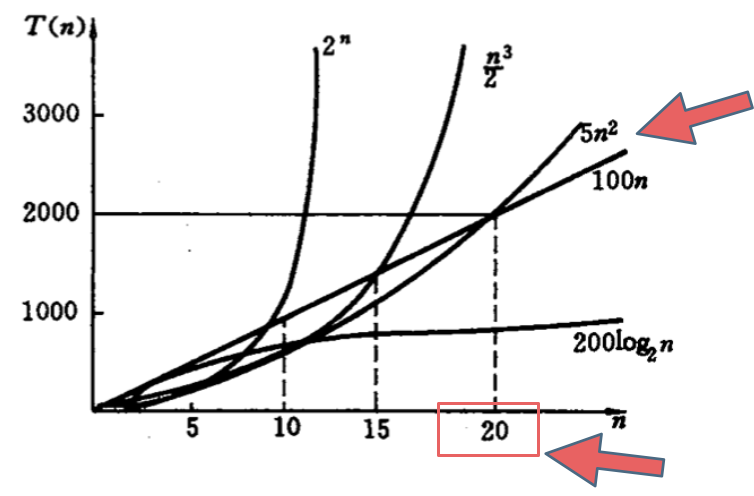
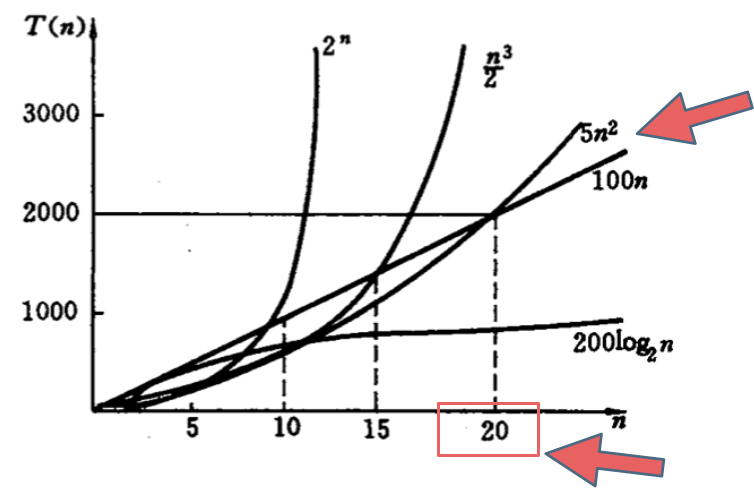
如下图中可以看出不同算法的时间复杂度在不同数据输入规模下的差异。
|
||||
|
||||
|
||||
|
||||
|
||||
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用O(n^2)的算法比O(n)的更合适(在有常数项的时候)。
|
||||
|
||||
@@ -115,7 +115,7 @@ O(2 × n^2 + 10 × n + 1000) < O(3 × n^2),所以说最后省略掉常数项
|
||||
|
||||
为什么可以这么做呢?如下图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
假如有两个算法的时间复杂度,分别是log以2为底n的对数和log以10为底n的对数,那么这里如果还记得高中数学的话,应该不难理解`以2为底n的对数 = 以2为底10的对数 * 以10为底n的对数`。
|
||||
|
||||
@@ -103,13 +103,13 @@ Carl校招社招都拿过大厂的offer,同时也看过很多应聘者的简
|
||||
|
||||
最后福利,把我的简历模板贡献出来!如下图所示。
|
||||
|
||||

|
||||

|
||||
|
||||
这里是简历模板中Markdown的代码:[https://github.com/youngyangyang04/Markdown-Resume-Template](https://github.com/youngyangyang04/Markdown-Resume-Template) ,可以fork到自己Github仓库上,按照这个模板来修改自己的简历。
|
||||
|
||||
**Word版本的简历,添加如下企业微信,通过之后就会发你word版本**。
|
||||
|
||||
<div align="center"><img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240328164645.png" data-img="1" width="200" height="200"></img></div>
|
||||
<div align="center"><img src="https://file.kamacoder.com/pics/20240328164645.png" data-img="1" width="200" height="200"></img></div>
|
||||
|
||||
如果已经有我的企业微信,直接回复:简历模板,就可以了。
|
||||
|
||||
|
||||
@@ -8,7 +8,7 @@
|
||||
|
||||
## 超时是怎么回事
|
||||
|
||||
|
||||
|
||||
|
||||
大家在leetcode上练习算法的时候应该都遇到过一种错误是“超时”。
|
||||
|
||||
@@ -124,11 +124,11 @@ int main() {
|
||||
|
||||
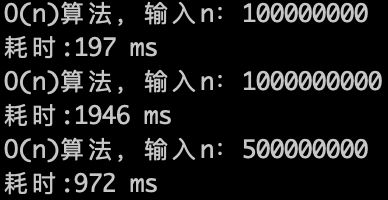
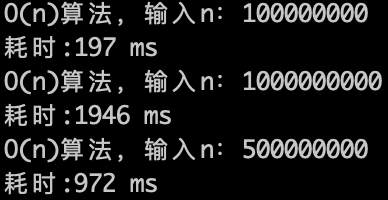
来看一下运行的效果,如下图:
|
||||
|
||||
|
||||
|
||||
|
||||
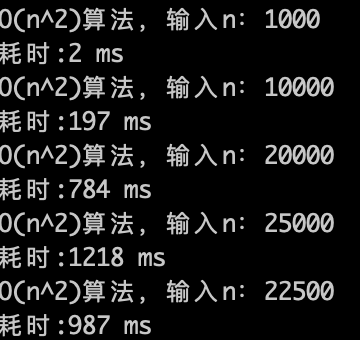
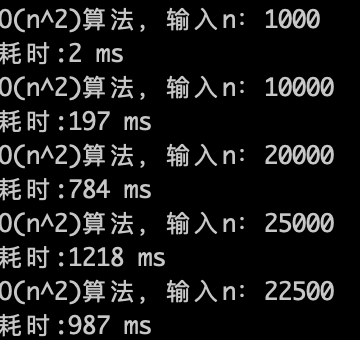
O(n)的算法,1s内大概计算机可以运行 5 * (10^8)次计算,可以推测一下 $O(n^2)$ 的算法应该1s可以处理的数量级的规模是 5 * (10^8)开根号,实验数据如下。
|
||||
|
||||
|
||||
|
||||
|
||||
O(n^2)的算法,1s内大概计算机可以运行 22500次计算,验证了刚刚的推测。
|
||||
|
||||
@@ -136,7 +136,7 @@ O(n^2)的算法,1s内大概计算机可以运行 22500次计算,验证了刚
|
||||
|
||||
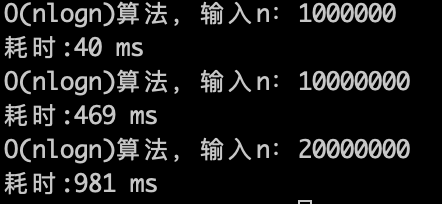
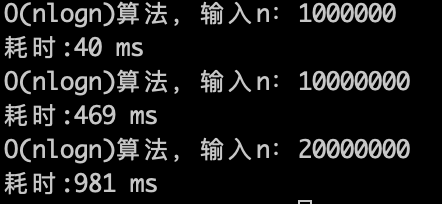
理论上应该是比 $O(n)$ 少一个数量级,因为 $\log n$ 的复杂度 其实是很快,看一下实验数据。
|
||||
|
||||
|
||||
|
||||
|
||||
$O(n\log n)$ 的算法,1s内大概计算机可以运行 2 * (10^7)次计算,符合预期。
|
||||
|
||||
@@ -144,7 +144,7 @@ $O(n\log n)$ 的算法,1s内大概计算机可以运行 2 * (10^7)次计算,
|
||||
|
||||
**整体测试数据整理如下:**
|
||||
|
||||

|
||||

|
||||
|
||||
至于 $O(\log n)$ 和 $O(n^3)$ 等等这些时间复杂度在1s内可以处理的多大的数据规模,大家可以自己写一写代码去测一下了。
|
||||
|
||||
|
||||
@@ -29,7 +29,7 @@ int fibonacci(int i) {
|
||||
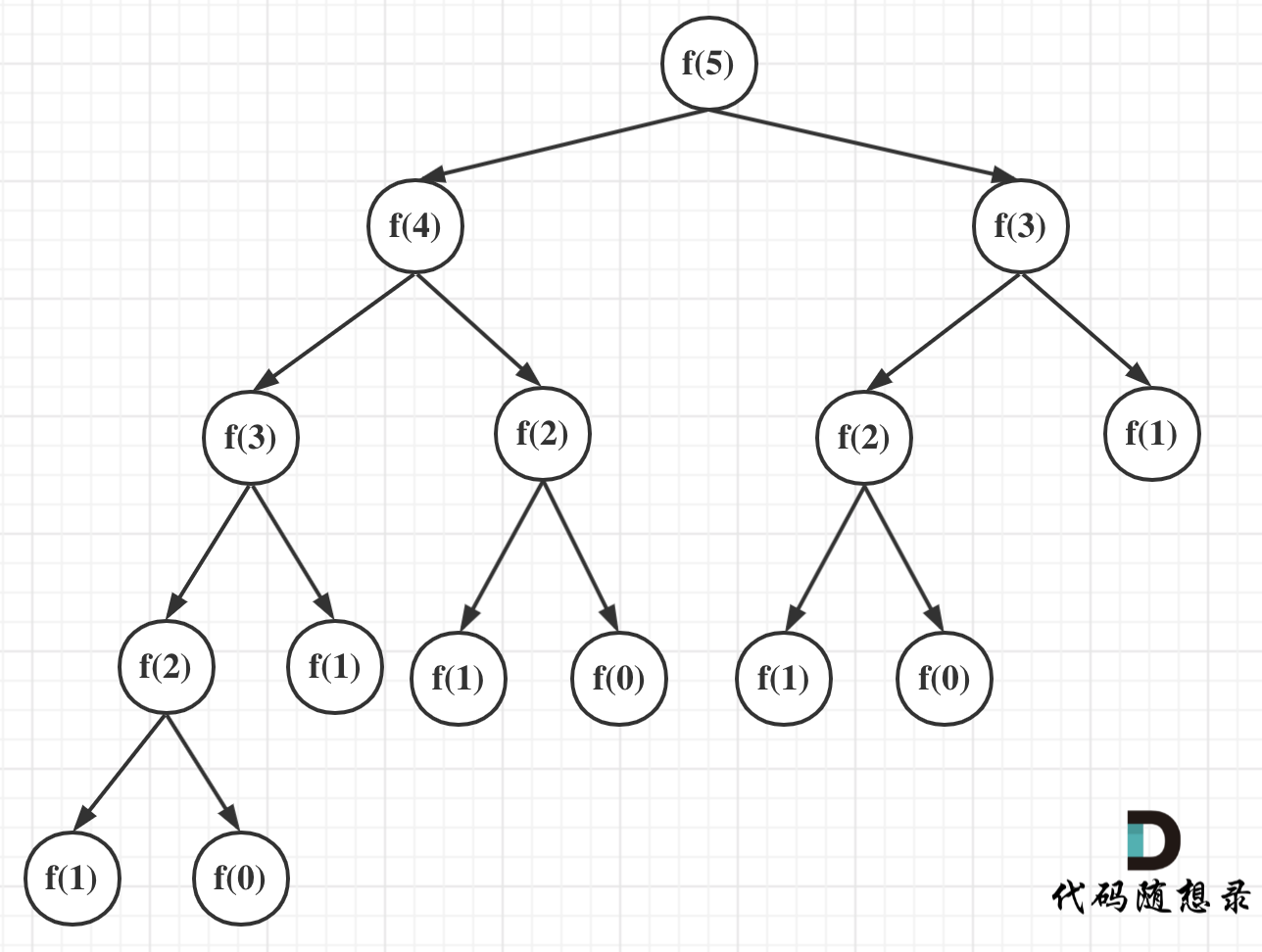
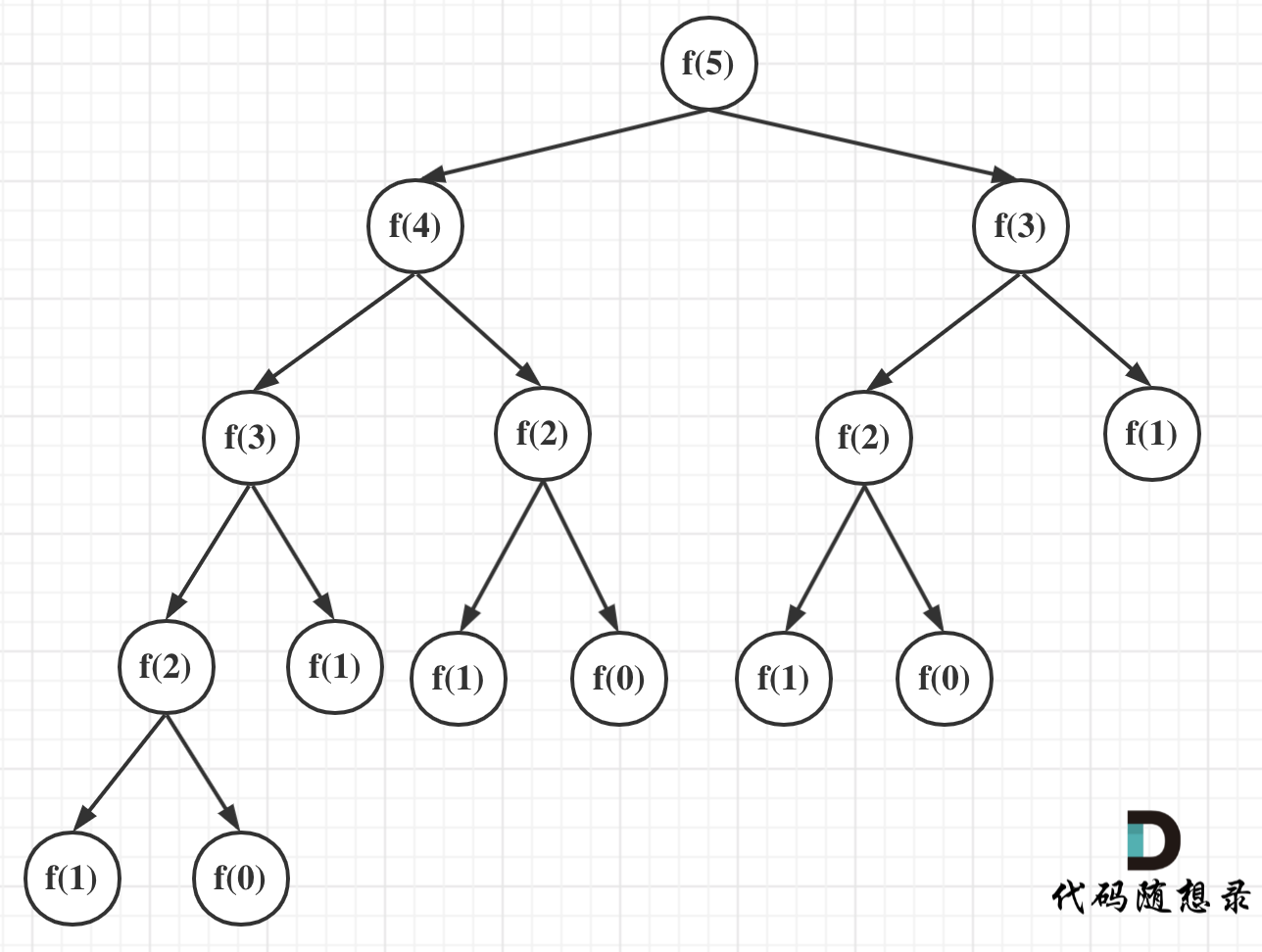
可以看出上面的代码每次递归都是O(1)的操作。再来看递归了多少次,这里将i为5作为输入的递归过程 抽象成一棵递归树,如图:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
从图中,可以看出f(5)是由f(4)和f(3)相加而来,那么f(4)是由f(3)和f(2)相加而来 以此类推。
|
||||
|
||||
@@ -196,7 +196,7 @@ int main()
|
||||
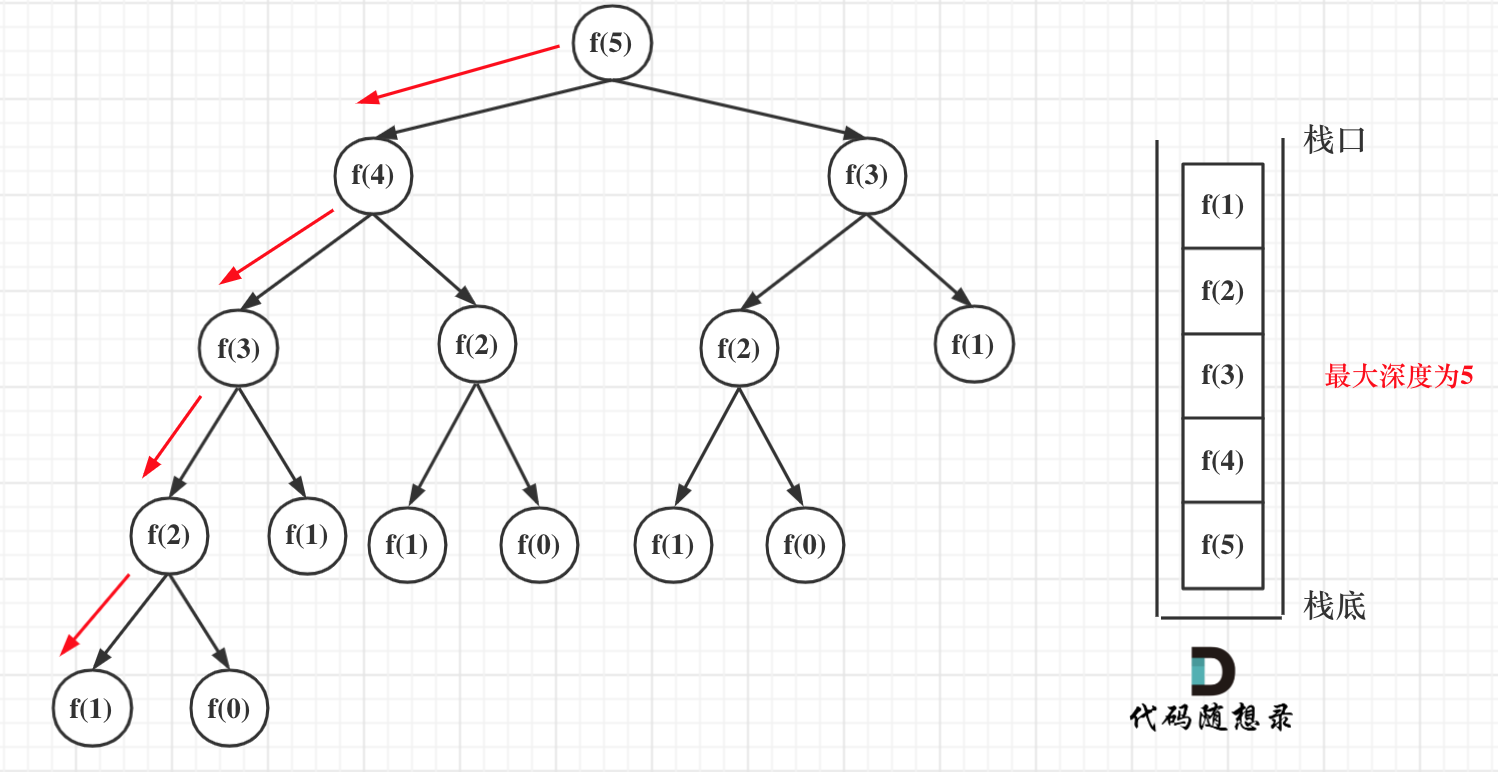
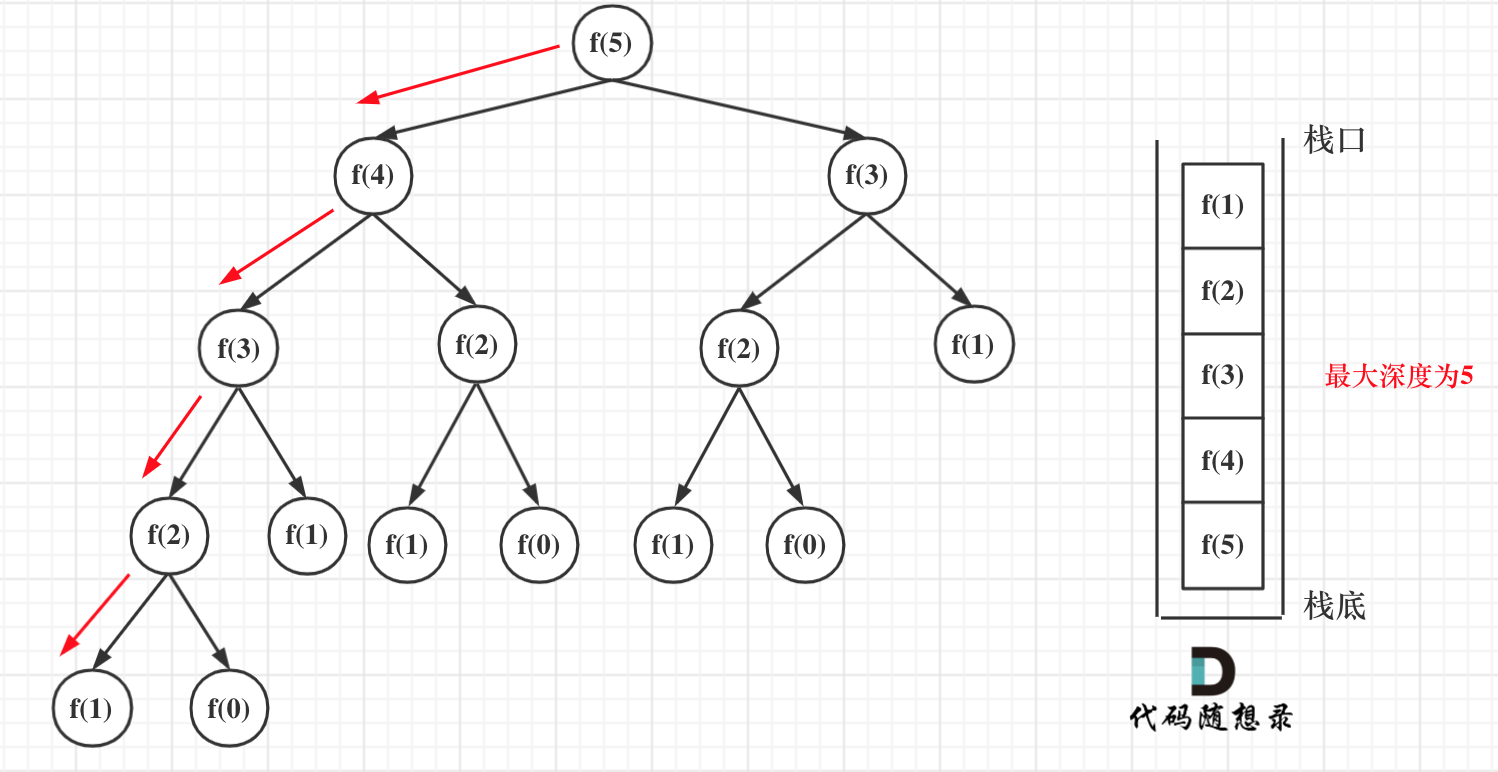
在看递归的深度是多少呢?如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
递归第n个斐波那契数的话,递归调用栈的深度就是n。
|
||||
|
||||
@@ -214,7 +214,7 @@ int fibonacci(int i) {
|
||||
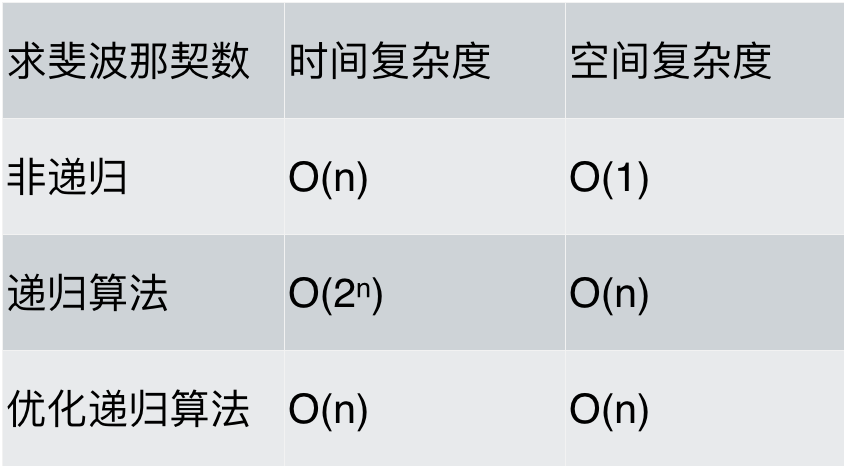
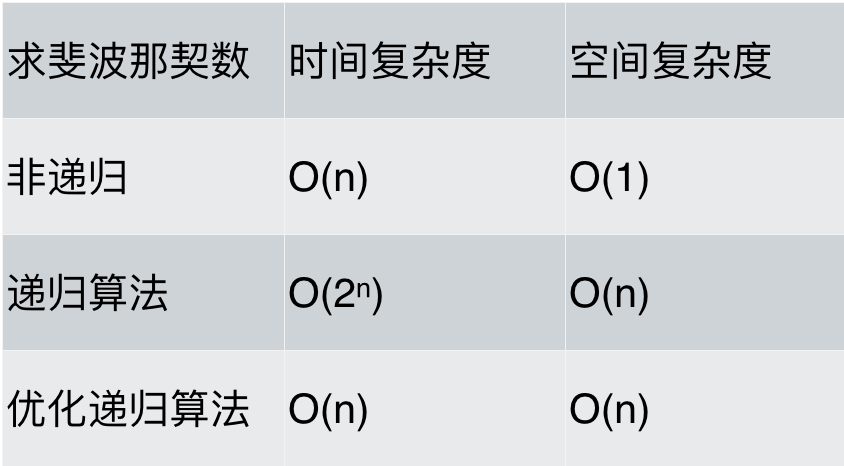
最后对各种求斐波那契数列方法的性能做一下分析,如题:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
可以看出,求斐波那契数的时候,使用递归算法并不一定是在性能上是最优的,但递归确实简化的代码层面的复杂度。
|
||||
|
||||
|
||||
@@ -69,7 +69,7 @@ int function3(int x, int n) {
|
||||
|
||||
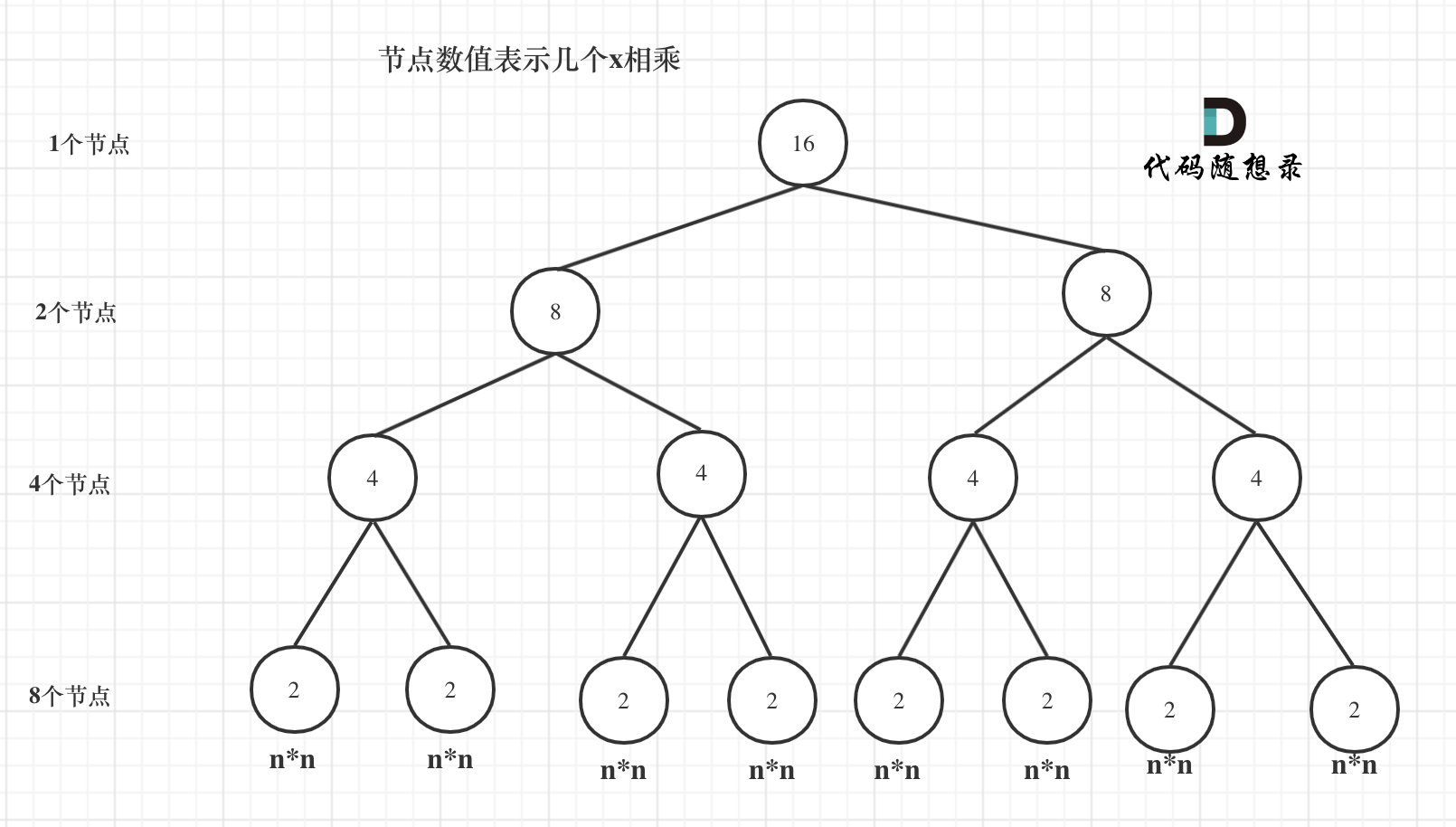
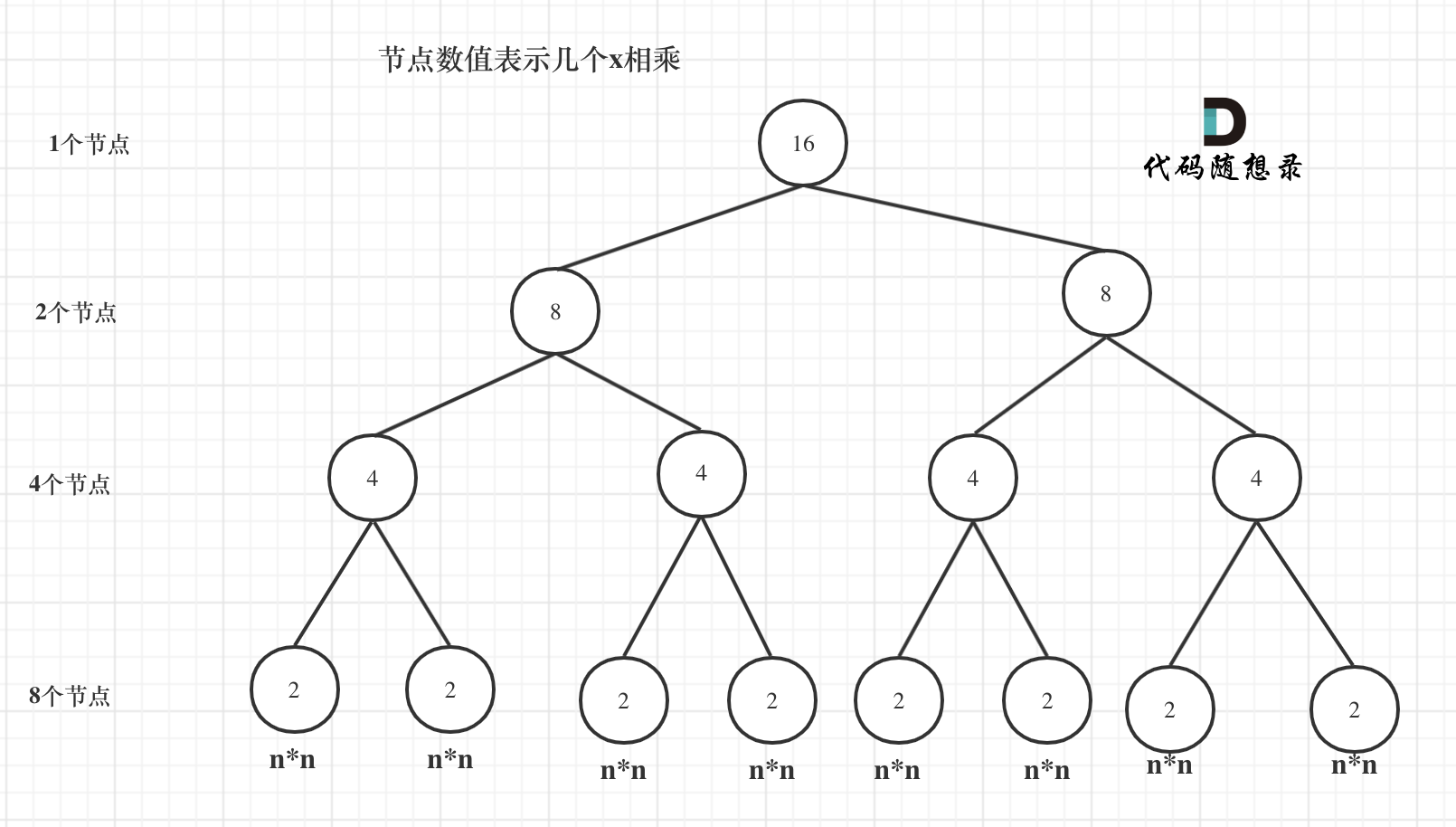
我们来分析一下,首先看递归了多少次呢,可以把递归抽象出一棵满二叉树。刚刚同学写的这个算法,可以用一棵满二叉树来表示(为了方便表示,选择n为偶数16),如图:
|
||||
|
||||
|
||||
|
||||
|
||||
当前这棵二叉树就是求x的n次方,n为16的情况,n为16的时候,进行了多少次乘法运算呢?
|
||||
|
||||
@@ -79,7 +79,7 @@ int function3(int x, int n) {
|
||||
|
||||
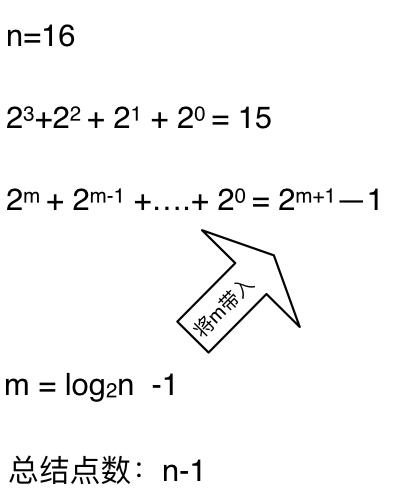
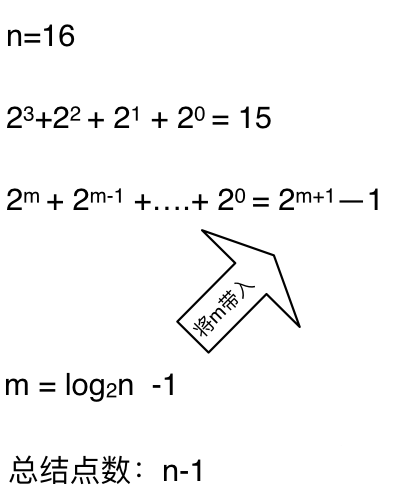
这么如果是求x的n次方,这个递归树有多少个节点呢,如下图所示:(m为深度,从0开始)
|
||||
|
||||
|
||||
|
||||
|
||||
**时间复杂度忽略掉常数项`-1`之后,这个递归算法的时间复杂度依然是O(n)**。对,你没看错,依然是O(n)的时间复杂度!
|
||||
|
||||
|
||||
Reference in New Issue
Block a user