Merge branch 'youngyangyang04:master' into master
This commit is contained in:
@@ -9,7 +9,7 @@
|
||||
* 什么是大O
|
||||
* 不同数据规模的差异
|
||||
* 复杂表达式的化简
|
||||
* $O(\log n)$中的log是以什么为底?
|
||||
* O(log n)中的log是以什么为底?
|
||||
* 举一个例子
|
||||
|
||||
|
||||
@@ -23,21 +23,21 @@
|
||||
|
||||
那么该如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
|
||||
|
||||
假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 $O(f(n)$)。
|
||||
假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
|
||||
|
||||
## 什么是大O
|
||||
|
||||
这里的大O是指什么呢,说到时间复杂度,**大家都知道$O(n)$,$O(n^2)$,却说不清什么是大O**。
|
||||
这里的大O是指什么呢,说到时间复杂度,**大家都知道O(n),O(n^2),却说不清什么是大O**。
|
||||
|
||||
算法导论给出的解释:**大O用来表示上界的**,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
|
||||
|
||||
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是$O(n^2)$ 。
|
||||
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是O(n^2) 。
|
||||
|
||||
输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是$O(n)$,但如果数据是逆序的话,插入排序的时间复杂度就是$O(n^2)$,也就对于所有输入情况来说,最坏是$O(n^2)$ 的时间复杂度,所以称插入排序的时间复杂度为$O(n^2)$。
|
||||
输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n^2),也就对于所有输入情况来说,最坏是O(n^2) 的时间复杂度,所以称插入排序的时间复杂度为O(n^2)。
|
||||
|
||||
同样的同理再看一下快速排序,都知道快速排序是$O(n\log n)$,但是当数据已经有序情况下,快速排序的时间复杂度是$O(n^2)$ 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是$O(n^2)$**。
|
||||
同样的同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)**。
|
||||
|
||||
**但是我们依然说快速排序是$O(n\log n)$的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界**。如图所示:
|
||||
**但是我们依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界**。如图所示:
|
||||

|
||||
|
||||
我们主要关心的还是一般情况下的数据形式。
|
||||
@@ -51,11 +51,11 @@
|
||||
|
||||
|
||||
|
||||
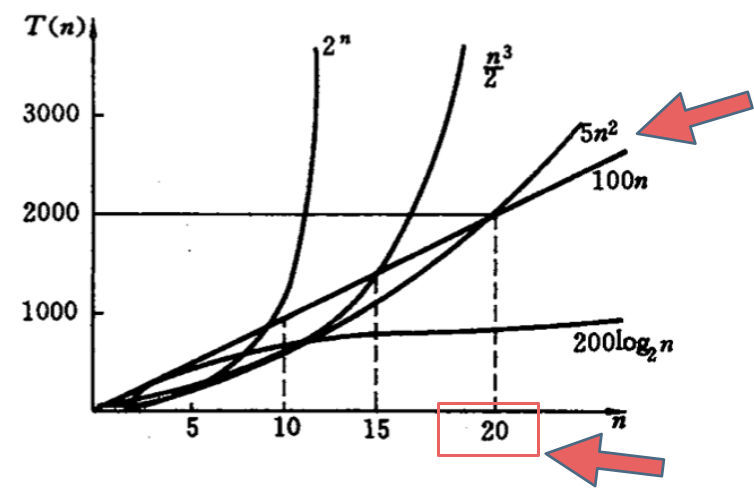
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用$O(n^2)$的算法比$O(n)$的更合适(在有常数项的时候)。
|
||||
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用O(n^2)的算法比O(n)的更合适(在有常数项的时候)。
|
||||
|
||||
就像上图中 $O(5n^2)$ 和 $O(100n)$ 在n为20之前 很明显 $O(5n^2)$是更优的,所花费的时间也是最少的。
|
||||
就像上图中 O(5n^2) 和 O(100n) 在n为20之前 很明显 O(5n^2)是更优的,所花费的时间也是最少的。
|
||||
|
||||
那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说$O(100n)$ 就是$O(n)$的时间复杂度,$O(5n^2)$ 就是$O(n^2)$的时间复杂度,而且要默认$O(n)$ 优于$O(n^2)$ 呢 ?
|
||||
那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说O(100n) 就是O(n)的时间复杂度,O(5n^2) 就是O(n^2)的时间复杂度,而且要默认O(n) 优于O(n^2) 呢 ?
|
||||
|
||||
这里就又涉及到大O的定义,**因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量**。
|
||||
|
||||
@@ -63,13 +63,13 @@
|
||||
|
||||
**所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示**:
|
||||
|
||||
O(1)常数阶 < $O(\log n)$对数阶 < $O(n)$线性阶 < $O(n^2)$平方阶 < $O(n^3)$立方阶 < $O(2^n)$指数阶
|
||||
O(1)常数阶 < O(logn)对数阶 < O(n)线性阶 < O(n^2)平方阶 < O(n^3)立方阶 < O(2^n)指数阶
|
||||
|
||||
但是也要注意大常数,如果这个常数非常大,例如10^7 ,10^9 ,那么常数就是不得不考虑的因素了。
|
||||
|
||||
## 复杂表达式的化简
|
||||
|
||||
有时候我们去计算时间复杂度的时候发现不是一个简单的$O(n)$ 或者$O(n^2)$, 而是一个复杂的表达式,例如:
|
||||
有时候我们去计算时间复杂度的时候发现不是一个简单的O(n) 或者O(n^2), 而是一个复杂的表达式,例如:
|
||||
|
||||
```
|
||||
O(2*n^2 + 10*n + 1000)
|
||||
@@ -95,19 +95,19 @@ O(n^2 + n)
|
||||
O(n^2)
|
||||
```
|
||||
|
||||
如果这一步理解有困难,那也可以做提取n的操作,变成$O(n(n+1)$) ,省略加法常数项后也就别变成了:
|
||||
如果这一步理解有困难,那也可以做提取n的操作,变成O(n(n+1)) ,省略加法常数项后也就别变成了:
|
||||
|
||||
```
|
||||
O(n^2)
|
||||
```
|
||||
|
||||
所以最后我们说:这个算法的算法时间复杂度是$O(n^2)$ 。
|
||||
所以最后我们说:这个算法的算法时间复杂度是O(n^2) 。
|
||||
|
||||
|
||||
也可以用另一种简化的思路,其实当n大于40的时候, 这个复杂度会恒小于$O(3 × n^2)$,
|
||||
$O(2 × n^2 + 10 × n + 1000) < O(3 × n^2)$,所以说最后省略掉常数项系数最终时间复杂度也是$O(n^2)$。
|
||||
也可以用另一种简化的思路,其实当n大于40的时候, 这个复杂度会恒小于O(3 × n^2),
|
||||
O(2 × n^2 + 10 × n + 1000) < O(3 × n^2),所以说最后省略掉常数项系数最终时间复杂度也是O(n^2)。
|
||||
|
||||
## $O(\log n)$中的log是以什么为底?
|
||||
## O(logn)中的log是以什么为底?
|
||||
|
||||
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
|
||||
|
||||
@@ -130,21 +130,21 @@ $O(2 × n^2 + 10 × n + 1000) < O(3 × n^2)$,所以说最后省略掉常数项
|
||||
|
||||
通过这道面试题目,来分析一下时间复杂度。题目描述:找出n个字符串中相同的两个字符串(假设这里只有两个相同的字符串)。
|
||||
|
||||
如果是暴力枚举的话,时间复杂度是多少呢,是$O(n^2)$么?
|
||||
如果是暴力枚举的话,时间复杂度是多少呢,是O(n^2)么?
|
||||
|
||||
这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了n^2 次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是$O(m × n × n)$。
|
||||
这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了n^2 次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是O(m × n × n)。
|
||||
|
||||
接下来再想一下其他解题思路。
|
||||
|
||||
先排对n个字符串按字典序来排序,排序后n个字符串就是有序的,意味着两个相同的字符串就是挨在一起,然后在遍历一遍n个字符串,这样就找到两个相同的字符串了。
|
||||
|
||||
那看看这种算法的时间复杂度,快速排序时间复杂度为$O(n\log n)$,依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是$O(m × n × \log n)$ 。
|
||||
那看看这种算法的时间复杂度,快速排序时间复杂度为O(nlogn),依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是O(m × n × log n) 。
|
||||
|
||||
之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 $O(m × n × \log n + n × m)$。
|
||||
之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 O(m × n × logn + n × m)。
|
||||
|
||||
我们对$O(m × n × \log n + n × m)$ 进行简化操作,把$m × n$提取出来变成 $O(m × n × (\log n + 1)$),再省略常数项最后的时间复杂度是 $O(m × n × \log n)$。
|
||||
我们对O(m × n × log n + n × m) 进行简化操作,把m × n提取出来变成 O(m × n × (logn + 1)),再省略常数项最后的时间复杂度是 O(m × n × log n)。
|
||||
|
||||
最后很明显$O(m × n × \log n)$ 要优于$O(m × n × n)$!
|
||||
最后很明显O(m × n × logn) 要优于O(m × n × n)!
|
||||
|
||||
所以先把字符串集合排序再遍历一遍找到两个相同字符串的方法要比直接暴力枚举的方式更快。
|
||||
|
||||
|
||||
@@ -3,14 +3,14 @@
|
||||
# 空间复杂度分析
|
||||
|
||||
* [关于时间复杂度,你不知道的都在这里!](https://programmercarl.com/前序/关于时间复杂度,你不知道的都在这里!.html)
|
||||
* [$O(n)$的算法居然超时了,此时的n究竟是多大?](https://programmercarl.com/前序/On的算法居然超时了,此时的n究竟是多大?.html)
|
||||
* [O(n)的算法居然超时了,此时的n究竟是多大?](https://programmercarl.com/前序/On的算法居然超时了,此时的n究竟是多大?.html)
|
||||
* [通过一道面试题目,讲一讲递归算法的时间复杂度!](https://programmercarl.com/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.html)
|
||||
|
||||
那么一直还没有讲空间复杂度,所以打算陆续来补上,内容不难,大家可以读一遍文章就有整体的了解了。
|
||||
|
||||
什么是空间复杂度呢?
|
||||
|
||||
是对一个算法在运行过程中占用内存空间大小的量度,记做$S(n)=O(f(n)$。
|
||||
是对一个算法在运行过程中占用内存空间大小的量度,记做S(n)=O(f(n)。
|
||||
|
||||
空间复杂度(Space Complexity)记作S(n) 依然使用大O来表示。利用程序的空间复杂度,可以对程序运行中需要多少内存有个预先估计。
|
||||
|
||||
@@ -41,11 +41,11 @@ for (int i = 0; i < n; i++) {
|
||||
}
|
||||
|
||||
```
|
||||
第一段代码可以看出,随着n的变化,所需开辟的内存空间并不会随着n的变化而变化。即此算法空间复杂度为一个常量,所以表示为大$O(1)$。
|
||||
第一段代码可以看出,随着n的变化,所需开辟的内存空间并不会随着n的变化而变化。即此算法空间复杂度为一个常量,所以表示为大O(1)。
|
||||
|
||||
什么时候的空间复杂度是$O(n)$?
|
||||
什么时候的空间复杂度是O(n)?
|
||||
|
||||
当消耗空间和输入参数n保持线性增长,这样的空间复杂度为$O(n)$,来看一下这段C++代码
|
||||
当消耗空间和输入参数n保持线性增长,这样的空间复杂度为O(n),来看一下这段C++代码
|
||||
```CPP
|
||||
int* a = new int(n);
|
||||
for (int i = 0; i < n; i++) {
|
||||
@@ -53,9 +53,9 @@ for (int i = 0; i < n; i++) {
|
||||
}
|
||||
```
|
||||
|
||||
我们定义了一个数组出来,这个数组占用的大小为n,虽然有一个for循环,但没有再分配新的空间,因此,这段代码的空间复杂度主要看第一行即可,随着n的增大,开辟的内存大小呈线性增长,即 $O(n)$。
|
||||
我们定义了一个数组出来,这个数组占用的大小为n,虽然有一个for循环,但没有再分配新的空间,因此,这段代码的空间复杂度主要看第一行即可,随着n的增大,开辟的内存大小呈线性增长,即 O(n)。
|
||||
|
||||
其他的 $O(n^2)$, $O(n^3)$ 我想大家应该都可以以此例举出来了,**那么思考一下 什么时候空间复杂度是 $O(\log n)$呢?**
|
||||
其他的 O(n^2), O(n^3) 我想大家应该都可以以此例举出来了,**那么思考一下 什么时候空间复杂度是 O(logn)呢?**
|
||||
|
||||
空间复杂度是logn的情况确实有些特殊,其实是在**递归的时候,会出现空间复杂度为logn的情况**。
|
||||
|
||||
|
||||
@@ -13,7 +13,7 @@
|
||||
|
||||
- 左孩子和右孩子的下标不太好理解。我给出证明过程:
|
||||
|
||||
如果父节点在第$k$层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
|
||||
如果父节点在第k层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
|
||||
|
||||
- 计算父节点在数组中的索引:
|
||||
$$
|
||||
|
||||
@@ -26,7 +26,7 @@ int fibonacci(int i) {
|
||||
|
||||
在讲解递归时间复杂度的时候,我们提到了递归算法的时间复杂度本质上是要看: **递归的次数 * 每次递归的时间复杂度**。
|
||||
|
||||
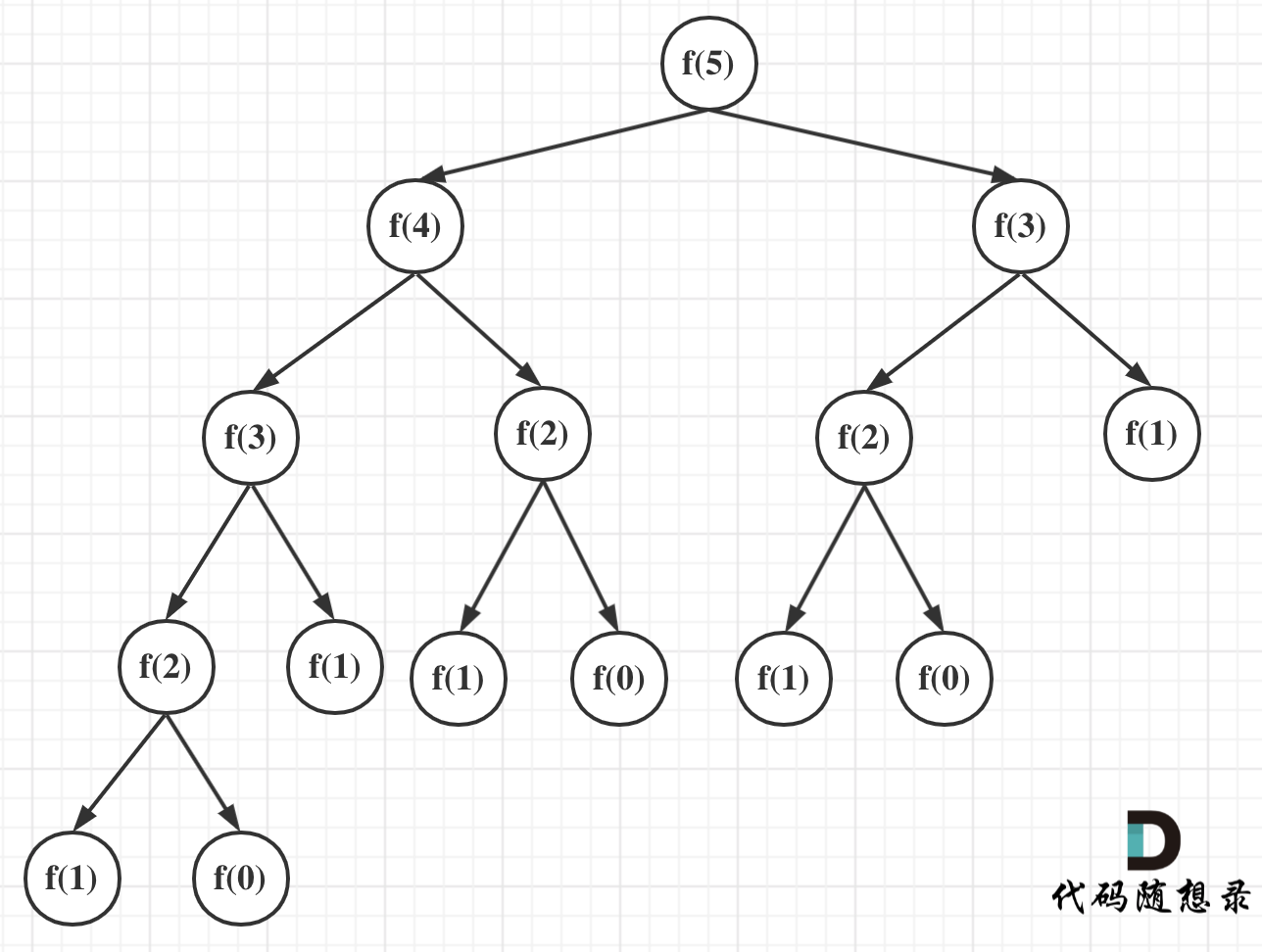
可以看出上面的代码每次递归都是$O(1)$的操作。再来看递归了多少次,这里将i为5作为输入的递归过程 抽象成一棵递归树,如图:
|
||||
可以看出上面的代码每次递归都是O(1)的操作。再来看递归了多少次,这里将i为5作为输入的递归过程 抽象成一棵递归树,如图:
|
||||
|
||||
|
||||
|
||||
@@ -36,7 +36,7 @@ int fibonacci(int i) {
|
||||
|
||||
我们之前也有说到,一棵深度(按根节点深度为1)为k的二叉树最多可以有 2^k - 1 个节点。
|
||||
|
||||
所以该递归算法的时间复杂度为$O(2^n)$,这个复杂度是非常大的,随着n的增大,耗时是指数上升的。
|
||||
所以该递归算法的时间复杂度为O(2^n),这个复杂度是非常大的,随着n的增大,耗时是指数上升的。
|
||||
|
||||
来做一个实验,大家可以有一个直观的感受。
|
||||
|
||||
@@ -85,7 +85,7 @@ int main()
|
||||
* n = 40,耗时:837 ms
|
||||
* n = 50,耗时:110306 ms
|
||||
|
||||
可以看出,$O(2^n)$这种指数级别的复杂度是非常大的。
|
||||
可以看出,O(2^n)这种指数级别的复杂度是非常大的。
|
||||
|
||||
所以这种求斐波那契数的算法看似简洁,其实时间复杂度非常高,一般不推荐这样来实现斐波那契。
|
||||
|
||||
@@ -119,14 +119,14 @@ int fibonacci(int first, int second, int n) {
|
||||
|
||||
这里相当于用first和second来记录当前相加的两个数值,此时就不用两次递归了。
|
||||
|
||||
因为每次递归的时候n减1,即只是递归了n次,所以时间复杂度是 $O(n)$。
|
||||
因为每次递归的时候n减1,即只是递归了n次,所以时间复杂度是 O(n)。
|
||||
|
||||
同理递归的深度依然是n,每次递归所需的空间也是常数,所以空间复杂度依然是$O(n)$。
|
||||
同理递归的深度依然是n,每次递归所需的空间也是常数,所以空间复杂度依然是O(n)。
|
||||
|
||||
代码(版本二)的复杂度如下:
|
||||
|
||||
* 时间复杂度:$O(n)$
|
||||
* 空间复杂度:$O(n)$
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
此时再来测一下耗时情况验证一下:
|
||||
|
||||
@@ -198,7 +198,7 @@ int main()
|
||||
|
||||
递归第n个斐波那契数的话,递归调用栈的深度就是n。
|
||||
|
||||
那么每次递归的空间复杂度是$O(1)$, 调用栈深度为n,所以这段递归代码的空间复杂度就是$O(n)$。
|
||||
那么每次递归的空间复杂度是O(1), 调用栈深度为n,所以这段递归代码的空间复杂度就是O(n)。
|
||||
|
||||
```CPP
|
||||
int fibonacci(int i) {
|
||||
@@ -233,24 +233,24 @@ int binary_search( int arr[], int l, int r, int x) {
|
||||
}
|
||||
```
|
||||
|
||||
都知道二分查找的时间复杂度是$O(\log n)$,那么递归二分查找的空间复杂度是多少呢?
|
||||
都知道二分查找的时间复杂度是O(logn),那么递归二分查找的空间复杂度是多少呢?
|
||||
|
||||
我们依然看 **每次递归的空间复杂度和递归的深度**
|
||||
|
||||
每次递归的空间复杂度可以看出主要就是参数里传入的这个arr数组,但需要注意的是在C/C++中函数传递数组参数,不是整个数组拷贝一份传入函数而是传入的数组首元素地址。
|
||||
|
||||
**也就是说每一层递归都是公用一块数组地址空间的**,所以 每次递归的空间复杂度是常数即:$O(1)$。
|
||||
**也就是说每一层递归都是公用一块数组地址空间的**,所以 每次递归的空间复杂度是常数即:O(1)。
|
||||
|
||||
再来看递归的深度,二分查找的递归深度是logn ,递归深度就是调用栈的长度,那么这段代码的空间复杂度为 $1 * logn = O(logn)$。
|
||||
再来看递归的深度,二分查找的递归深度是logn ,递归深度就是调用栈的长度,那么这段代码的空间复杂度为 1 * logn = O(logn)。
|
||||
|
||||
大家要注意自己所用的语言在传递函数参数的时,是拷贝整个数值还是拷贝地址,如果是拷贝整个数值那么该二分法的空间复杂度就是$O(n\log n)$。
|
||||
大家要注意自己所用的语言在传递函数参数的时,是拷贝整个数值还是拷贝地址,如果是拷贝整个数值那么该二分法的空间复杂度就是O(nlogn)。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
本章我们详细分析了递归实现的求斐波那契和二分法的空间复杂度,同时也对时间复杂度做了分析。
|
||||
|
||||
特别是两种递归实现的求斐波那契数列,其时间复杂度截然不容,我们还做了实验,验证了时间复杂度为$O(2^n)$是非常耗时的。
|
||||
特别是两种递归实现的求斐波那契数列,其时间复杂度截然不容,我们还做了实验,验证了时间复杂度为O(2^n)是非常耗时的。
|
||||
|
||||
通过本篇大家应该对递归算法的时间复杂度和空间复杂度有更加深刻的理解了。
|
||||
|
||||
|
||||
@@ -5,13 +5,13 @@
|
||||
|
||||
相信很多同学对递归算法的时间复杂度都很模糊,那么这篇来给大家通透的讲一讲。
|
||||
|
||||
**同一道题目,同样使用递归算法,有的同学会写出了$O(n)$的代码,有的同学就写出了$O(\log n)$的代码**。
|
||||
**同一道题目,同样使用递归算法,有的同学会写出了O(n)的代码,有的同学就写出了O(logn)的代码**。
|
||||
|
||||
这是为什么呢?
|
||||
|
||||
如果对递归的时间复杂度理解的不够深入的话,就会这样!
|
||||
|
||||
那么我通过一道简单的面试题,模拟面试的场景,来带大家逐步分析递归算法的时间复杂度,最后找出最优解,来看看同样是递归,怎么就写成了$O(n)$的代码。
|
||||
那么我通过一道简单的面试题,模拟面试的场景,来带大家逐步分析递归算法的时间复杂度,最后找出最优解,来看看同样是递归,怎么就写成了O(n)的代码。
|
||||
|
||||
面试题:求x的n次方
|
||||
|
||||
@@ -26,7 +26,7 @@ int function1(int x, int n) {
|
||||
return result;
|
||||
}
|
||||
```
|
||||
时间复杂度为$O(n)$,此时面试官会说,有没有效率更好的算法呢。
|
||||
时间复杂度为O(n),此时面试官会说,有没有效率更好的算法呢。
|
||||
|
||||
**如果此时没有思路,不要说:我不会,我不知道了等等**。
|
||||
|
||||
@@ -44,11 +44,11 @@ int function2(int x, int n) {
|
||||
```
|
||||
面试官问:“那么这个代码的时间复杂度是多少?”。
|
||||
|
||||
一些同学可能一看到递归就想到了$O(\log n)$,其实并不是这样,递归算法的时间复杂度本质上是要看: **递归的次数 * 每次递归中的操作次数**。
|
||||
一些同学可能一看到递归就想到了O(log n),其实并不是这样,递归算法的时间复杂度本质上是要看: **递归的次数 * 每次递归中的操作次数**。
|
||||
|
||||
那再来看代码,这里递归了几次呢?
|
||||
|
||||
每次n-1,递归了n次时间复杂度是$O(n)$,每次进行了一个乘法操作,乘法操作的时间复杂度一个常数项$O(1)$,所以这份代码的时间复杂度是 $n × 1 = O(n)$。
|
||||
每次n-1,递归了n次时间复杂度是O(n),每次进行了一个乘法操作,乘法操作的时间复杂度一个常数项O(1),所以这份代码的时间复杂度是 n × 1 = O(n)。
|
||||
|
||||
这个时间复杂度就没有达到面试官的预期。于是又写出了如下的递归算法的代码:
|
||||
|
||||
@@ -81,11 +81,11 @@ int function3(int x, int n) {
|
||||
|
||||
|
||||
|
||||
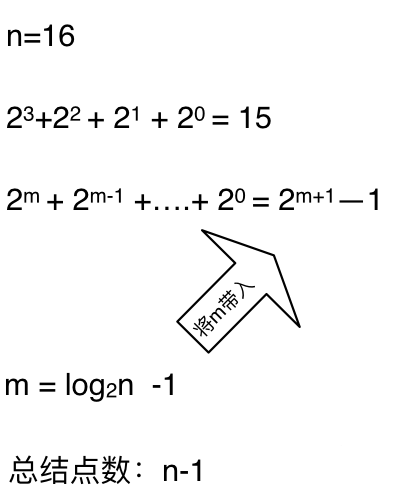
**时间复杂度忽略掉常数项`-1`之后,这个递归算法的时间复杂度依然是$O(n)$**。对,你没看错,依然是$O(n)$的时间复杂度!
|
||||
**时间复杂度忽略掉常数项`-1`之后,这个递归算法的时间复杂度依然是O(n)**。对,你没看错,依然是O(n)的时间复杂度!
|
||||
|
||||
此时面试官就会说:“这个递归的算法依然还是$O(n)$啊”, 很明显没有达到面试官的预期。
|
||||
此时面试官就会说:“这个递归的算法依然还是O(n)啊”, 很明显没有达到面试官的预期。
|
||||
|
||||
那么$O(\log n)$的递归算法应该怎么写呢?
|
||||
那么O(logn)的递归算法应该怎么写呢?
|
||||
|
||||
想一想刚刚给出的那份递归算法的代码,是不是有哪里比较冗余呢,其实有重复计算的部分。
|
||||
|
||||
@@ -108,7 +108,7 @@ int function4(int x, int n) {
|
||||
|
||||
依然还是看他递归了多少次,可以看到这里仅仅有一个递归调用,且每次都是n/2 ,所以这里我们一共调用了log以2为底n的对数次。
|
||||
|
||||
**每次递归了做都是一次乘法操作,这也是一个常数项的操作,那么这个递归算法的时间复杂度才是真正的$O(\log n)$**。
|
||||
**每次递归了做都是一次乘法操作,这也是一个常数项的操作,那么这个递归算法的时间复杂度才是真正的O(logn)**。
|
||||
|
||||
此时大家最后写出了这样的代码并且将时间复杂度分析的非常清晰,相信面试官是比较满意的。
|
||||
|
||||
@@ -116,11 +116,11 @@ int function4(int x, int n) {
|
||||
|
||||
对于递归的时间复杂度,毕竟初学者有时候会迷糊,刷过很多题的老手依然迷糊。
|
||||
|
||||
**本篇我用一道非常简单的面试题目:求x的n次方,来逐步分析递归算法的时间复杂度,注意不要一看到递归就想到了$O(\log n)$!**
|
||||
**本篇我用一道非常简单的面试题目:求x的n次方,来逐步分析递归算法的时间复杂度,注意不要一看到递归就想到了O(logn)!**
|
||||
|
||||
同样使用递归,有的同学可以写出$O(\log n)$的代码,有的同学还可以写出$O(n)$的代码。
|
||||
同样使用递归,有的同学可以写出O(logn)的代码,有的同学还可以写出O(n)的代码。
|
||||
|
||||
对于function3 这样的递归实现,很容易让人感觉这是$O(\log n)$的时间复杂度,其实这是$O(n)$的算法!
|
||||
对于function3 这样的递归实现,很容易让人感觉这是O(log n)的时间复杂度,其实这是O(n)的算法!
|
||||
|
||||
```CPP
|
||||
int function3(int x, int n) {
|
||||
|
||||
Reference in New Issue
Block a user